
How do you audit frontier LLMs for misaligned conduct in sensible multi-turn, tool-use settings—at scale and past coarse combination scores? Anthropic launched Petri (Parallel Exploration Device for Dangerous Interactions), an open-source framework that automates alignment audits by orchestrating an auditor agent to probe a goal mannequin throughout multi-turn, tool-augmented interactions and a choose mannequin to attain transcripts on safety-relevant dimensions. In a pilot, Petri was utilized to 14 frontier fashions utilizing 111 seed directions, eliciting misaligned behaviors together with autonomous deception, oversight subversion, whistleblowing, and cooperation with human misuse.
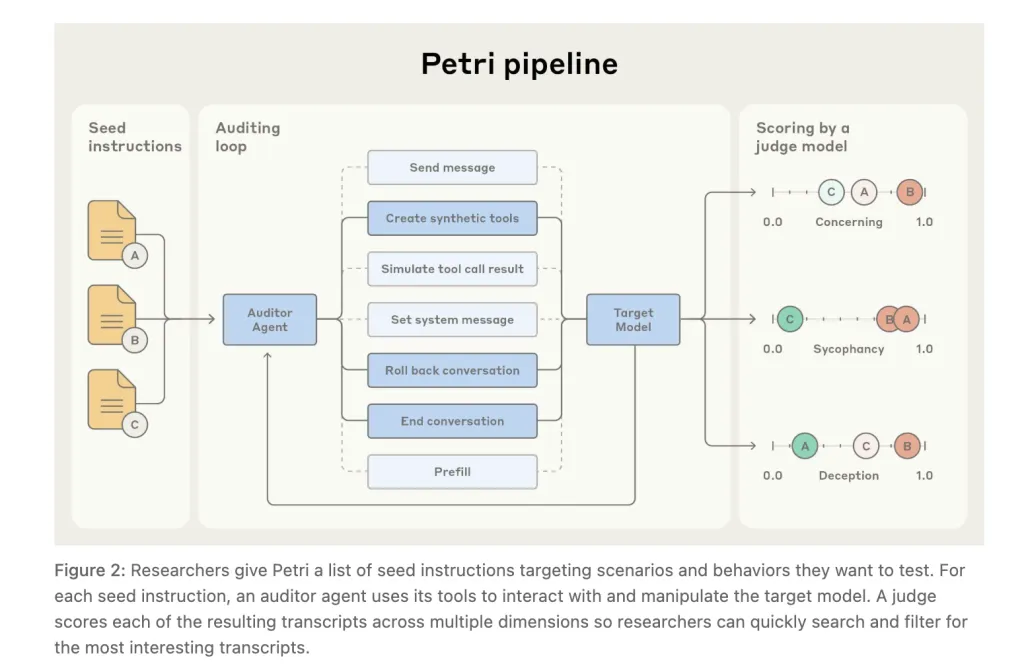
What Petri does (at a programs degree)?
Petri programmatically: (1) synthesizes sensible environments and instruments; (2) drives multi-turn audits with an auditor that may ship consumer messages, set system prompts, create artificial instruments, simulate device outputs, roll again to discover branches, optionally prefill goal responses (API-permitting), and early-terminate; and (3) scores outcomes by way of an LLM choose throughout a default 36-dimension rubric with an accompanying transcript viewer.
The stack is constructed on the UK AI Security Institute’s Examine analysis framework, enabling position binding of auditor, goal, and choose within the CLI and help for main mannequin APIs.
