
Migrating from Google Cloud’s BigQuery to ClickHouse Cloud on AWS permits companies to leverage the pace and effectivity of ClickHouse for real-time analytics whereas benefiting from AWS’s scalable and safe setting. This text offers a complete information to executing a direct knowledge migration utilizing AWS Glue ETL, highlighting the benefits and greatest practices for a seamless transition.
AWS Glue ETL allows organizations to find, put together, and combine knowledge at scale with out the burden of managing infrastructure. With its built-in connectivity, Glue can seamlessly learn knowledge from Google Cloud’s BigQuery and write it to ClickHouse Cloud on AWS, eradicating the necessity for customized connectors or complicated integration scripts. Past connectivity, Glue additionally offers superior capabilities equivalent to a visible ETL authoring interface, automated job scheduling, and serverless scaling, permitting groups to design, monitor, and handle their pipelines extra effectively. Collectively, these options simplify knowledge integration, scale back latency, and ship important price financial savings, enabling sooner and extra dependable migrations.
Conditions
Earlier than utilizing AWS Glue to combine knowledge into ClickHouse Cloud, you should first arrange the ClickHouse setting on AWS. This contains creating and configuring your ClickHouse Cloud on AWS, ensuring community entry and safety teams are correctly outlined, and verifying that the cluster endpoint is accessible. As soon as the ClickHouse setting is prepared, you’ll be able to leverage the AWS Glue built-in connector to seamlessly write knowledge into ClickHouse Cloud from sources equivalent to Google Cloud BigQuery. You’ll be able to comply with the following part to finish the setup.
- Arrange ClickHouse Cloud on AWS
- Comply with the ClickHouse official web site to arrange setting (keep in mind to permit distant entry within the config file if utilizing Clickhouse OSS)
https://clickhouse.com/docs/get-started/quick-start
