
How a lot functionality can a sparse 8.3B-parameter MoE with a ~1.5B energetic path ship in your cellphone with out blowing latency or reminiscence? Liquid AI has launched LFM2-8B-A1B, a small-scale Combination-of-Consultants (MoE) mannequin constructed for on-device execution underneath tight reminiscence, latency, and power budgets. In contrast to most MoE work optimized for cloud batch serving, LFM2-8B-A1B targets telephones, laptops, and embedded programs. It showcases 8.3B whole parameters however prompts solely ~1.5B parameters per token, utilizing sparse professional routing to protect a small compute path whereas rising representational capability. The mannequin is launched underneath the LFM Open License v1.0 (lfm1.0)
Understanding the Structure
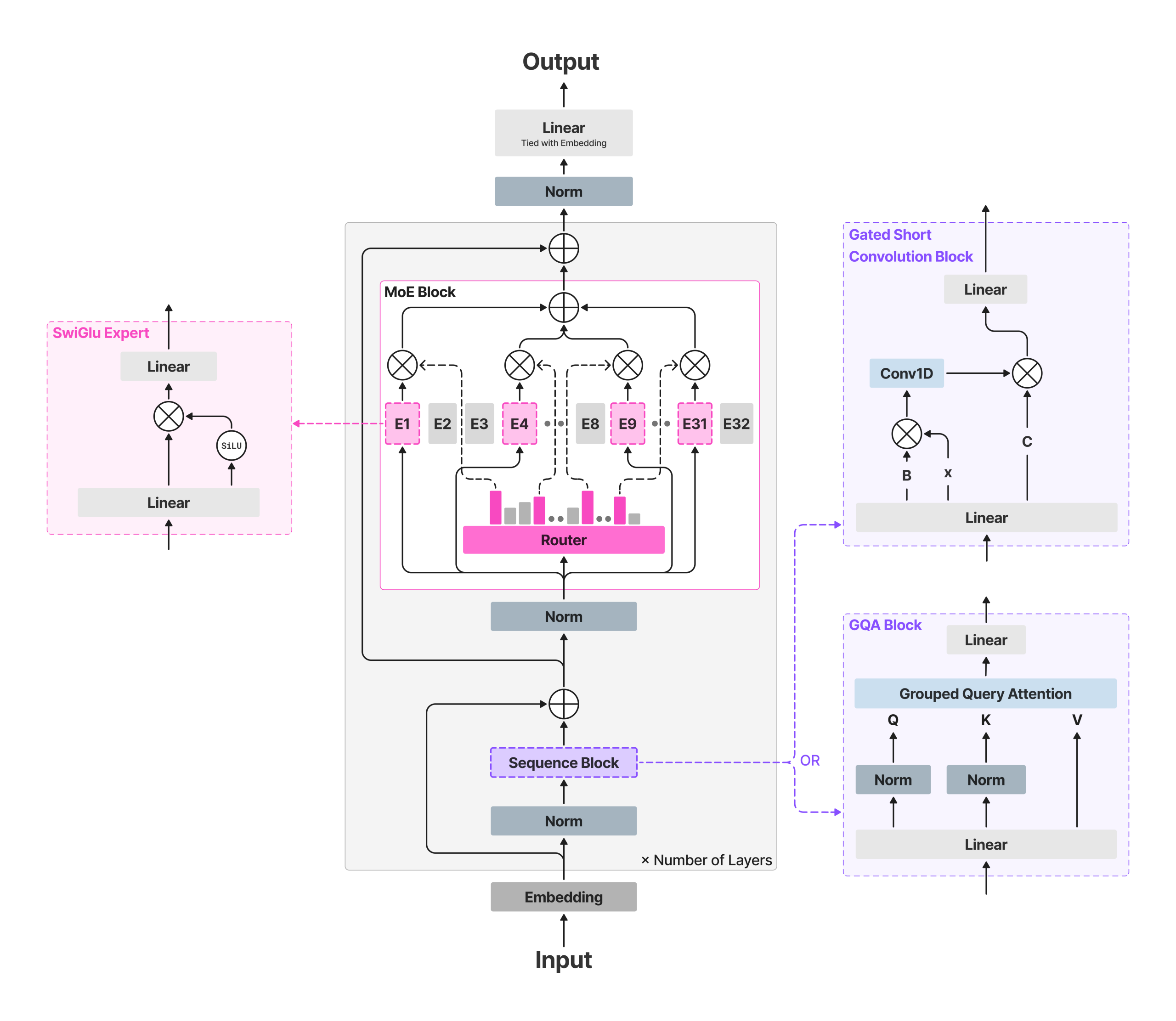
LFM2-8B-A1B retains the LFM2 ‘quick spine’ and inserts sparse-MoE feed-forward blocks to raise capability with out materially rising the energetic compute. The spine makes use of 18 gated short-convolution blocks and 6 grouped-query consideration (GQA) blocks. All layers besides the primary two embody an MoE block; the primary two stay dense for stability. Every MoE block defines 32 specialists; the router selects top-4 specialists per token with a normalized-sigmoid gate and adaptive routing bias to stability load and stabilize coaching. Context size is 32,768 tokens; vocabulary dimension 65,536; reported pre-training finances ~12T tokens.
