
Why deal with LLM inference as batched kernels to DRAM when a dataflow compiler can pipe tiles by on-chip FIFOs and stream converters?StreamTensor is a compiler that lowers PyTorch LLM graphs (GPT-2, Llama, Qwen, Gemma) into stream-scheduled dataflow accelerators on AMD’s Alveo U55C FPGA. The system introduces an iterative tensor (“itensor”) kind to encode tile/order of streams, enabling provably appropriate inter-kernel streaming and automatic insertion/sizing of DMA engines, FIFOs, and structure converters. On LLM decoding workloads, the analysis crew experiences as much as 0.64× decrease latency vs. GPUs and as much as 1.99× increased vitality effectivity.
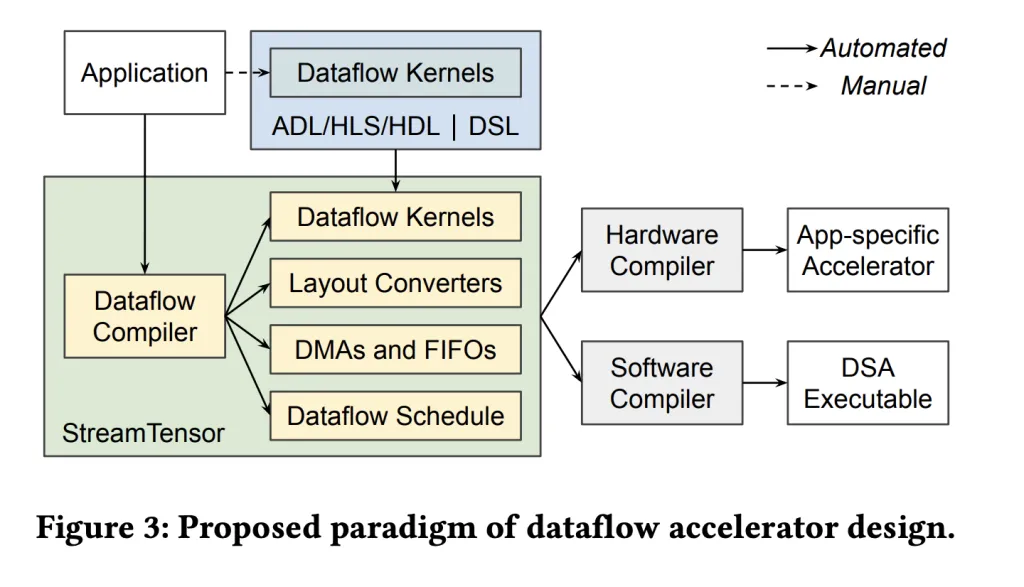
What StreamTensor does?
StreamTensor compiles PyTorch graphs right into a stream-oriented dataflow design in order that intermediate tiles are largely avoids off-chip DRAM round-trips through on-chip streaming and fusion; DMAs are inserted solely when required; they’re forwarded by on-chip FIFOs to downstream kernels. The compiler’s central abstraction—iterative tensors (itensors)—information iteration order, tiling, and structure, which makes inter-kernel stream compatibility express and drives converter technology solely the place wanted. The framework additionally searches hierarchically over tiling, fusion, and useful resource allocation, and makes use of a linear program to measurement FIFOs to keep away from stalls or impasse whereas minimizing on-chip reminiscence.
