
SwiReasoning is a decoding-time framework that lets a reasoning LLM determine when to suppose in latent area and when to write express chain-of-thought, utilizing block-wise confidence estimated from entropy traits in next-token distributions. The tactic is training-free, model-agnostic, and targets Pareto-superior accuracy/effectivity trade-offs on arithmetic and STEM benchmarks. Reported outcomes present +1.5%–2.8% common accuracy enhancements with limitless tokens and +56%–79% common token-efficiency positive factors underneath constrained budgets; on AIME’24/’25, it reaches most reasoning accuracy earlier than commonplace CoT.
What SwiReasoning modifications at inference time?
The controller displays the decoder’s next-token entropy to kind a block-wise confidence sign. When confidence is low (entropy trending upward), it enters latent reasoning—the mannequin continues to motive with out emitting tokens. When confidence recovers (entropy trending down), it switches again to express reasoning, emitting CoT tokens to consolidate and decide to a single path. A swap depend management limits the utmost variety of thinking-block transitions to suppress overthinking earlier than finalizing the reply. This dynamic alternation is the core mechanism behind the reported accuracy-per-token positive factors.
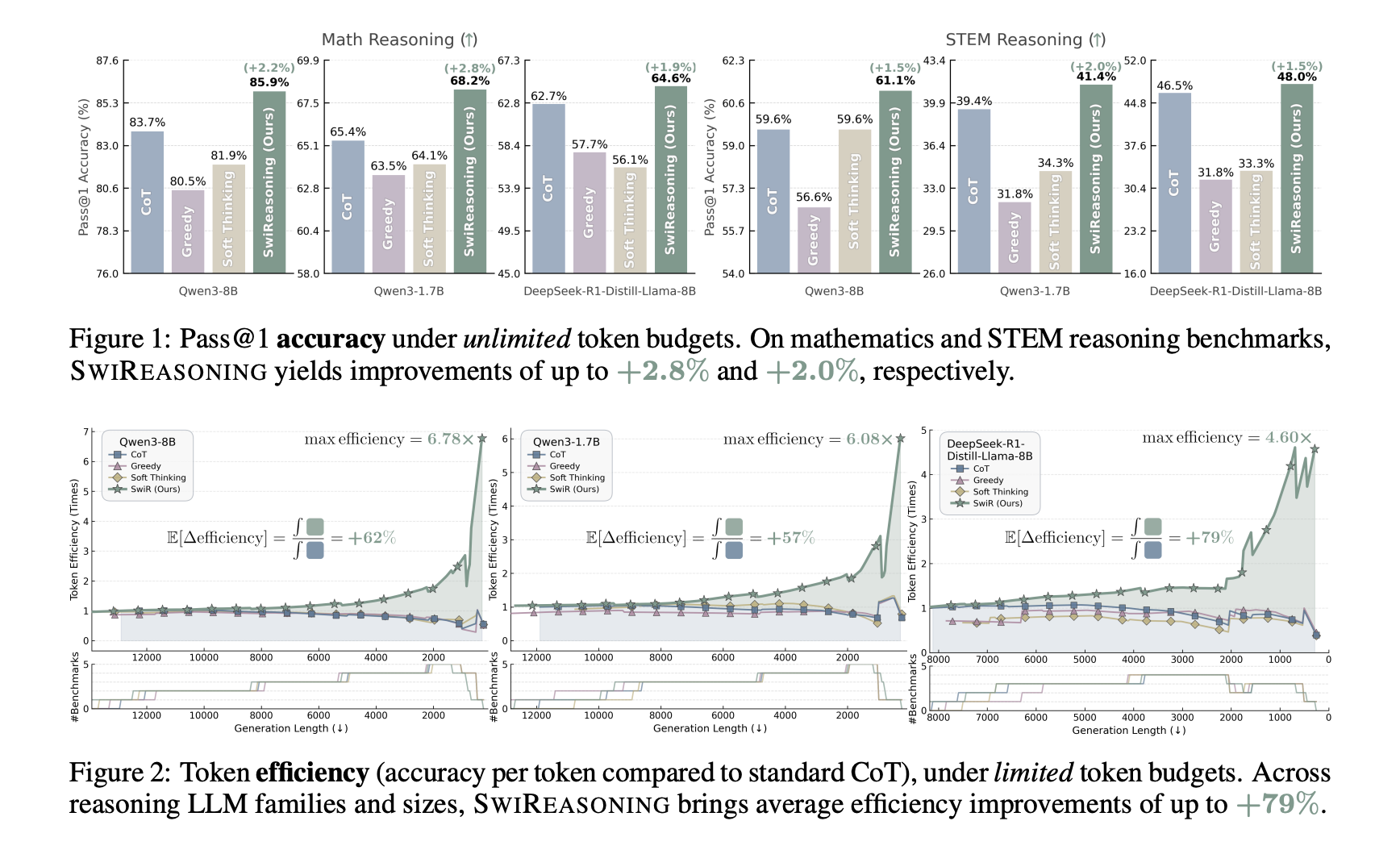
Outcomes: accuracy and effectivity on commonplace suites
It reviews enhancements throughout arithmetic and STEM reasoning duties:
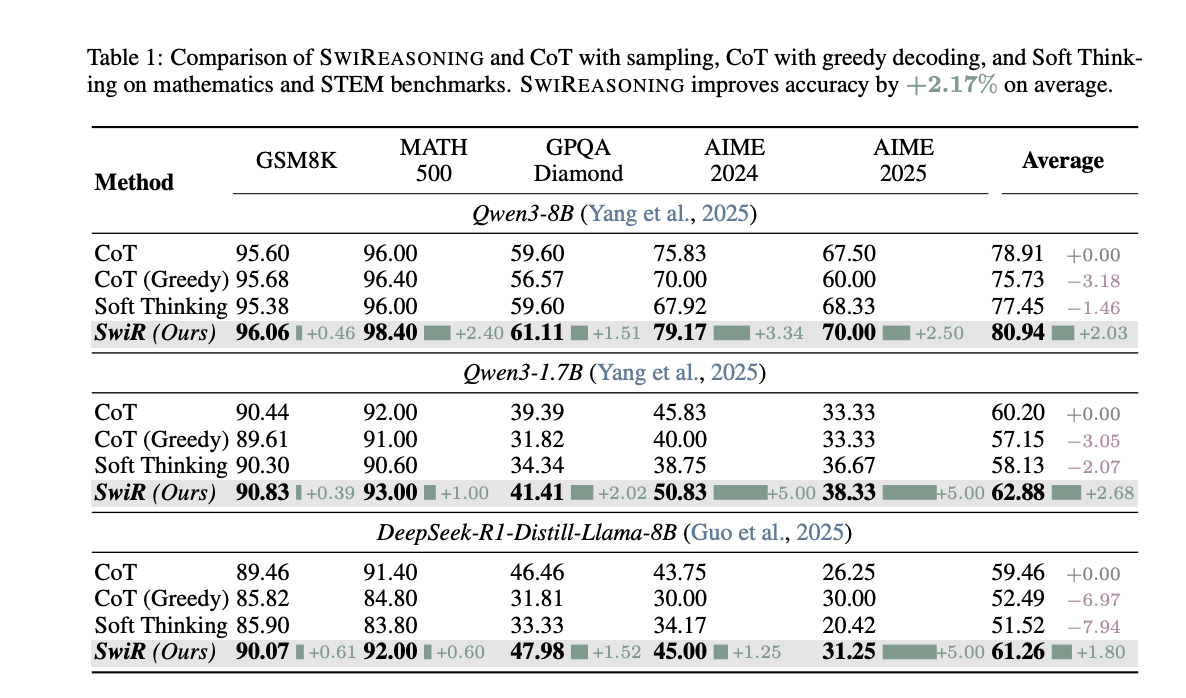
- Go@1 (limitless finances): accuracy lifts as much as +2.8% (math) and +2.0% (STEM) in Determine 1 and Desk 1, with a +2.17% common over baselines (CoT with sampling, CoT grasping, and Tender Considering).
- Token effectivity (restricted budgets): common enhancements as much as +79% (Determine 2). A complete comparability reveals SwiReasoning attains the highest token effectivity in 13/15 evaluations, with an +84% common enchancment over CoT throughout these settings (Determine 4).