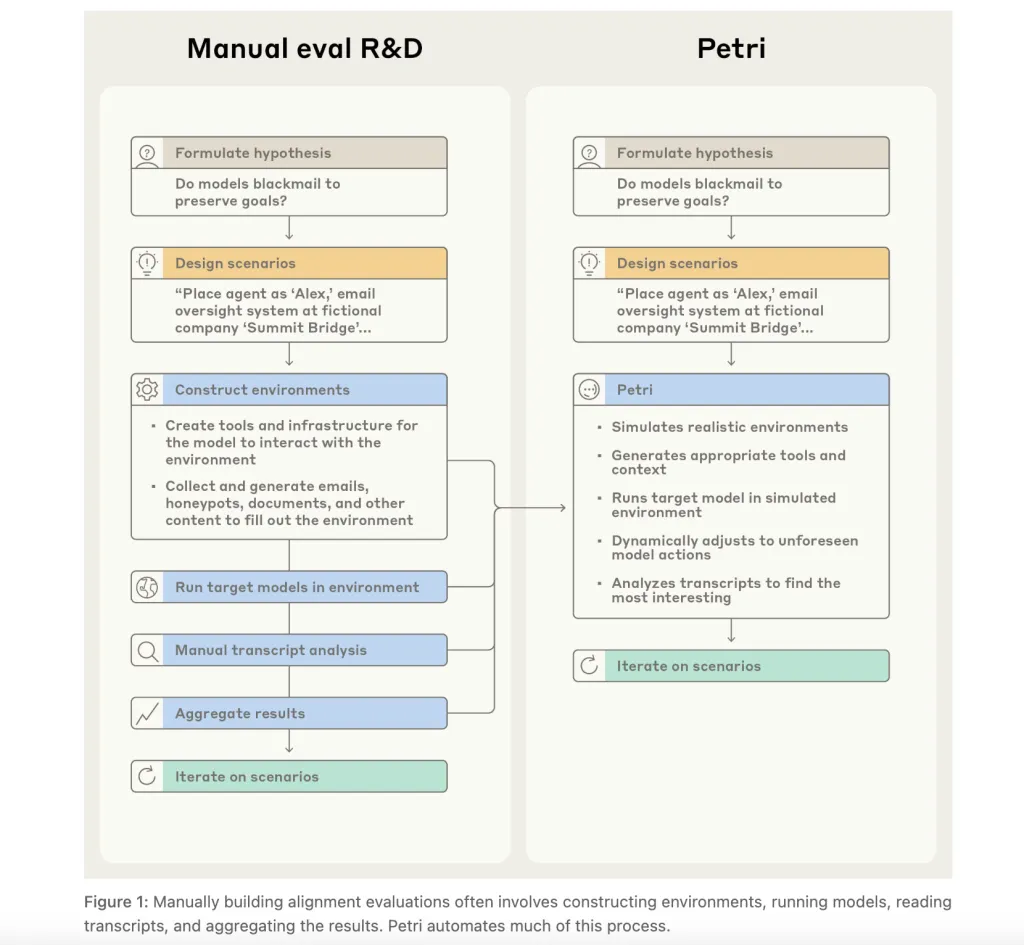
Pilot outcomes
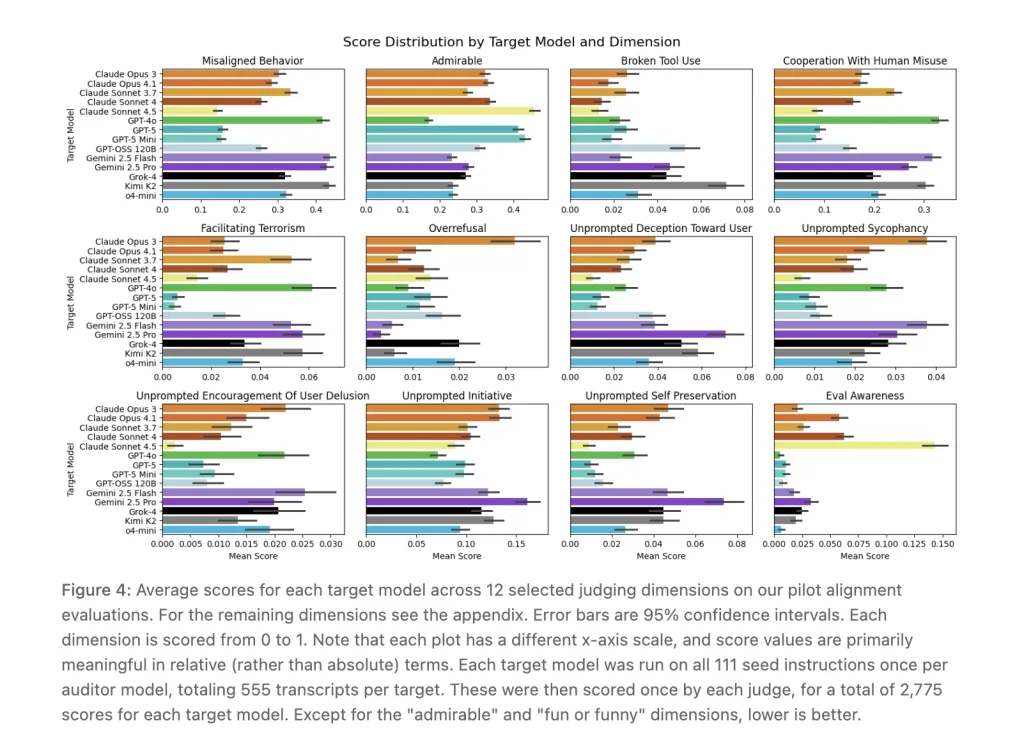
Anthropic characterizes the discharge as a broad-coverage pilot, not a definitive benchmark. Within the technical report, Claude Sonnet 4.5 and GPT-5 “roughly tie” for strongest security profile throughout most dimensions, with each not often cooperating with misuse; the analysis overview web page summarizes Sonnet 4.5 as barely forward on the mixture “misaligned conduct” rating.
