
IBM simply launched Granite 4.0, an open-source LLM household that swaps monolithic Transformers for a hybrid Mamba-2/Transformer stack to chop serving reminiscence whereas protecting high quality. Sizes span a 3B dense “Micro,” a 3B hybrid “H-Micro,” a 7B hybrid MoE “H-Tiny” (~1B lively), and a 32B hybrid MoE “H-Small” (~9B lively). The fashions are Apache-2.0, cryptographically signed, and—per IBM—the primary open fashions lined by an accredited ISO/IEC 42001:2023 AI administration system certification. They’re obtainable on watsonx.ai and through Docker Hub, Hugging Face, LM Studio, NVIDIA NIM, Ollama, Replicate, Dell Professional AI Studio/Enterprise Hub, Kaggle, with Azure AI Foundry…
So, what’s new?
Granite 4.0 introduces a hybrid design that interleaves a small fraction of self-attention blocks with a majority of Mamba-2 state-space layers (9:1 ratio). As per IBM technical weblog, relative to standard Transformer LLMs, Granite 4.0-H can scale back RAM by >70% for long-context and multi-session inference, translating into decrease GPU value at a given throughput/latency goal. IBM’s inner comparisons additionally present the smallest Granite 4.0 fashions outperforming Granite 3.3-8B regardless of utilizing fewer parameters.
Inform me what are the launched variants?
IBM is transport each Base and Instruct variants throughout 4 preliminary fashions:
- Granite-4.0-H-Small: 32B complete, ~9B lively (hybrid MoE).
- Granite-4.0-H-Tiny: 7B complete, ~1B lively (hybrid MoE).
- Granite-4.0-H-Micro: 3B (hybrid dense).
- Granite-4.0-Micro: 3B (dense Transformer for stacks that don’t but help hybrids).
All are Apache-2.0 and cryptographically signed; IBM states Granite is the primary open mannequin household with accredited ISO/IEC 42001 protection for its AI administration system (AIMS). Reasoning-optimized (“Pondering”) variants are deliberate later in 2025.
How is it skilled, context, and dtype?
Granite 4.0 was skilled on samples as much as 512K tokens and evaluated as much as 128K tokens. Public checkpoints on Hugging Face are BF16 (quantized and GGUF conversions are additionally printed), whereas FP8 is an execution choice on supported {hardware}—not the format of the launched weights.
Lets perceive it’s efficiency indicators (enterprise-relevant)
IBM highlights instruction following and tool-use benchmarks:
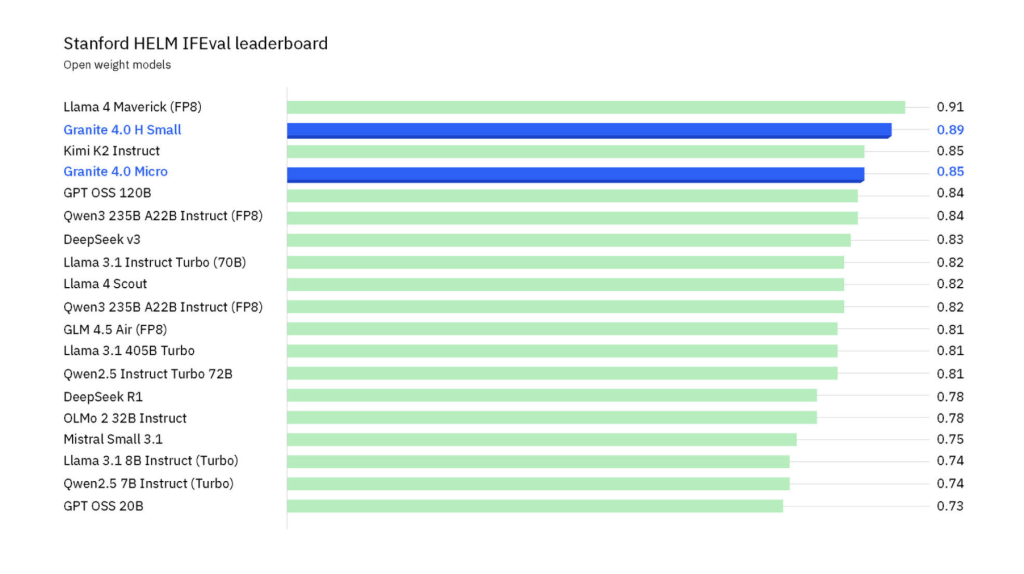
IFEval (HELM): Granite-4.0-H-Small leads most open-weights fashions (trailing solely Llama 4 Maverick at far bigger scale).