This method retains per-token FLOPs and cache progress bounded by the energetic path (consideration + 4 professional MLPs), whereas whole capability permits specialization throughout domains reminiscent of multilingual information, math, and code—use circumstances that always regress on very small dense fashions.
Efficiency alerts
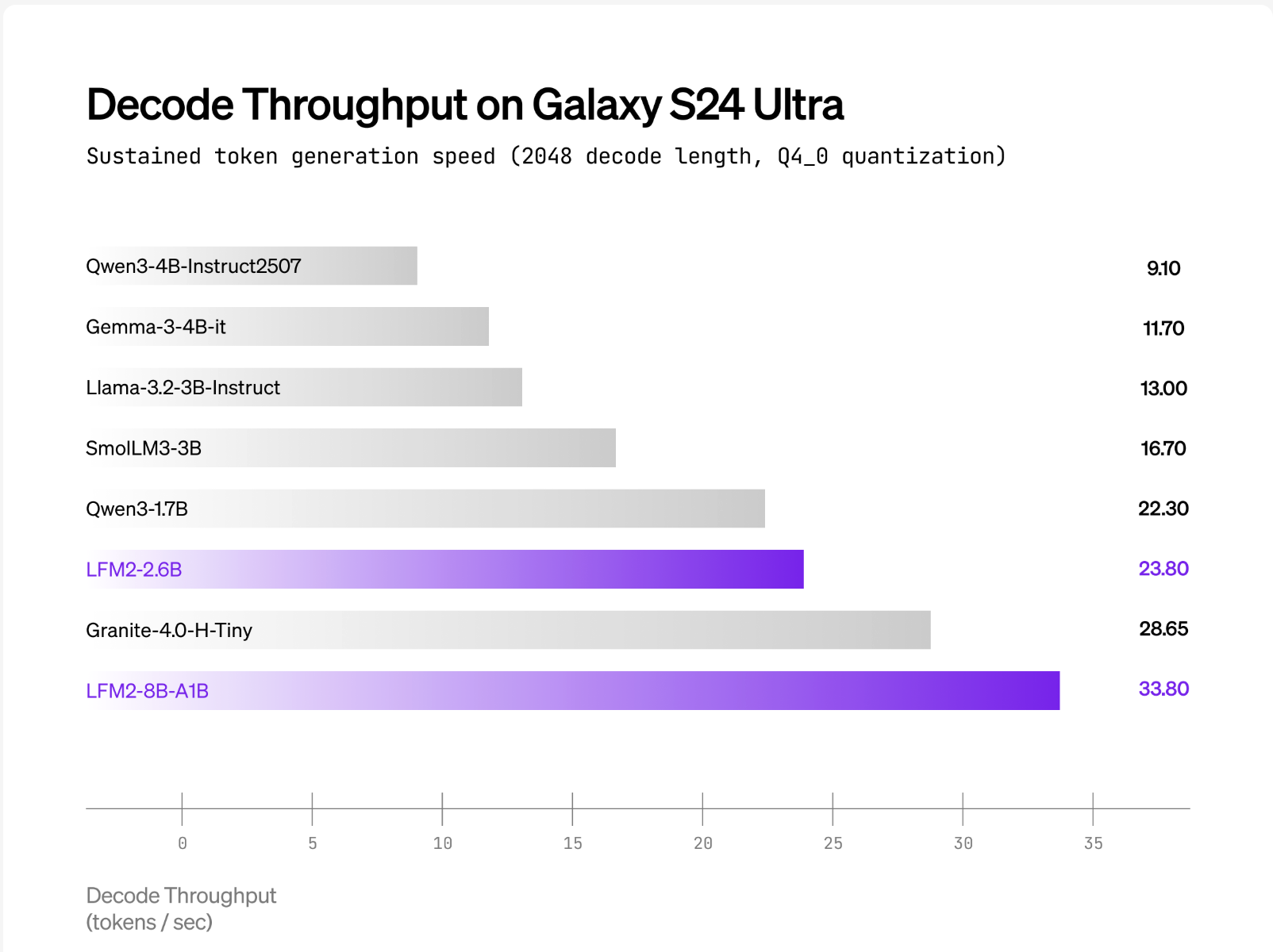
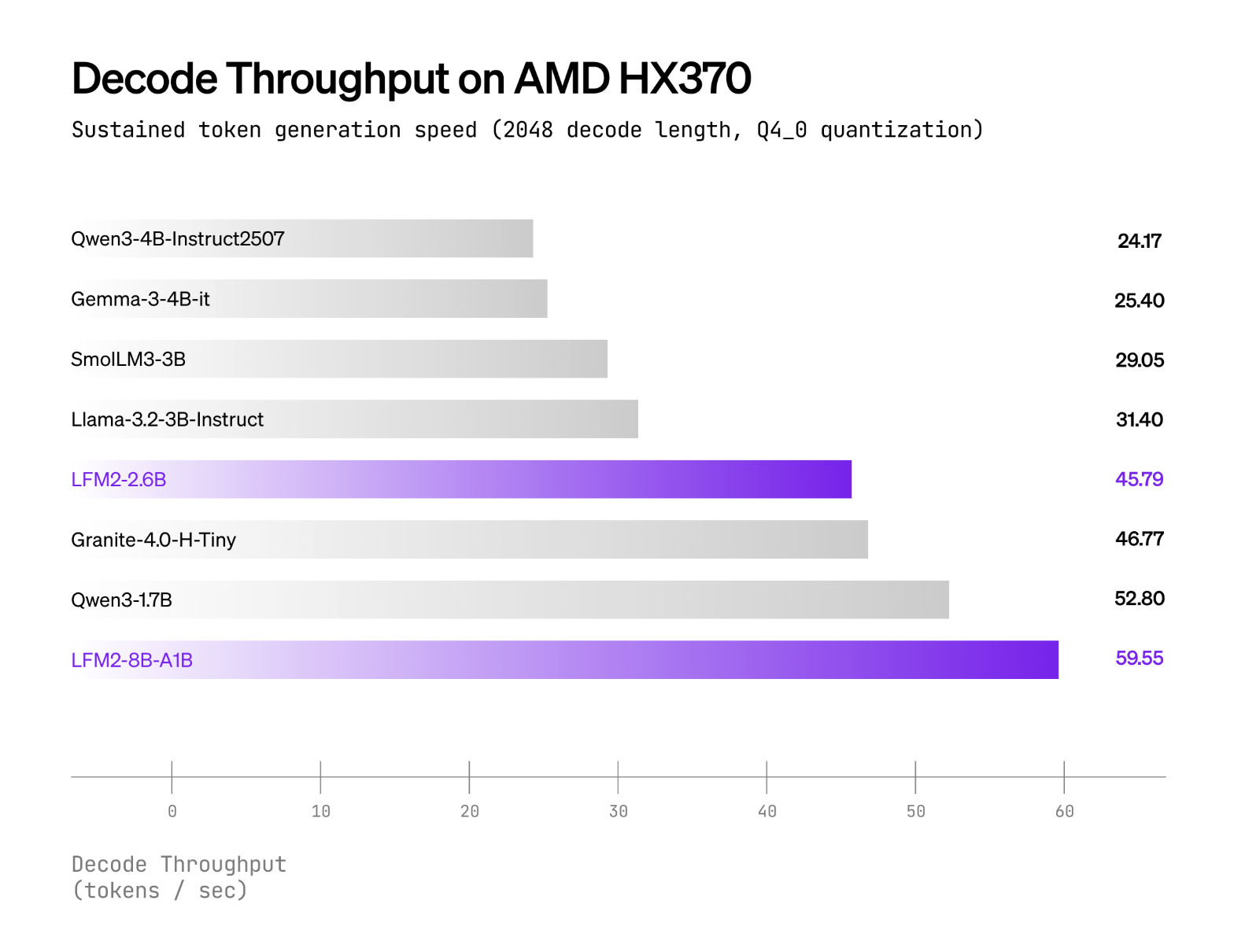
Liquid AI stories that LFM2-8B-A1B runs considerably quicker than Qwen3-1.7B underneath CPU exams utilizing an inner XNNPACK-based stack and a customized CPU MoE kernel. The general public plots cowl int4 quantization with int8 dynamic activations on AMD Ryzen AI 9 HX370 and Samsung Galaxy S24 Extremely. The Liquid AI workforce positions high quality as similar to 3–4B dense fashions, whereas conserving the energetic compute close to 1.5B. No cross-vendor “×-faster” headline multipliers are printed; the claims are framed as per-device comparisons versus equally energetic fashions.