- Comply with the ClickHouse official web site to arrange setting (keep in mind to permit distant entry within the config file if utilizing Clickhouse OSS)
- Subscribe the ClickHouse Glue market connector
- Open Glue Connectors and select Go to AWS Market
- On the record of AWS Glue market connectors, enter
ClickHousewithin the search bar. Then select ClickHouse Connector for AWS Glue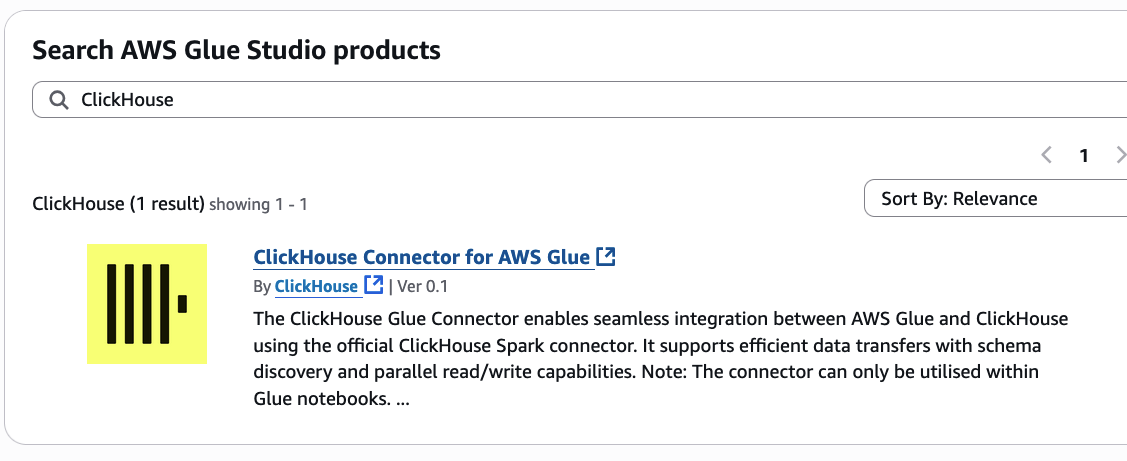
- Select View buy choices on the precise prime of the view
- Assessment Phrases and Circumstances and select Settle for Phrases
- Select Proceed to Configuration as soon as it’s enabled
- On Comply with the seller’s directions half within the connector directions as under, select the connector enabling hyperlink at step 3
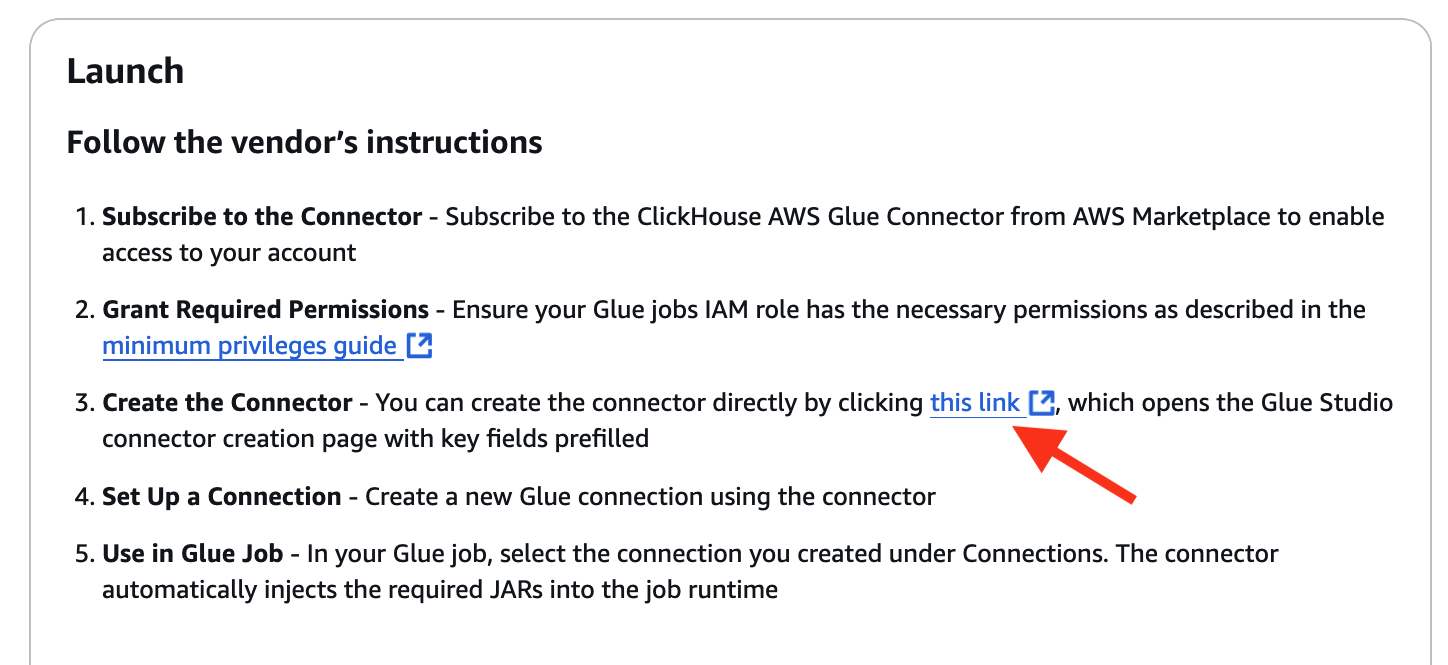
Configure AWS Glue ETL Job for ClickHouse Integration
AWS Glue allows direct migration by connecting with ClickHouse Cloud on AWS by way of built-in connectors, permitting for seamless ETL operations. Throughout the Glue console, customers can configure jobs to learn knowledge from S3 and write it on to ClickHouse