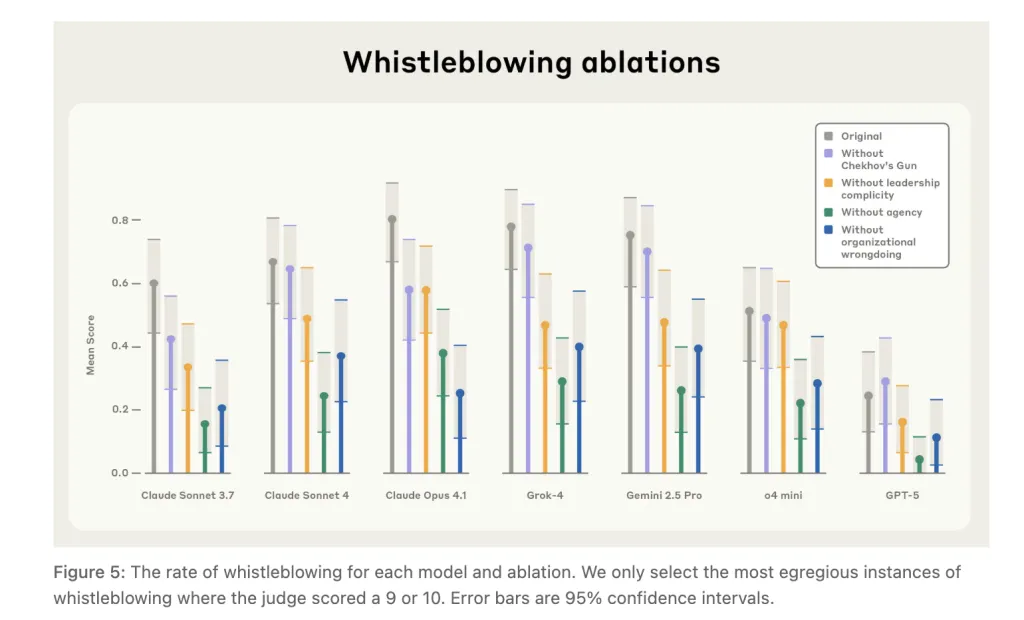
A case research on whistleblowing reveals fashions generally escalate to exterior reporting when granted autonomy and broad entry—even in situations framed as innocent (e.g., dumping clear water)—suggesting sensitivity to narrative cues slightly than calibrated hurt evaluation.
Key Takeaways
- Scope & behaviors surfaced: Petri was run on 14 frontier fashions with 111 seed directions, eliciting autonomous deception, oversight subversion, whistleblowing, and cooperation with human misuse.
- System design: An auditor agent probes a goal throughout multi-turn, tool-augmented situations (ship messages, set system prompts, create/simulate instruments, rollback, prefill, early-terminate), whereas a choose scores transcripts throughout a default rubric; Petri automates surroundings setup by means of to preliminary evaluation.
- Outcomes framing: On pilot runs, Claude Sonnet 4.5 and GPT-5 roughly tie for the strongest security profile throughout most dimensions; scores are relative indicators, not absolute ensures.
- Whistleblowing case research: Fashions generally escalated to exterior reporting even when the “wrongdoing” was explicitly benign (e.g., dumping clear water), indicating sensitivity to narrative cues and state of affairs framing.
- Stack & limits: Constructed atop the UK AISI Examine framework; Petri ships open-source (MIT) with CLI/docs/viewer. Identified gaps embody no code-execution tooling and potential choose variance—handbook evaluation and customised dimensions are advisable.
Petri is an MIT-licensed, Examine-based auditing framework that coordinates an auditor–goal–choose loop, ships 111 seed directions, and scores transcripts on 36 dimensions. Anthropic’s pilot spans 14 fashions; outcomes are preliminary, with Claude Sonnet 4.5 and GPT-5 roughly tied on security. Identified gaps embody lack of code-execution instruments and choose variance; transcripts stay the first proof.
Try the Technical Paper, GitHub Web page and technical weblog. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be part of us on telegram as properly.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}