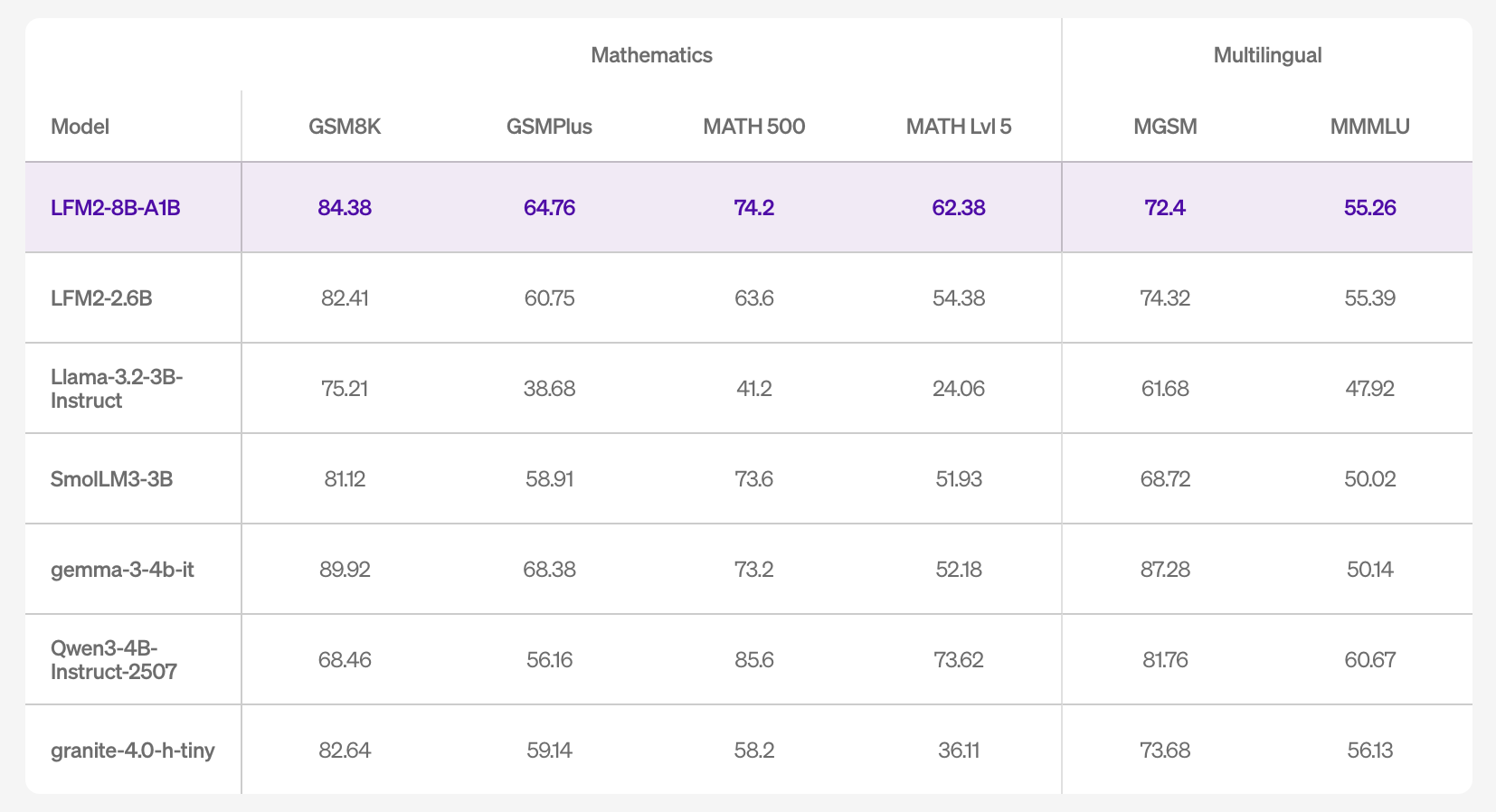
On accuracy, the mannequin card lists outcomes throughout 16 benchmarks, together with MMLU/MMLU-Professional/GPQA (information), IFEval/IFBench/Multi-IF (instruction following), GSM8K/GSMPlus/MATH500/MATH-Lvl-5 (math), and MGSM/MMMLU (multilingual). The numbers point out aggressive instruction-following and math efficiency throughout the small-model band, and improved information capability relative to LFM2-2.6B, per the bigger whole parameter finances.

Deployment and tooling
LFM2-8B-A1B ships with Transformers/vLLM for GPU inference and GGUF builds for llama.cpp; the official GGUF repo lists frequent quants from Q4_0 ≈4.7 GB as much as F16 ≈16.7 GB for native runs, whereas llama.cpp requires a current construct with lfm2moe assist (b6709+) to keep away from “unknown mannequin structure” errors. Liquid’s CPU validation makes use of Q4_0 with int8 dynamic activations on AMD Ryzen AI 9 HX370 and Samsung Galaxy S24 Extremely, the place LFM2-8B-A1B exhibits larger decode throughput than Qwen3-1.7B at an analogous active-parameter class; ExecuTorch is referenced for cellular/embedded CPU deployment.
Key Takeaways
- Structure & routing: LFM2-8B-A1B pairs an LFM2 quick spine (18 gated short-conv blocks + 6 GQA blocks) with per-layer sparse-MoE FFNs (all layers besides the primary two), utilizing 32 specialists with top-4 routing through normalized-sigmoid gating and adaptive biases; 8.3B whole params, ~1.5B energetic per token.
- On-device goal: Designed for telephones, laptops, and embedded CPUs/GPUs; quantized variants “match comfortably” on high-end client {hardware} for personal, low-latency use.
- Efficiency positioning. Liquid stories LFM2-8B-A1B is considerably quicker than Qwen3-1.7B in CPU exams and goals for 3–4B dense-class high quality whereas conserving an ~1.5B energetic path.
LFM2-8B-A1B demonstrates that sparse MoE may be sensible beneath the standard server-scale regime. The mannequin combines an LFM2 conv-attention spine with per-layer professional MLPs (besides the primary two layers) to maintain token compute close to 1.5B whereas lifting high quality towards 3–4B dense courses. With customary and GGUF weights, llama.cpp/ExecuTorch/vLLM paths, and a permissive on-device posture, LFM2-8B-A1B is a concrete choice for constructing low-latency, personal assistants and application-embedded copilots on client and edge {hardware}.
Try the Mannequin on Hugging Face and Technical particulars. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be part of us on telegram as effectively.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}