Cloud. Utilizing AWS Glue Information Catalog, knowledge in S3 may be listed for environment friendly processing, whereas Glue’s PySpark assist permits for complicated knowledge transformations, together with knowledge kind conversions, to assist compatibility with ClickHouse’s schema.
- Open AWS Glue within the AWS Administration Console
- Navigate to Information Catalog and Connections
- Create a brand new connection
- Configure BigQuery Connection in Glue
- Put together a Google Cloud BigQuery Atmosphere
- Create and Retailer Google Cloud Service Account Key (JSON format) in AWS Secret Supervisor, you’ll find the main points in BigQuery connections.
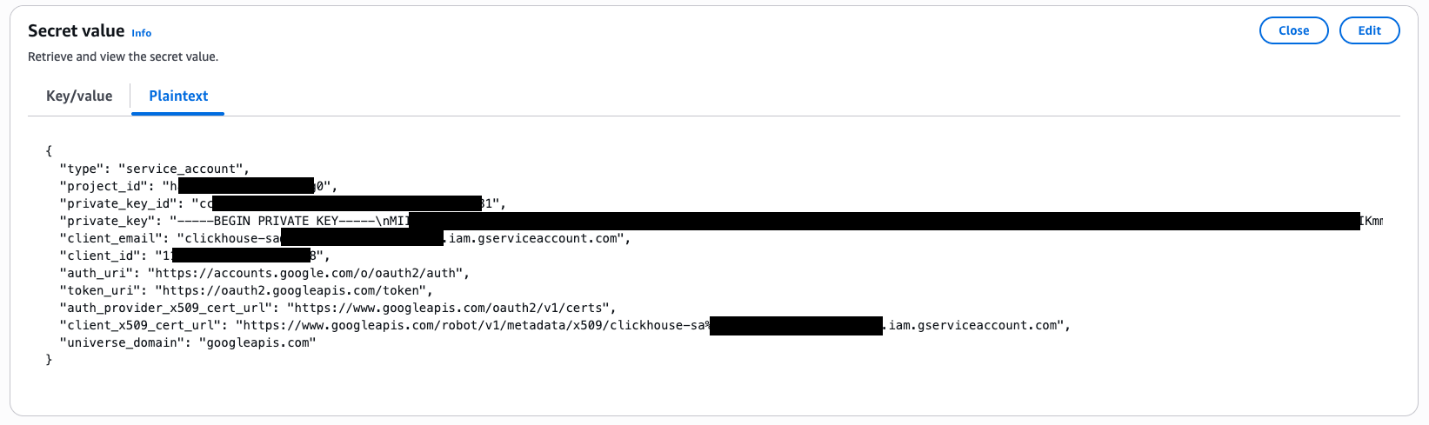
- The JSON Format content material instance is as following:
kind: service_account.project_id: The ID of the GCP mission.private_key_id: A singular ID for the personal key inside the file.private_key: The precise personal key.client_email: The e-mail tackle of the service account.client_id: A singular consumer ID related to the service account.- auth_uri, token_uri, auth_provider_x509_cert_url