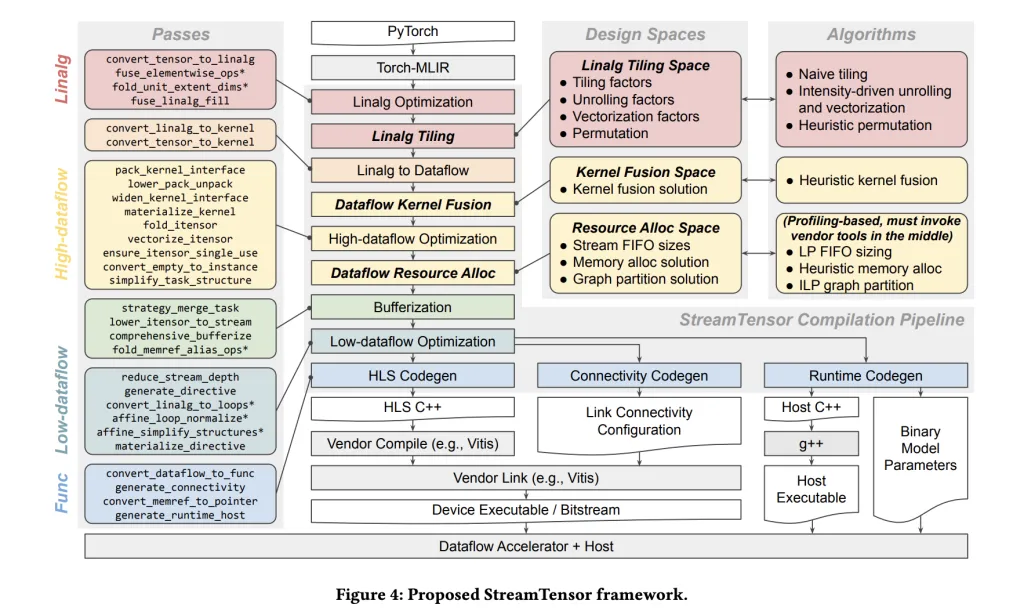
What’s really new?
- Hierarchical DSE. The compiler explores three design areas—(i) tiling/unroll/vectorization/permutation on the Linalg degree, (ii) fusion beneath reminiscence/useful resource constraints, and (iii) useful resource allocation/stream widths—optimizing for sustained throughput beneath bandwidth limits.
- Finish-to-end PyTorch → system movement. Fashions enter through Torch-MLIR, are reworked to MLIR Linalg, after which right into a dataflow IR whose nodes change into {hardware} kernels with express streams and host/runtime glue—no handbook RTL meeting.
- iterative tensor (itensor) typing system. A primary-class tensor kind expresses iteration order, tiling, and affine maps. This makes stream order express, permits protected kernel fusion, and lets the compiler synthesize minimal buffer/format converters when producers/shoppers disagree.
- Formal FIFO sizing. Inter-kernel buffering is solved with a linear-programming formulation to keep away from stalls/deadlocks whereas minimizing on-chip reminiscence utilization (BRAM/URAM).
Outcomes
Latency: as much as 0.76× vs prior FPGA LLM accelerators and 0.64× vs a GPU baseline on GPT-2; Power effectivity: as much as 1.99× vs A100 on rising LLMs (model-dependent). Platform context: Alveo U55C (HBM2 16 GB, 460 GB/s, PCIe Gen3×16 or twin Gen4×8, 2×QSFP28).
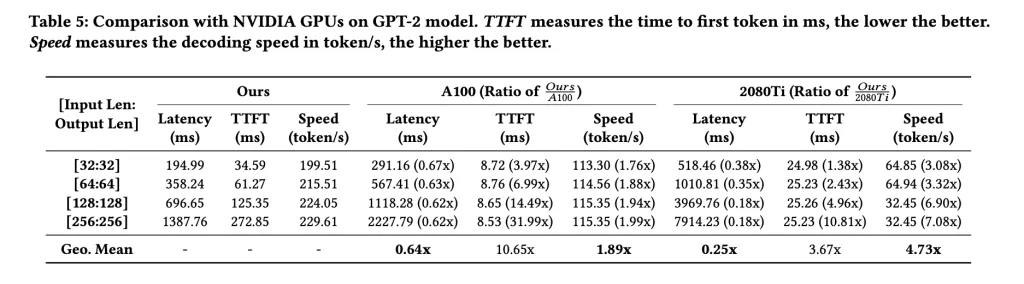
The helpful contribution here’s a PyTorch→Torch-MLIR→dataflow compiler that emits stream-scheduled kernels and a number/runtime for AMD’s Alveo U55C; the iterative tensor kind plus linear-programming-based FIFO sizing allows protected inter-kernel streaming slightly than DRAM round-trips. On reported LLM decoding benchmarks throughout GPT-2, Llama, Qwen, and Gemma, the analysis crew present geometric-mean latency as little as 0.64× vs. a GPU baseline and vitality effectivity as much as 1.99×, with scope restricted to decoding workloads. The {hardware} context is evident: Alveo U55C offers 16 GB HBM2 at 460 GB/s with twin QSFP28 and PCIe Gen3×16 or twin Gen4×8, which aligns with the streaming dataflow design.
Try the Paper. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking complicated datasets into actionable insights.

{kind=link}