, Bringing 80B/3B-Lively Hybrid-MoE to Commodity GPUs")
Alibaba’s Qwen crew has simply launched FP8-quantized checkpoints for its new Qwen3-Subsequent-80B-A3B fashions in two post-training variants—Instruct and Pondering—aimed toward high-throughput inference with ultra-long context and MoE effectivity. The FP8 repos mirror the BF16 releases however package deal “fine-grained FP8” weights (block dimension 128) and deployment notes for sglang and vLLM nightly builds. Benchmarks within the playing cards stay these of the unique BF16 fashions; FP8 is offered “for comfort and efficiency,” not as a separate analysis run.
What’s within the A3B stack
Qwen3-Subsequent-80B-A3B is a hybrid structure combining Gated DeltaNet (a linear/conv-style consideration surrogate) with Gated Consideration, interleaved with an ultra-sparse Combination-of-Consultants (MoE). The 80B whole parameter finances prompts ~3B params per token by way of 512 consultants (10 routed + 1 shared). The format is specified as 48 layers organized into 12 blocks: 3×(Gated DeltaNet → MoE) adopted by 1×(Gated Consideration → MoE). Native context is 262,144 tokens, validated as much as ~1,010,000 tokens utilizing RoPE scaling (YaRN). Hidden dimension is 2048; consideration makes use of 16 Q heads and a couple of KV heads at head dim 256; DeltaNet makes use of 32 V and 16 QK linear heads at head dim 128.
Qwen crew experiences the 80B-A3B base mannequin outperforms Qwen3-32B on downstream duties at ~10% of its coaching value and delivers ~10× inference throughput past 32K context—pushed by low activation in MoE and multi-token prediction (MTP). The Instruct variant is non-reasoning (no
FP8 releases: what truly modified
The FP8 mannequin playing cards state the quantization is “fine-grained fp8” with block dimension 128. Deployment differs barely from BF16: each sglang and vLLM require present fundamental/nightly builds, with instance instructions offered for 256K context and non-obligatory MTP. The Pondering FP8 card additionally recommends a reasoning parser flag (e.g., --reasoning-parser deepseek-r1 in sglang, deepseek_r1 in vLLM). These releases retain Apache-2.0 licensing.
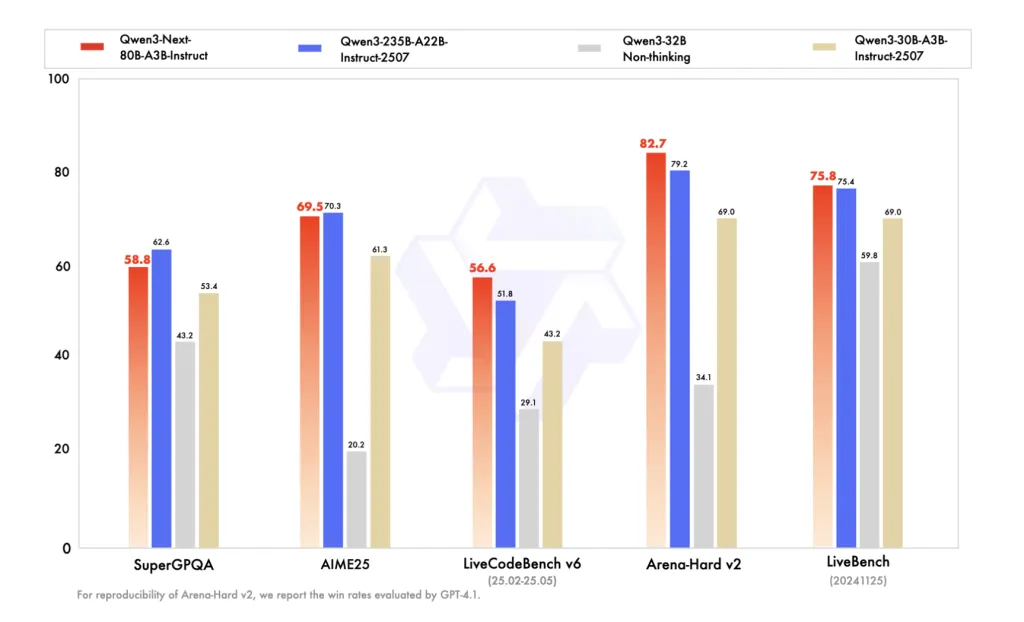
Benchmarks (reported on BF16 weights)
The Instruct FP8 card reproduces Qwen’s BF16 comparability desk, placing Qwen3-Subsequent-80B-A3B-Instruct on par with Qwen3-235B-A22B-Instruct-2507 on a number of data/reasoning/coding benchmarks, and forward on long-context workloads (as much as 256K). The Pondering FP8 card lists AIME’25, HMMT’25, MMLU-Professional/Redux, and LiveCodeBench v6, the place Qwen3-Subsequent-80B-A3B-Pondering surpasses earlier Qwen3 Pondering releases (30B A3B-2507, 32B) and claims wins over Gemini-2.5-Flash-Pondering on a number of benchmarks.
Coaching and post-training alerts
The collection is skilled on ~15T tokens earlier than post-training. Qwen highlights stability additions (zero-centered, weight-decayed layer norm, and so forth.) and makes use of GSPO in RL post-training for the Pondering mannequin to deal with the hybrid consideration + high-sparsity MoE mixture. MTP is used to hurry inference and enhance pretraining sign.
Why FP8 issues?
On fashionable accelerators, FP8 activations/weights cut back reminiscence bandwidth stress and resident footprint versus BF16, permitting bigger batch sizes or longer sequences at comparable latency. As a result of A3B routes solely ~3B parameters per token, the mix of FP8 + MoE sparsity compounds throughput positive aspects in long-context regimes, significantly when paired with speculative decoding by way of MTP as uncovered within the serving flags. That stated, quantization interacts with routing and a focus variants; real-world acceptance charges for speculative decoding and end-task accuracy can range with engine and kernel implementations—therefore Qwen’s steerage to make use of present sglang/vLLM and to tune speculative settings.
Abstract
Qwen’s FP8 releases make the 80B/3B-active A3B stack sensible to serve at 256K context on mainstream engines, preserving the hybrid-MoE design and MTP path for top throughput. The mannequin playing cards hold benchmarks from BF16, so groups ought to validate FP8 accuracy and latency on their very own stacks, particularly with reasoning parsers and speculative settings. Web final result: decrease reminiscence bandwidth and improved concurrency with out architectural regressions, positioned for long-context manufacturing workloads.
Try the Qwen3-Subsequent-80B-A3B fashions in two post-training variants—Instruct and Pondering. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}