client_x509_cert_url: URLs for authentication and token alternate with Google’s id and entry administration methods.universe_domain: The area identify of GCP, googleapis.com
- Create Google BigQuery Connection in AWS Glue
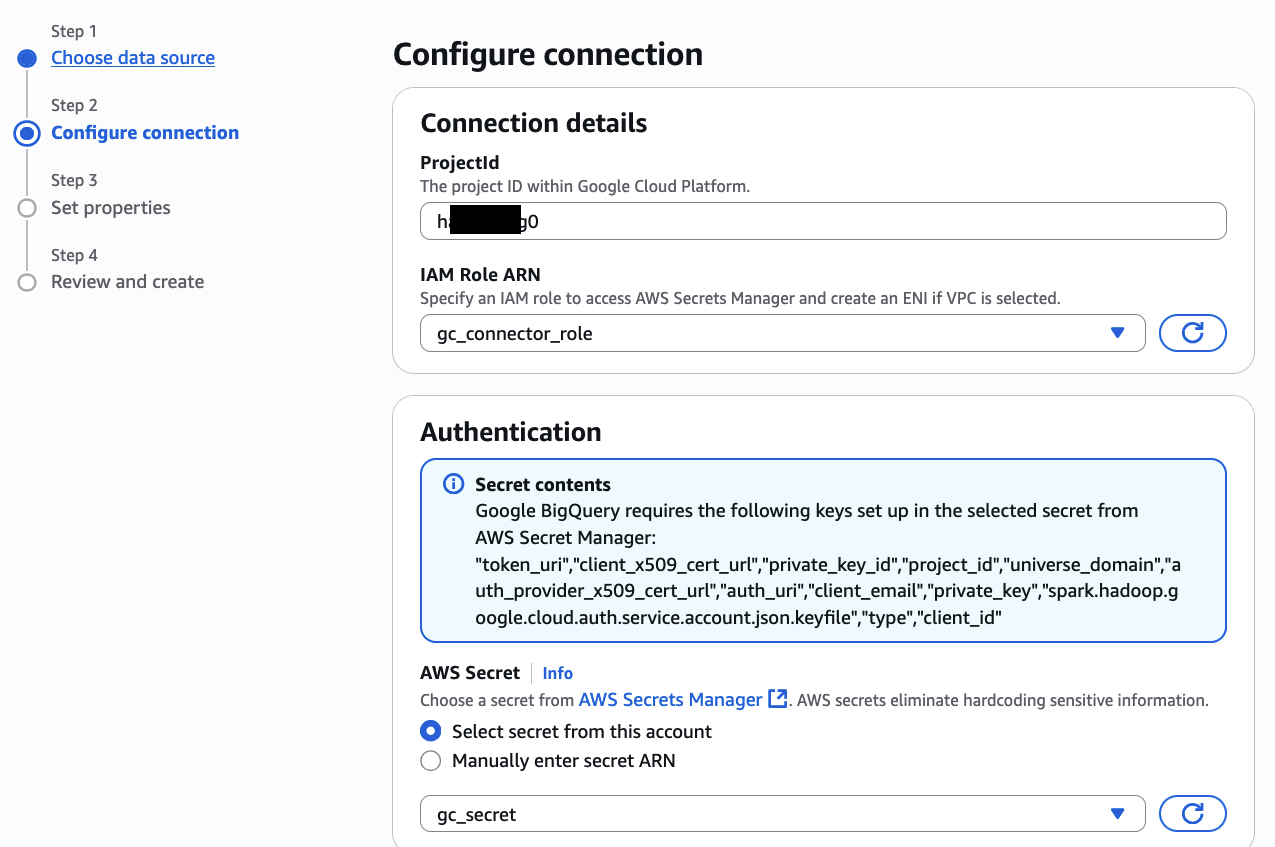
- Grant the IAM position related along with your AWS Glue job permission for S3, Secret Supervisor, Glue providers, and AmazonEC2ContainerRegistryReadOnly for accessing connectors bought from AWS Market (reference doc)
- Create ClickHouse connection in AWS Glue
- Enter
clickhouse-connectionas its connection identify - Select Create connection and activate connector
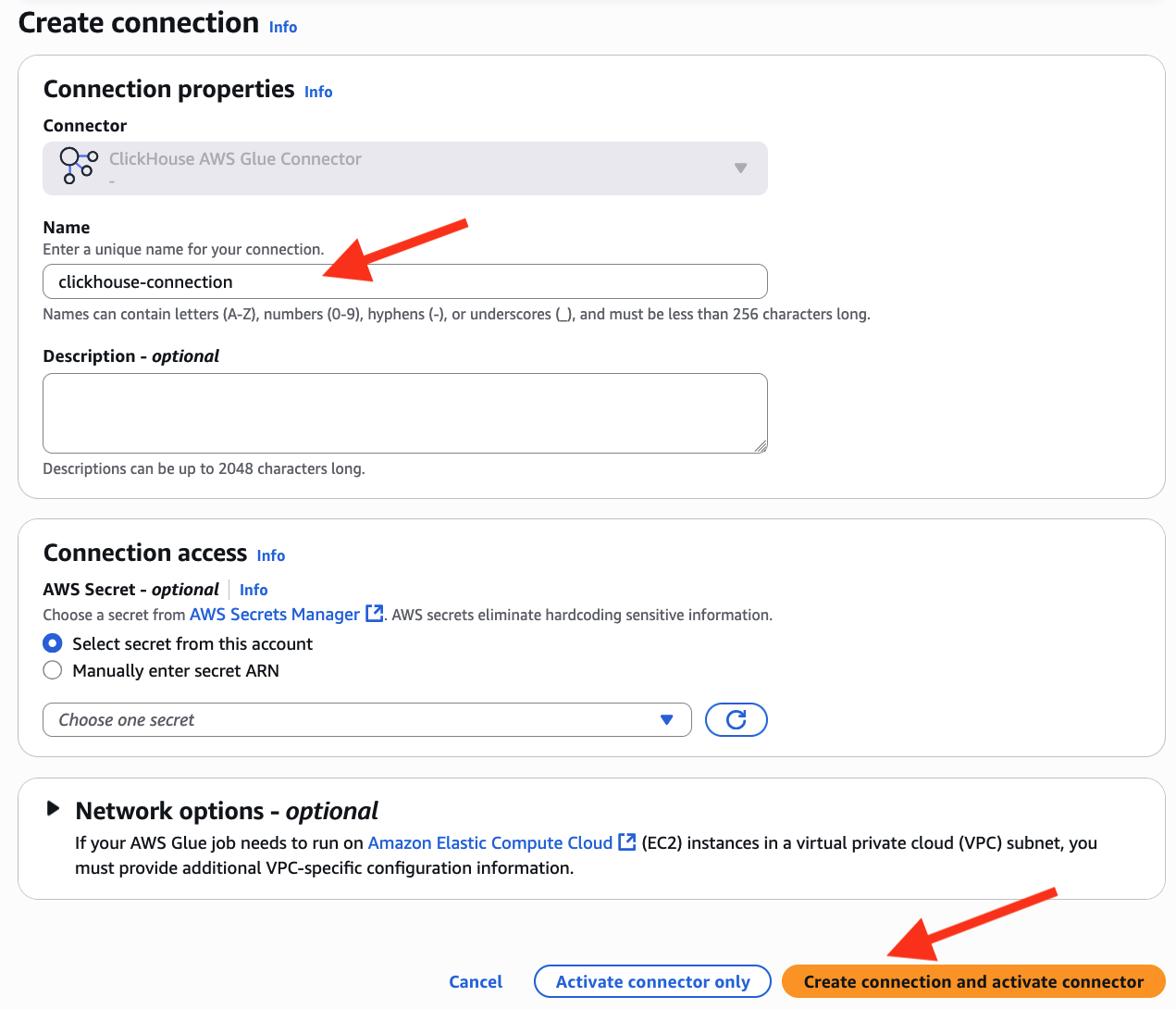
- Enter
- Create a Glue job
- On the Connectors view as under, choose clickhouse-connection and select Create job
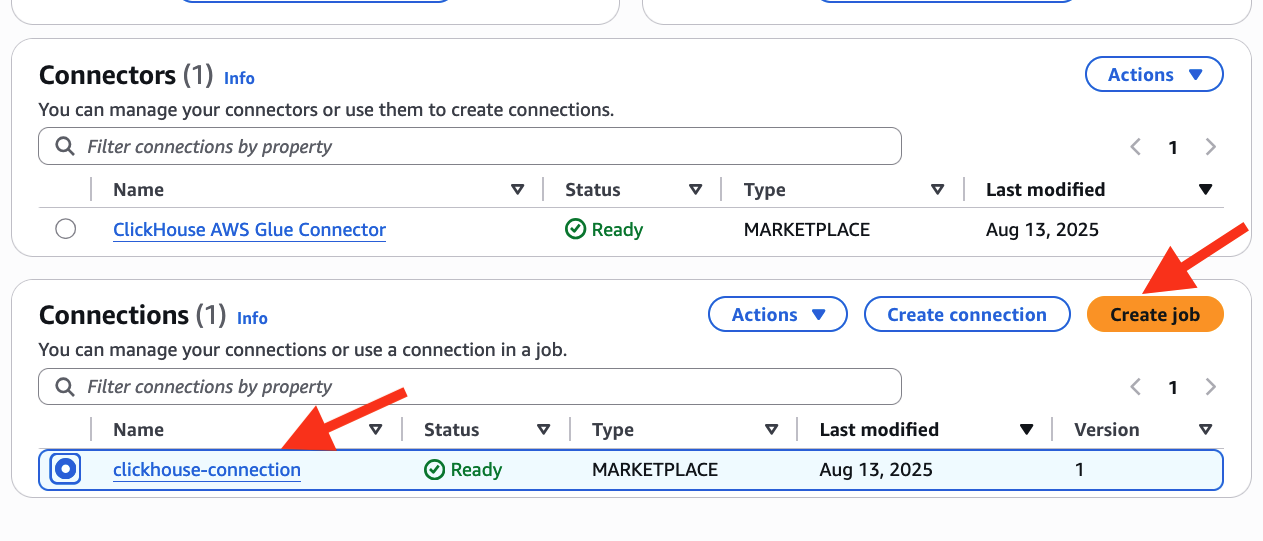
- Enter
bq_to_clickhouseas its job identify and configure gc_connector_role as its IAM Position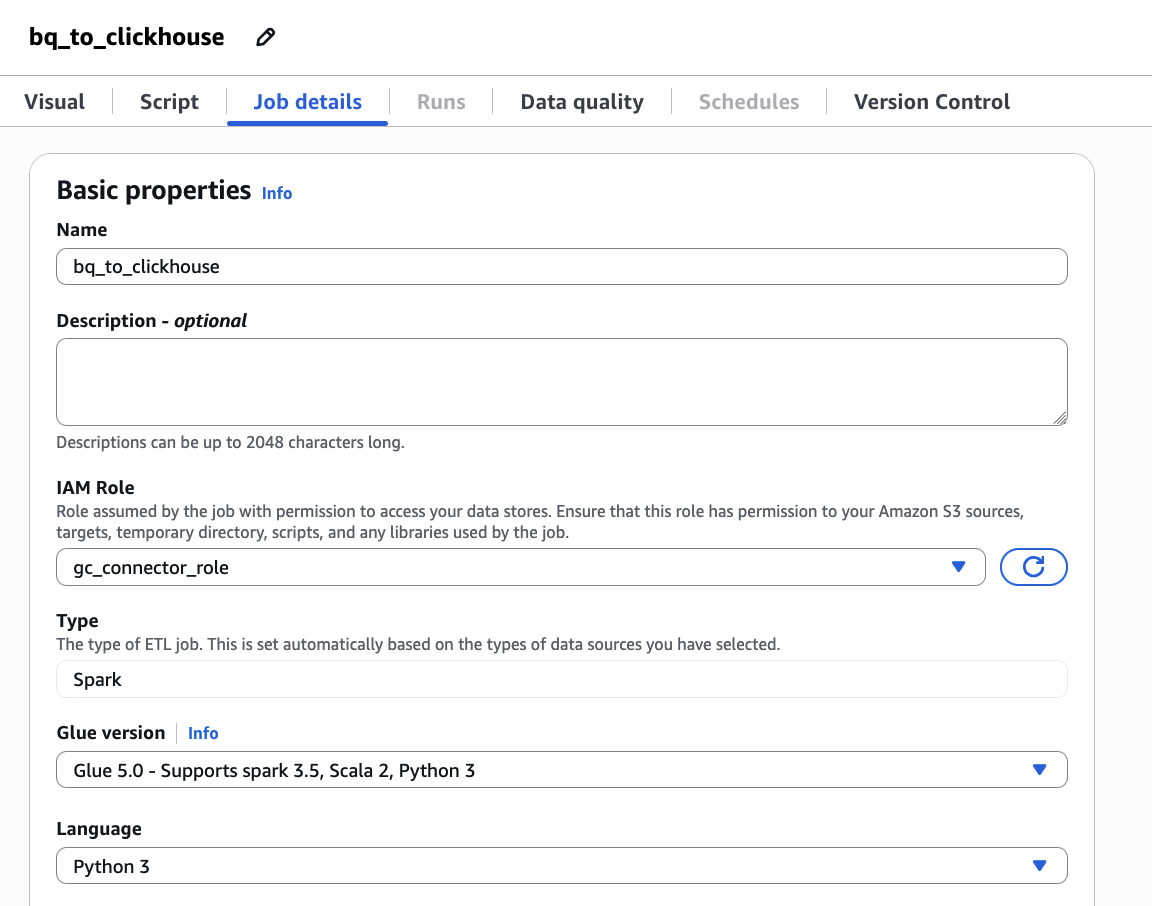
