
In the present day, organizations are closely utilizing Apache Spark for his or her huge information processing wants. Nevertheless, managing all the growth lifecycle of Spark functions—from native growth to manufacturing deployment—could be complicated and time-consuming. Managing all the code base—together with software code, infrastructure provisioning, and steady integration and supply (CI/CD) pipelines—is typically not absolutely automated and a shared duty throughout a number of groups, which slows down launch cycles. This undifferentiated heavy lifting diverts helpful assets away from core enterprise aims: deriving worth from information.
On this publish, we discover the way to use Amazon EMR, the AWS Cloud Improvement Equipment (AWS CDK), and the Knowledge Options Framework (DSF) on AWS to streamline the event course of, from establishing an area growth atmosphere to deploying serverless Spark infrastructure, and implementing a CI/CD pipeline for automated testing and deployment.
By adopting this strategy, builders acquire full management over their code and the infrastructure answerable for operating it, assuaging the necessity for cross-team dependency. Builders can customise the infrastructure to fulfill particular enterprise wants and optimize efficiency. Moreover, they will customise CI/CD levels to facilitate complete testing, utilizing the self-mutation functionality of AWS CDK Pipelines to routinely replace and refine the deployment course of. This stage of management not solely accelerates growth cycles but in addition enhances the reliability and effectivity of all the software lifecycle, so builders can focus extra on innovation and fewer on handbook infrastructure administration.
Resolution overview
The answer consists of the next key parts:
- The native growth atmosphere to develop and take a look at your Spark code regionally
- The infrastructure as code (IaC) that may run your Spark software in AWS environments
- The CI/CD pipeline operating end-to-end checks and deploying into the completely different AWS environments
Within the following sections, we focus on the way to arrange these parts.
Conditions
To arrange this answer, you have to have an AWS account with acceptable permissions, Docker and the AWS CDK CLI.
Arrange the native growth atmosphere
Creating Spark functions regionally is usually a difficult job because of the want for a constant and environment friendly atmosphere that mirrors your manufacturing setup. With Amazon EMR, Docker, and the Amazon EMR toolkit extension for Visible Studio Code, you possibly can shortly arrange an area growth atmosphere for Spark functions, creating and testing Spark code regionally, and seamlessly port it to the cloud.
The Amazon EMR toolkit for VS Code consists of an “EMR: Create Native Spark Atmosphere” command that generates a growth container. This container relies on an Amazon EMR on Amazon EKS picture comparable to the Amazon EMR model you choose. You’ll be able to develop Spark and PySpark code regionally, with full compatibility together with your distant Amazon EMR atmosphere. Moreover, the toolkit supplies helpers to make it easy to connect with the AWS Cloud, together with an Amazon EMR explorer, an AWS Glue Knowledge Catalog explorer, and instructions to run Amazon EMR Serverless jobs from VS Code.
To arrange your native atmosphere, full the next steps:
- Set up VS Code and the Amazon EMR Toolkit for VS Code.
- Set up and launch Docker.
- Create an area Amazon EMR atmosphere in your working listing utilizing the command EMR: Create Native Spark Atmosphere.
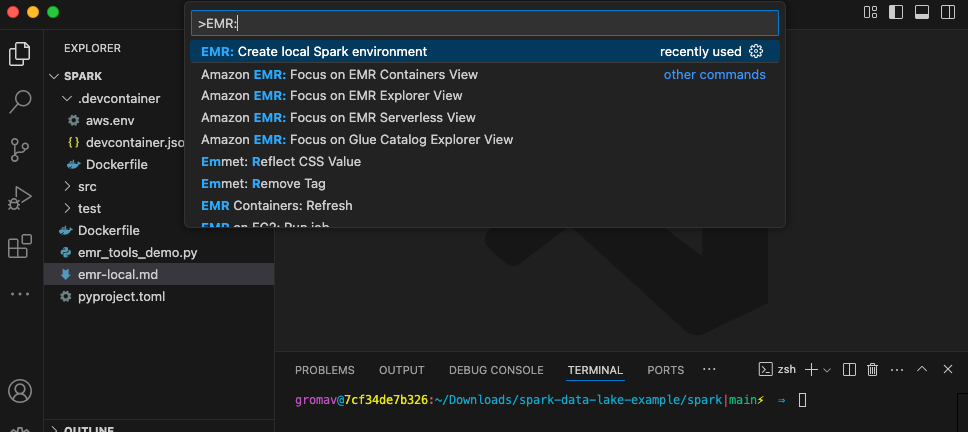
- Select PySpark, Amazon EMR 7.5, and the AWS Area you need to use, and select an authentication mechanism.
