
Salesforce AI Analysis launched CoDA-1.7B, a diffusion-based language mannequin for code that generates by denoising complete sequences with bidirectional context, updating a number of tokens in parallel relatively than left-to-right next-token prediction. The analysis workforce revealed each Base and Instruct checkpoints and an end-to-end coaching/analysis/serving stack.
Understanding the structure and coaching
CoDA adapts a 1.7B-parameter spine to discrete diffusion for textual content: masked sequences are iteratively denoised utilizing full-sequence consideration, enabling native infilling and non-autoregressive decoding. The mannequin card paperwork a three-stage pipeline (pre-training with bidirectional masking, supervised post-training, and progressive denoising at inference) plus reproducible scripts for TPU pre-training, GPU fine-tuning, and analysis.
Key options surfaced within the launch:
- Bidirectional context through diffusion denoising (no mounted era order).
- Confidence-guided sampling (entropy-style decoding) to commerce high quality vs. velocity.
- Open coaching pipeline with deploy scripts and CLI.
How do they carry out on Benchmarks?
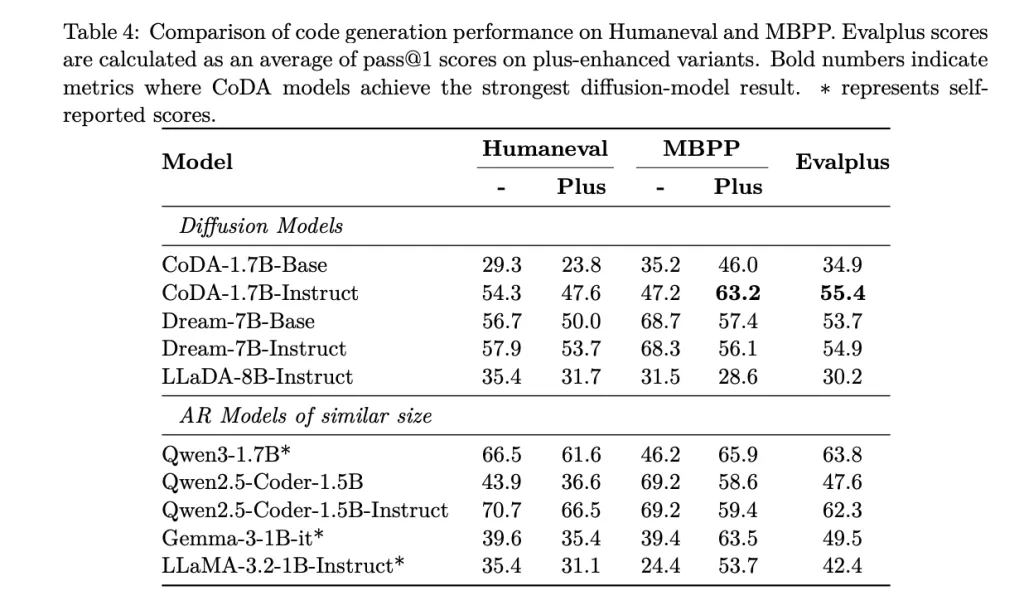
On commonplace code-gen suites, CoDA-1.7B-Instruct studies: HumanEval 54.3%, HumanEval+ 47.6%, MBPP 47.2%, MBPP+ 63.2%, EvalPlus mixture 55.4% (cross@1). For context, the mannequin card compares in opposition to diffusion baselines together with Dream-7B-Instruct (57.9% HumanEval), indicating CoDA’s 1.7B footprint is aggressive with some 7B diffusion fashions on a number of metrics whereas utilizing fewer parameters.
Inference habits
Technology price is ruled by the variety of diffusion steps; CoDA exposes knobs corresponding to STEPS, ALG="entropy", ALG_TEMP, and block size to tune latency/high quality trade-offs. As a result of tokens are up to date in parallel below full consideration, CoDA targets decrease wall-clock latency at small scale in contrast with bigger diffusion fashions, at comparable step budgets. (Hugging Face)
Deployment and licensing
The repository offers a FastAPI server with OpenAI-compatible APIs and an interactive CLI for native inference; directions embrace atmosphere setup and a start_server.sh launcher. Mannequin playing cards and a Hugging Face assortment centralize artifacts. The checkpoints are revealed below CC BY-NC 4.0 on Hugging Face.
CoDA-1.7B stands as a clear reference for discrete-diffusion code era at small scale: 1.7B parameters, bidirectional denoising with parallel token updates, and a reproducible pipeline from pre-training to SFT and serving. The reported cross@1 outcomes—HumanEval 54.3, HumanEval+ 47.6, MBPP 47.2, MBPP+ 63.2, EvalPlus mixture 55.4—place it aggressive with some 7B diffusion baselines (e.g., Dream-7B HumanEval 57.9) whereas utilizing fewer parameters. Inference latency is explicitly ruled by step rely and decoding knobs (STEPS, entropy-style steerage), which is operationally helpful for tuning throughput/high quality. The discharge contains weights on Hugging Face and a FastAPI server/CLI for native deployment.
Try the Paper, GitHub Repo and Mannequin on Hugging Face. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as effectively.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}