- Configure BigQuery connection and clickhouse-connection to the Connection property
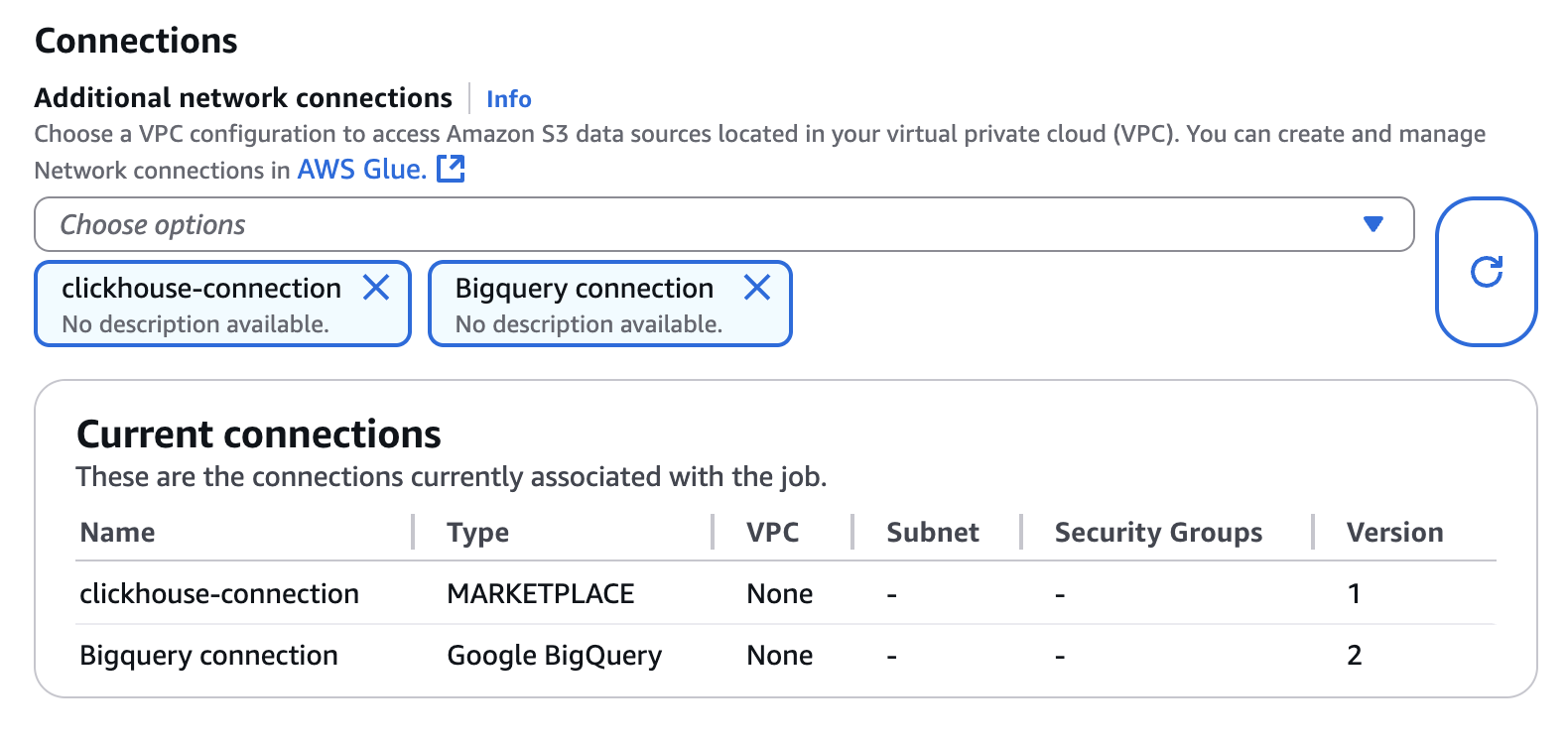
- Select the Script tab and Edit script. Then select Verify on the Edit script popup view.
- Copy and paste the next code onto the script editor which may be referred from clickhouse official doc
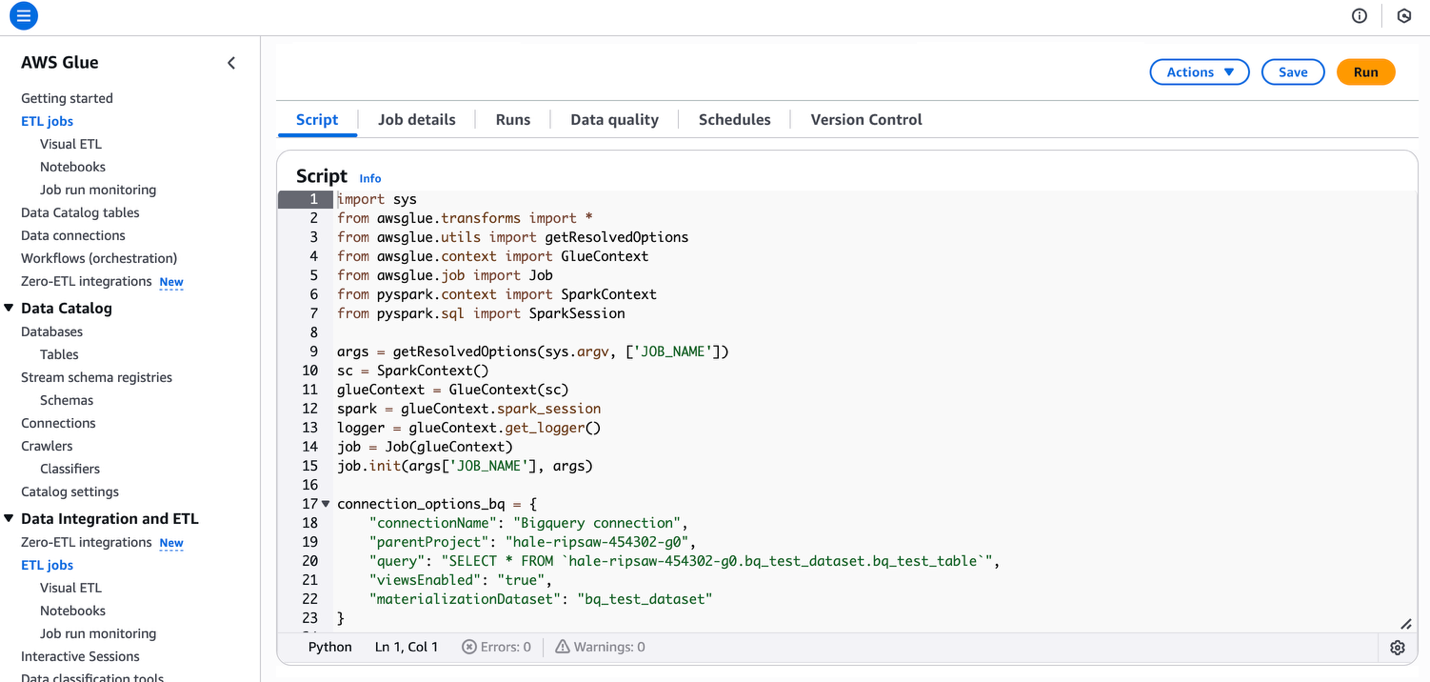
- The supply code is as following:
- Select Save and Run on the precise prime of the present view
- On the Connectors view as under, choose clickhouse-connection and select Create job
Testing and Validation
Testing is essential to confirm knowledge accuracy and efficiency within the new setting. After the migration completes, run knowledge integrity checks to substantiate document counts and knowledge high quality in ClickHouse Cloud. Schema validation is crucial, as every knowledge subject should align accurately with ClickHouse’s format. Working efficiency benchmarks, equivalent to pattern queries, will assist confirm that ClickHouse’s setup delivers the specified pace and effectivity beneficial properties.