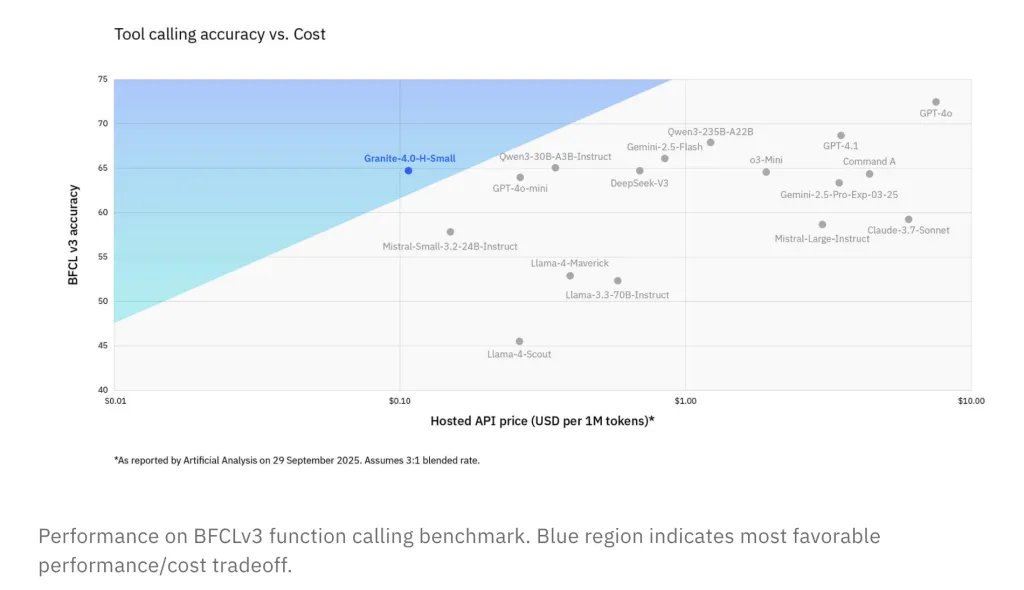
BFCLv3 (Perform Calling): H-Small is aggressive with bigger open/closed fashions at cheaper price factors.
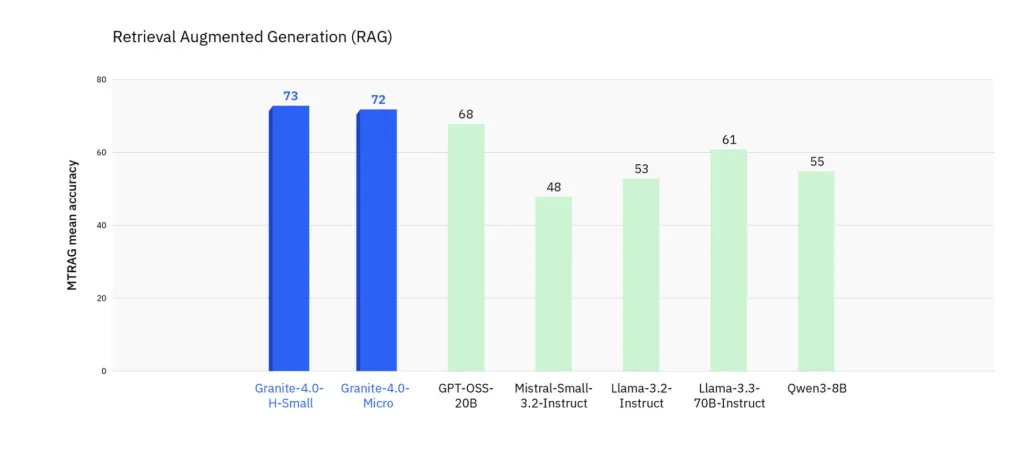
MTRAG (multi-turn RAG): Improved reliability on complicated retrieval workflows.
How can I get entry?
Granite 4.0 is dwell on IBM watsonx.ai and distributed through Dell Professional AI Studio/Enterprise Hub, Docker Hub, Hugging Face, Kaggle, LM Studio, NVIDIA NIM, Ollama, OPAQUE, Replicate. IBM notes ongoing enablement for vLLM, llama.cpp, NexaML, and MLX for hybrid serving.
I see Granite 4.0’s hybrid Mamba-2/Transformer stack and active-parameter MoE as a sensible path to decrease TCO: >70% reminiscence discount and long-context throughput positive aspects translate immediately into smaller GPU fleets with out sacrificing instruction-following or tool-use accuracy (IFEval, BFCLv3, MTRAG). The BF16 checkpoints with GGUF conversions simplify native analysis pipelines, and ISO/IEC 42001 plus signed artifacts deal with provenance/compliance gaps that sometimes stall enterprise deployment. Web end result: a lean, auditable base mannequin household (1B–9B lively) that’s simpler to productionize than prior 8B-class Transformers.
Try the Hugging Face Mannequin Card and Technical particulars. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be a part of us on telegram as effectively.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.

{kind=link}