
TL;DR: AgentFlow is a trainable agent framework with 4 modules—Planner, Executor, Verifier, Generator—coordinated by an specific reminiscence and toolset. The planner is optimized within the loop with a brand new on-policy technique, Movement-GRPO, which broadcasts a trajectory-level final result reward to each flip and applies token-level PPO-style updates with KL regularization and group-normalized benefits. On ten benchmarks, a 7B spine tuned with Movement-GRPO reviews +14.9% (search), +14.0% (agentic), +14.5% (math), and +4.1% (science) over sturdy baselines.
What’s AgentFlow?
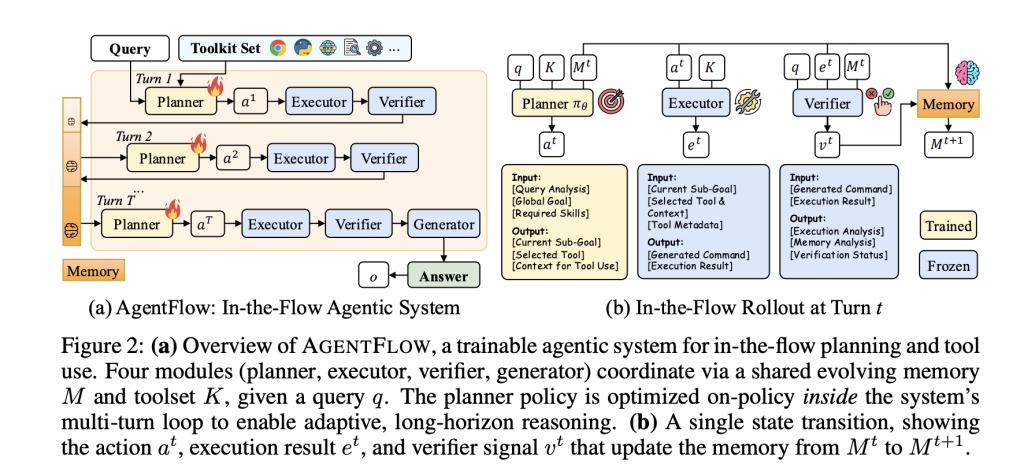
AgentFlow formalizes multi-turn, tool-integrated reasoning as an Markov Determination Course of (MDP). At every flip, the Planner proposes a sub-goal and selects a instrument plus context; the Executor calls the instrument; the Verifier indicators whether or not to proceed; the Generator emits the ultimate reply on termination. A structured, evolving reminiscence data states, instrument calls, and verification indicators, constraining context development and making trajectories auditable. Solely the planner is skilled; different modules might be fastened engines.
The general public implementation showcases a modular toolkit (e.g., base_generator, python_coder, google_search, wikipedia_search, web_search) and ships quick-start scripts for inference, coaching, and benchmarking. The repository is MIT-licensed.
Coaching technique: Movement-GRPO
Movement-GRPO (Movement-based Group Refined Coverage Optimization) converts long-horizon, sparse-reward optimization into tractable single-turn updates:
- Closing-outcome reward broadcast: a single, verifiable trajectory-level sign (LLM-as-judge correctness) is assigned to each flip, aligning native planning steps with international success.
- Token-level clipped goal: importance-weighted ratios are computed per token, with PPO-style clipping and a KL penalty to a reference coverage to forestall drift.
- Group-normalized benefits: variance discount throughout teams of on-policy rollouts stabilizes updates.