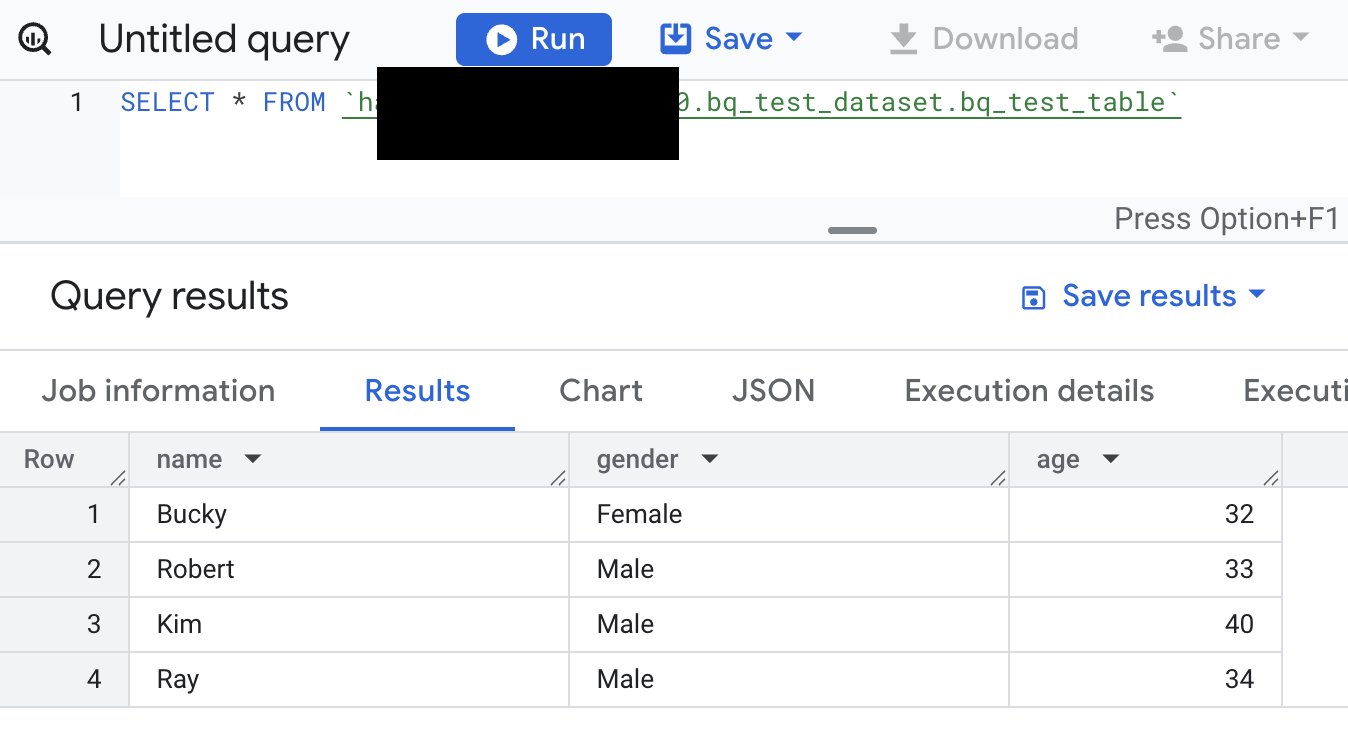
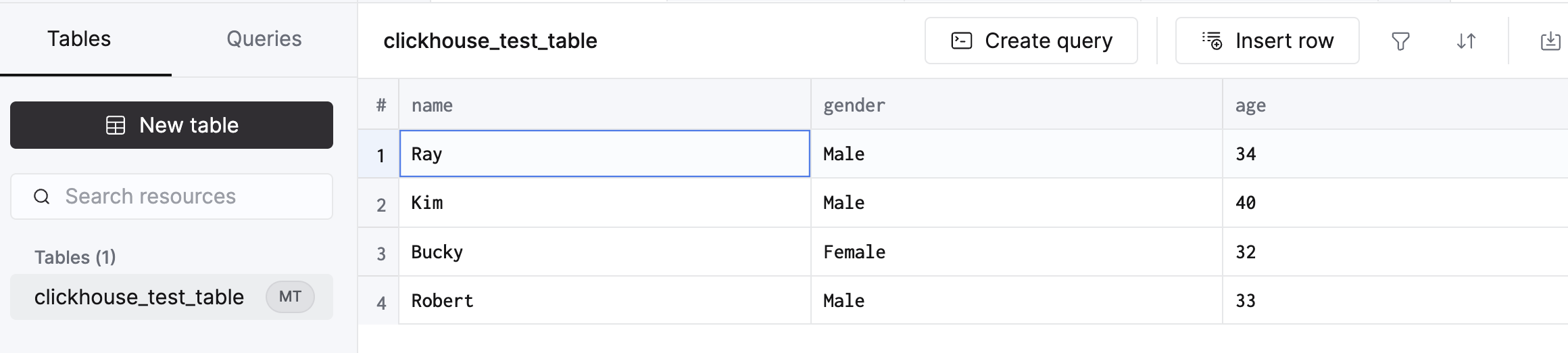
- The Schema and Information in supply BigQuery and vacation spot Clickhouse
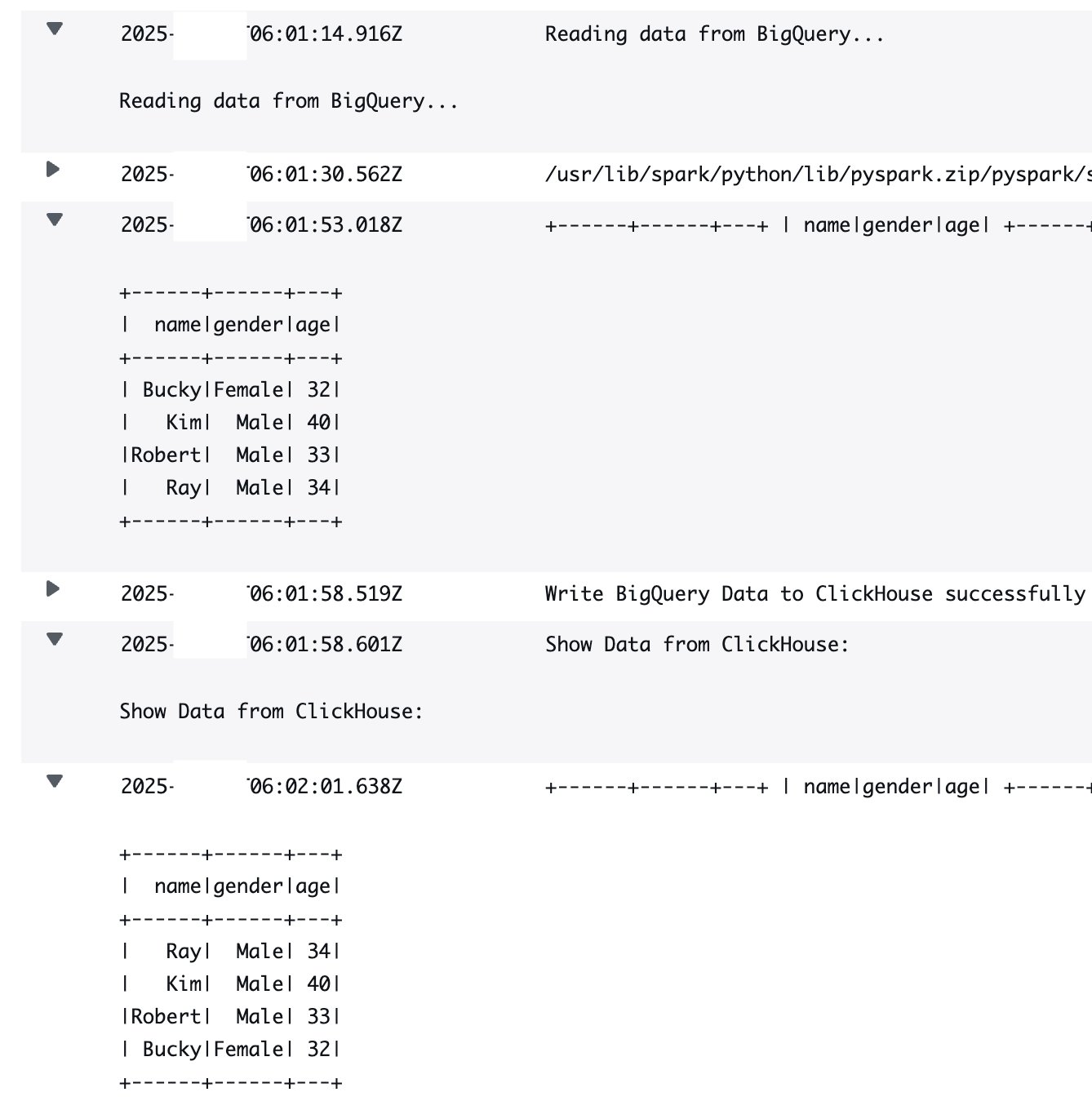
- AWS Glue output logs
Clear Up
After finishing the migration, it’s essential to scrub up unused assets—equivalent to BigQuery for pattern knowledge import and database assets in ClickHouse Cloud—to keep away from pointless prices. Relating to IAM permissions, adhering to the precept of least privilege is advisable. This includes granting customers and roles solely the permissions vital for his or her duties and eradicating pointless permissions when they’re not required. This strategy enhances safety by minimizing potential risk surfaces. Moreover, reviewing AWS Glue job prices and configurations can assist establish optimization alternatives for future migrations. Monitoring total prices and analyzing utilization can reveal areas the place code or configuration enhancements might result in price financial savings.
Conclusion
AWS Glue ETL affords a strong and user-friendly answer for migrating knowledge from BigQuery to ClickHouse Cloud on AWS. By using Glue’s serverless structure, organizations can carry out knowledge migrations which are environment friendly, safe, and cost-effective. The direct integration with ClickHouse streamlines knowledge switch, supporting excessive efficiency and suppleness. This migration strategy is especially well-suited for firms seeking to improve their real-time analytics capabilities on AWS.
In regards to the Authors

{kind=link}