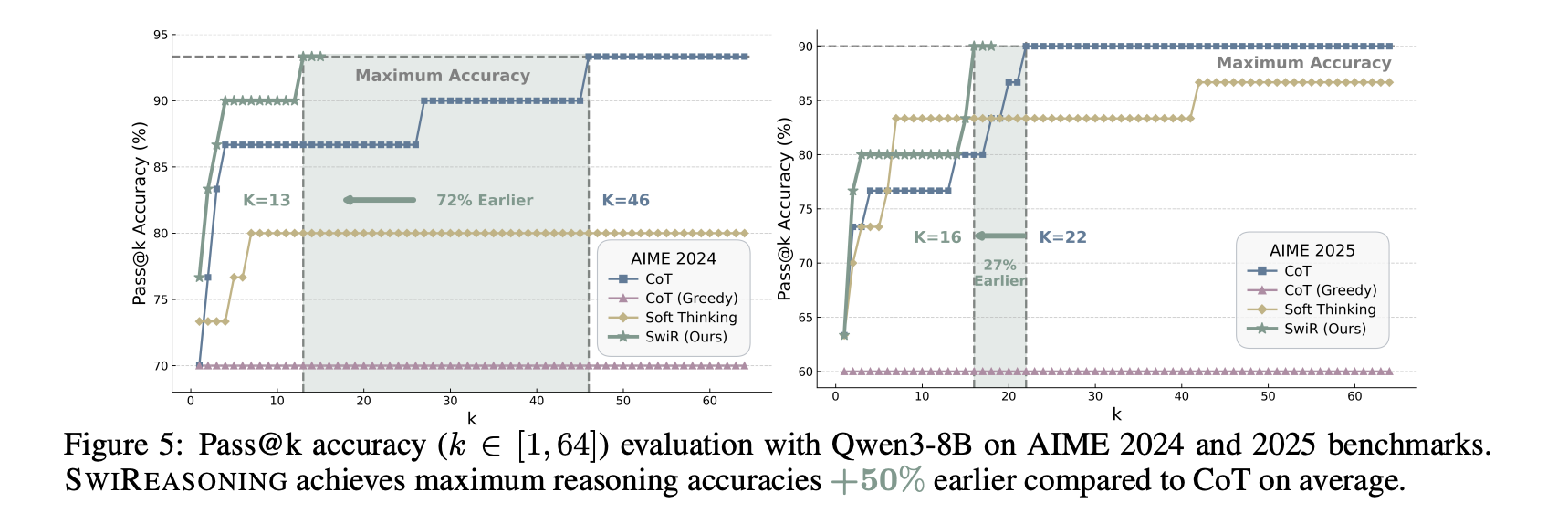
- Go@okay dynamics: with Qwen3-8B on AIME 2024/2025, most reasoning accuracies are achieved +50% earlier than CoT on common (Determine 5), indicating sooner convergence to the ceiling with fewer sampled trajectories.
Why switching helps?
Express CoT is discrete and readable however locks in a single path prematurely, which might discard helpful options. Latent reasoning is steady and information-dense per step, however purely latent methods might diffuse likelihood mass and impede convergence. SwiReasoning provides a confidence-guided alternation: latent phases broaden exploration when the mannequin is unsure; express phases exploit rising confidence to solidify an answer and commit tokens solely when useful. The swap depend management regularizes the method by capping oscillations and limiting extended “silent” wandering—addressing each accuracy loss from diffusion and token waste from overthinking cited as challenges for training-free latent strategies.
Positioning vs. baselines
The challenge compares in opposition to CoT with sampling, CoT grasping, and Tender Considering, reporting a +2.17% common accuracy carry at limitless budgets (Desk 1) and constant efficiency-per-token benefits underneath finances constraints. The visualized Pareto frontier shifts outward—both greater accuracy on the identical finances or related accuracy with fewer tokens—throughout totally different mannequin households and scales. On AIME’24/’25, the Go@okay curves present that SwiReasoning reaches the efficiency ceiling with fewer samples than CoT, reflecting improved convergence habits quite than solely higher uncooked ceilings.
Key Takeaways
- Coaching-free controller: SwiReasoning alternates between latent reasoning and express chain-of-thought utilizing block-wise confidence from next-token entropy traits.
- Effectivity positive factors: Studies +56–79% common token-efficiency enhancements underneath constrained budgets versus CoT, with bigger positive factors as budgets tighten.
- Accuracy lifts: Achieves +1.5–2.8% common Go@1 enhancements on arithmetic/STEM benchmarks at limitless budgets.
- Sooner convergence: On AIME 2024/2025, reaches most reasoning accuracy earlier than CoT (improved Go@okay dynamics).
SwiReasoning is a helpful step towards pragmatic “reasoning coverage” management at decode time: it’s training-free, slots behind the tokenizer, and exposes measurable positive factors on math/STEM suites by toggling between latent and express CoT utilizing an entropy-trend confidence sign with a capped swap depend. The open-source BSD implementation and clear flags (--max_switch_count, --alpha) make replication easy and decrease the barrier to stacking with orthogonal effectivity layers (e.g., quantization, speculative decoding, KV-cache tips). The tactic’s worth proposition is “accuracy per token” quite than uncooked SOTA accuracy, which is operationally essential for budgeted inference and batching.
Take a look at the Paper and Mission Web page. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be part of us on telegram as properly.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}