")
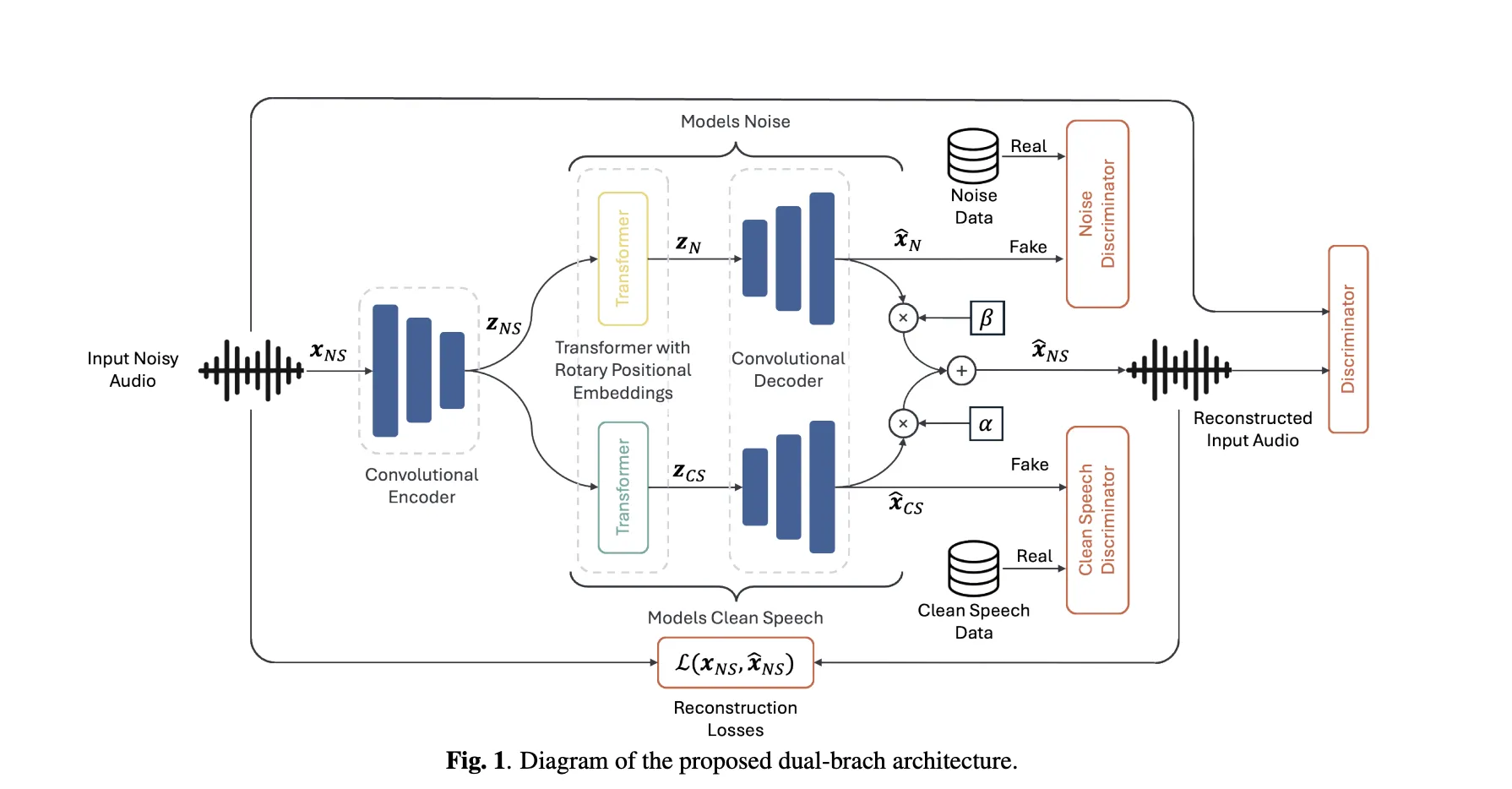
Can a speech enhancer skilled solely on actual noisy recordings cleanly separate speech and noise—with out ever seeing paired information? A group of researchers from Brno College of Expertise and Johns Hopkins College proposes Unsupervised Speech Enhancement utilizing Information-defined Priors (USE-DDP), a dual-stream encoder–decoder that separates any noisy enter into two waveforms—estimated clear speech and residual noise—and learns each solely from unpaired datasets (clean-speech corpus and elective noise corpus). Coaching enforces that the sum of the 2 outputs reconstructs the enter waveform, avoiding degenerate options and aligning the design with neural audio codec aims.
Why that is necessary?
Most learning-based speech enhancement pipelines depend upon paired clear–noisy recordings, that are costly or unattainable to gather at scale in real-world circumstances. Unsupervised routes like MetricGAN-U take away the necessity for clear information however couple mannequin efficiency to exterior, non-intrusive metrics used throughout coaching. USE-DDP retains the coaching data-only, imposing priors with discriminators over impartial clean-speech and noise datasets and utilizing reconstruction consistency to tie estimates again to the noticed combination.
The way it works?