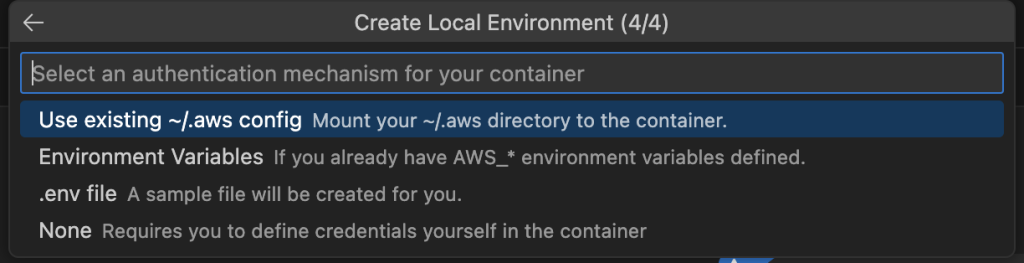
- Log in to Amazon ECR together with your AWS credentials utilizing the next command so you possibly can obtain the Amazon EMR picture:
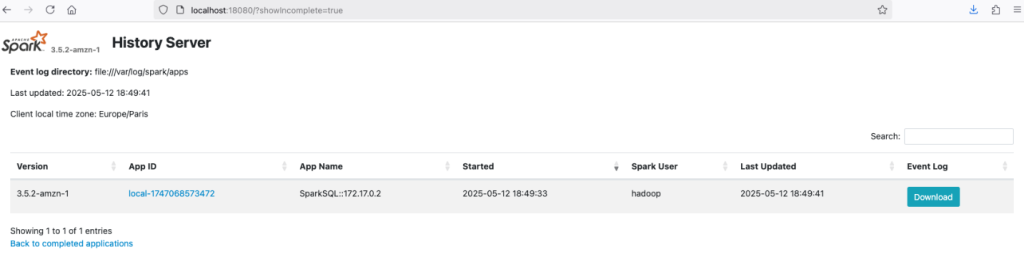
- Now you possibly can launch your dev container utilizing the VS Code command Dev Containers: Rebuild and Reopen in container.
The container will set up the most recent working system packages and run an area Spark historical past server on port 18080.
The container supplies spark-shell, spark-sql, and pyspark from the terminal and a Jupyter Python kernel for connecting a Jupyter pocket book to execute interactive Spark code.
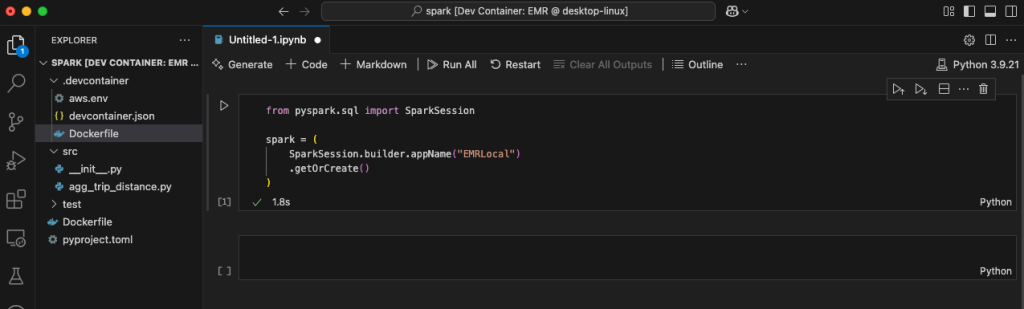
Utilizing the Amazon EMR Toolkit, you possibly can develop your Spark software and take a look at it regionally utilizing Pytest—for instance, to validate the enterprise logic. It’s also possible to hook up with different AWS accounts the place you have got your growth atmosphere.
Construct the AWS CDK software with DSF on AWS
After you validate the enterprise logic into your native Spark software, you possibly can implement the infrastructure answerable for operating your software. DSF supplies AWS CDK L3 Constructs that simplify the creation of Spark-based information pipelines on EMR Serverless or Amazon EMR on EKS.
DSF supplies the aptitude to package deal your native PySpark software, together with the Python dependencies, into artifacts that may consumed by EMR Serverless jobs. The PySparkApplicationPackage is a assemble that makes use of a Dockerfile to carry out the packaging of dependencies right into a Python digital atmosphere archive after which add the archive and the PySpark entrypoint file right into a secured Amazon Easy Storage Service (Amazon S3) bucket. The next diagram illustrates this structure.