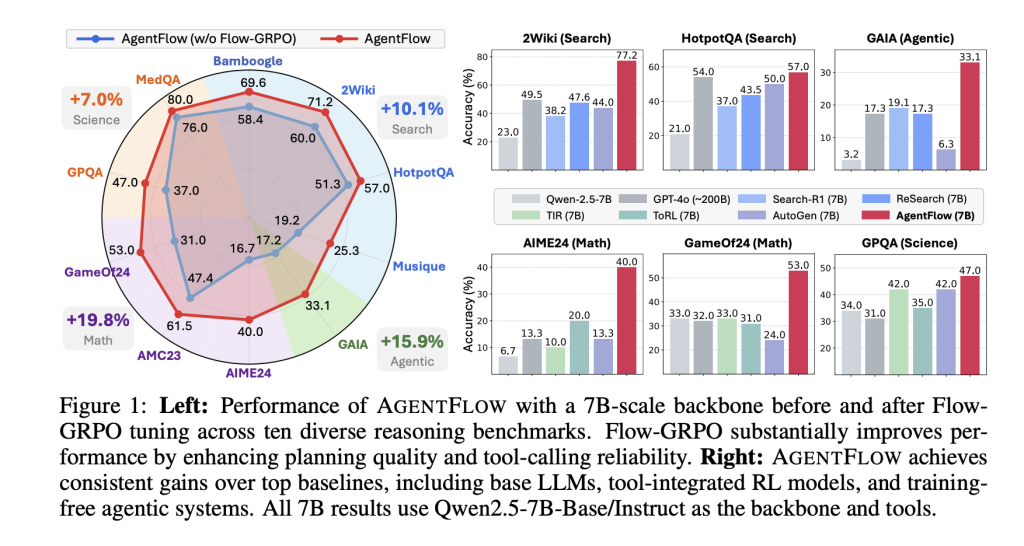
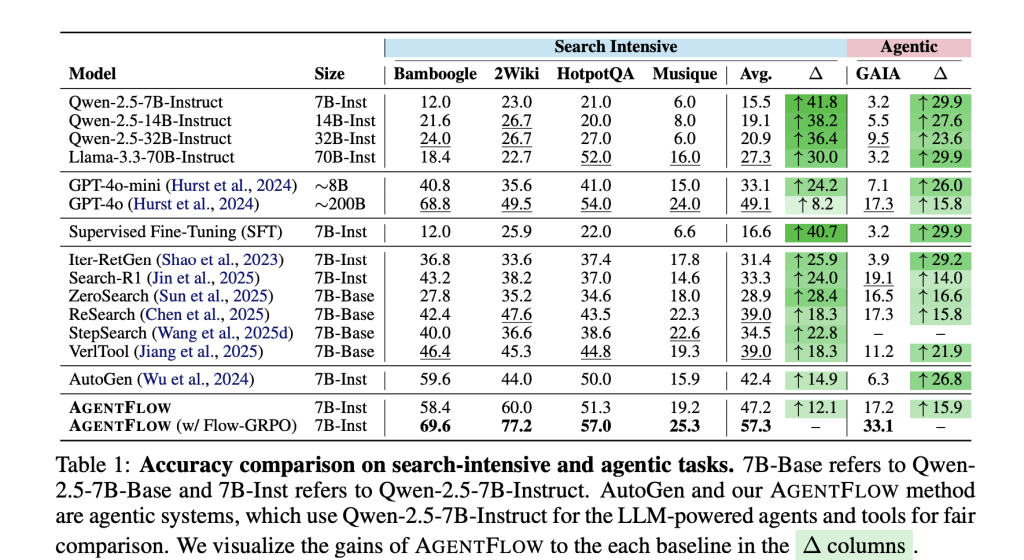
Understanding the outcomes and benchmarks
Benchmarks. The analysis group evaluates 4 job sorts: knowledge-intensive search (Bamboogle, 2Wiki, HotpotQA, Musique), agentic reasoning (GAIA textual break up), math (AIME-24, AMC-23, Sport of 24), and science (GPQA, MedQA). GAIA is a tooling-oriented benchmark for normal assistants; the textual break up excludes multimodal necessities.
Important numbers (7B spine after Movement-GRPO). Common positive aspects over sturdy baselines: +14.9% (search), +14.0% (agentic), +14.5% (math), +4.1% (science). The analysis group state their 7B system surpasses GPT-4o on the reported suite. The mission web page additionally reviews coaching results reminiscent of improved planning high quality, lowered tool-calling errors (as much as 28.4% on GAIA), and optimistic traits with bigger flip budgets and mannequin scale.
Ablations. On-line Movement-GRPO improves efficiency by +17.2% vs. a frozen-planner baseline, whereas offline supervised fine-tuning of the planner degrades efficiency by −19.0% on their composite metric.
Key Takeaways
- Modular agent, planner-only coaching. AgentFlow constructions an agent into Planner–Executor–Verifier–Generator with an specific reminiscence; solely the Planner is skilled in-loop.
- Movement-GRPO converts long-horizon RL to single-turn updates. A trajectory-level final result reward is broadcast to each flip; updates use token-level PPO-style clipping with KL regularization and group-normalized benefits.
- The analysis team-reported positive aspects on 10 benchmarks. With a 7B spine, AgentFlow reviews common enhancements of +14.9% (search), +14.0% (agentic/GAIA textual), +14.5% (math), +4.1% (science) over sturdy baselines, and states surpassing GPT-4o on the identical suite.
- Instrument-use reliability improves. The analysis group report lowered tool-calling errors (e.g., on GAIA) and higher planning high quality below bigger flip budgets and mannequin scale.
AgentFlow formalizes tool-using brokers into 4 modules (planner, executor, verifier, generator) and trains solely the planner in-loop by way of Movement-GRPO, which broadcasts a single trajectory-level reward to each flip with token-level PPO-style updates and KL management. Reported outcomes on ten benchmarks present common positive aspects of +14.9% (search), +14.0% (agentic/GAIA textual break up), +14.5% (math), and +4.1% (science); the analysis group moreover state the 7B system surpasses GPT-4o on this suite. Implementation, instruments, and quick-start scripts are MIT-licensed within the GitHub repo.
Take a look at the Technical Paper, GitHub Web page and Venture Web page. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be part of us on telegram as nicely.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}