- Generator: A codec-style encoder compresses the enter audio right into a latent sequence; that is cut up into two parallel transformer branches (RoFormer) that focus on clear speech and noise respectively, decoded by a shared decoder again to waveforms. The enter is reconstructed because the least-squares mixture of the 2 outputs (scalars α, β compensate for amplitude errors). Reconstruction makes use of multi-scale mel/STFT and SI-SDR losses, as in neural audio codecs.
- Priors through adversaries: Three discriminator ensembles—clear, noise, and noisy—impose distributional constraints: the clear department should resemble the clean-speech corpus; the noise department should resemble a noise corpus; the reconstructed combination should sound pure. LS-GAN and feature-matching losses are used.
- Initialization: Initializing encoder/decoder from a pretrained Descript Audio Codec improves convergence and ultimate high quality vs. coaching from scratch.
The way it compares?
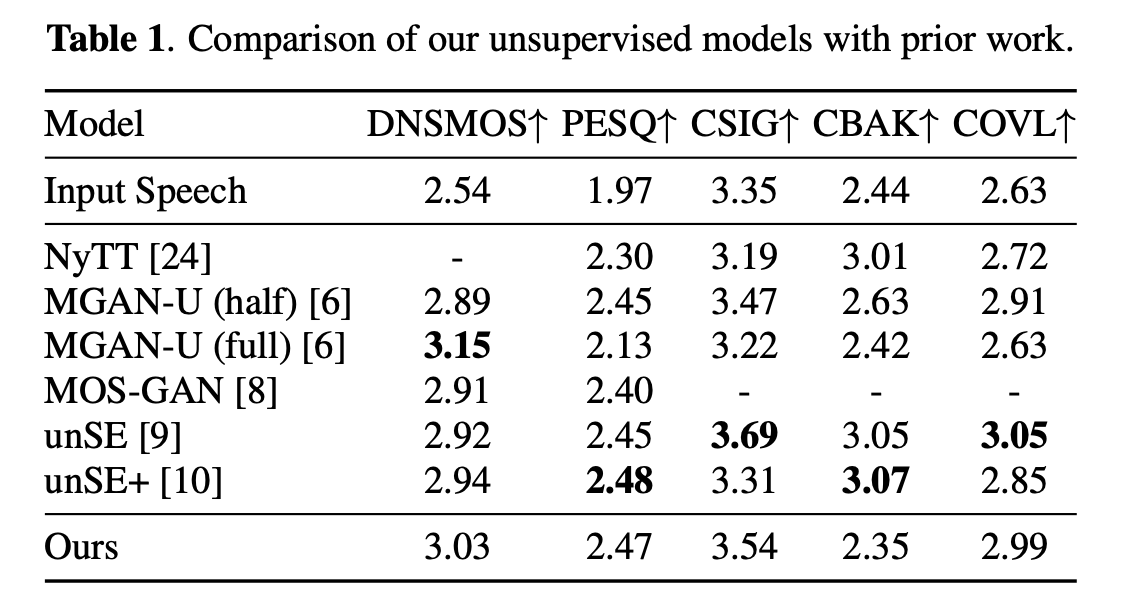
On the usual VCTK+DEMAND simulated setup, USE-DDP stories parity with the strongest unsupervised baselines (e.g., unSE/unSE+ based mostly on optimum transport) and aggressive DNSMOS vs. MetricGAN-U (which instantly optimizes DNSMOS). Instance numbers from the paper’s Desk 1 (enter vs. methods): DNSMOS improves from 2.54 (noisy) to ~3.03 (USE-DDP), PESQ from 1.97 to ~2.47; CBAK trails some baselines resulting from extra aggressive noise attenuation in non-speech segments—in keeping with the express noise prior.
Information alternative is just not a element—it’s the consequence
A central discovering: which clean-speech corpus defines the prior can swing outcomes and even create over-optimistic outcomes on simulated assessments.
- In-domain prior (VCTK clear) on VCTK+DEMAND → finest scores (DNSMOS ≈3.03), however this configuration unrealistically “peeks” on the goal distribution used to synthesize the mixtures.
- Out-of-domain prior → notably decrease metrics (e.g., PESQ ~2.04), reflecting distribution mismatch and a few noise leakage into the clear department.
- Actual-world CHiME-3: utilizing a “close-talk” channel as in-domain clear prior really hurts—as a result of the “clear” reference itself accommodates surroundings bleed; an out-of-domain really clear corpus yields larger DNSMOS/UTMOS on each dev and take a look at, albeit with some intelligibility trade-off below stronger suppression.
This clarifies discrepancies throughout prior unsupervised outcomes and argues for cautious, clear prior choice when claiming SOTA on simulated benchmarks.
The proposed dual-branch encoder-decoder structure treats enhancement as specific two-source estimation with data-defined priors, not metric-chasing. The reconstruction constraint (clear + noise = enter) plus adversarial priors over impartial clear/noise corpora offers a transparent inductive bias, and initializing from a neural audio codec is a practical technique to stabilize coaching. The outcomes look aggressive with unsupervised baselines whereas avoiding DNSMOS-guided aims; the caveat is that “clear prior” alternative materially impacts reported features, so claims ought to specify corpus choice.
Try the PAPER. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be part of us on telegram as properly.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Information Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and information engineering, Michal excels at remodeling advanced datasets into actionable insights.

{kind=link}