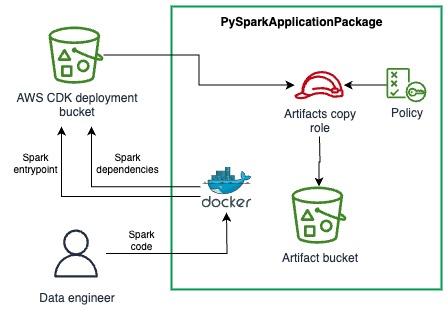
See the next instance code:
You simply want to supply the paths for the next:
- The PySpark entrypoint. That is the primary Python script of your Spark software.
- The Dockerfile containing the logic for packaging a digital atmosphere into an archive.
- The trail of the ensuing archive within the container file system.
DSF supplies helpers to attach the applying package deal to the EMR Serverless job. The PySparkApplicationPackage assemble exposes properties that may instantly be used into the SparkEmrServerlessJob assemble parameters. This assemble simplifies the configuration of a batch job utilizing an AWS Step Features state machine. The next diagram illustrates this structure.
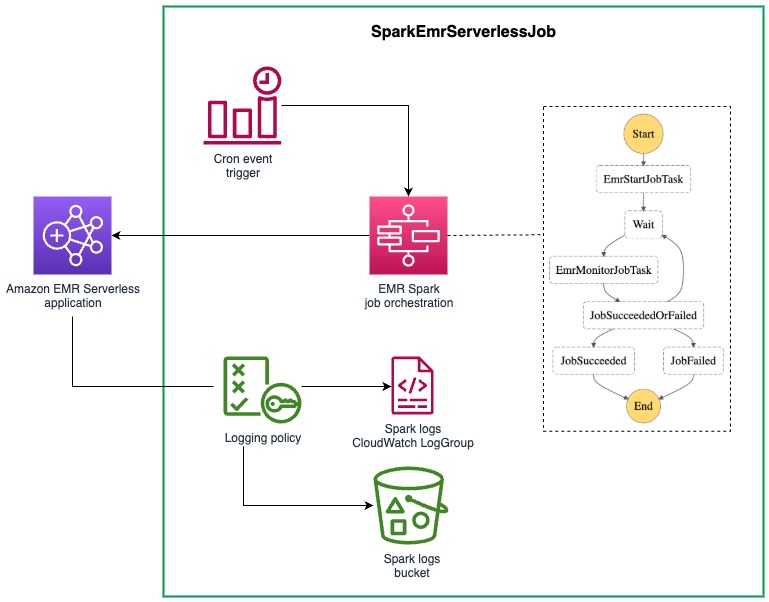
The next code is an instance of an EMR Serverless job:
Notice the 2 parameters of SparkEmrServerlessJob which might be offered by PySparkApplicationPackage:
- entrypoint_uri, which is the S3 URI of the entrypoint file
- spark_venv_conf, which comprises the Spark submit parameters for utilizing the Python digital atmosphere
DSF additionally supplies a SparkEmrServerlessRuntime to simplify the creation of the EMR Serverless software answerable for operating the job.
Deploy the Spark software utilizing CI/CD
The ultimate step is to implement a CI/CD pipeline that may take a look at your Spark code and promote from dev/take a look at/stage after which to manufacturing. DSF supplies a L3 Assemble that simplifies the creation of the CI/CD pipeline on your Spark functions. DSF’s implementation of the Spark CI/CD pipeline assemble makes use of the AWS CDK built-in pipeline performance. One of many key capabilities when utilizing an AWS CDK pipeline is its self-mutating functionality. It could replace itself everytime you change its definition, avoiding the standard chicken-and-egg drawback of pipeline updates and serving to builders absolutely management their CI/CD pipeline.
When the pipeline runs, it follows a fastidiously orchestrated sequence. First, it retrieves your code out of your repository and synthesizes it into AWS CloudFormation templates. Earlier than doing the rest, it examines these templates to see for those who’ve made any modifications to the pipeline’s personal construction. If the pipeline detects that its definition has modified, it should pause its regular operation and replace itself first. After the pipeline has up to date itself, it should proceed with its common levels, equivalent to deploying your software.
DSF supplies an opinionated implementation of CDK Pipelines for Spark functions, the place the PySpark code is routinely unit examined utilizing Pytest and the place the configuration is simplified. You solely have to configure 4 parts:
- The CI/CD levels (testing, staging, manufacturing, and so forth). This consists of the AWS account ID and Area the place these environments reside in.
- The AWS CDK stack that’s deployed in every atmosphere.
- (Non-compulsory) The mixing take a look at script that you simply need to run towards the deployed stack.
- The SparkEmrCICDPipeline AWS CDK assemble.
The next diagram illustrates how all the things works collectively.
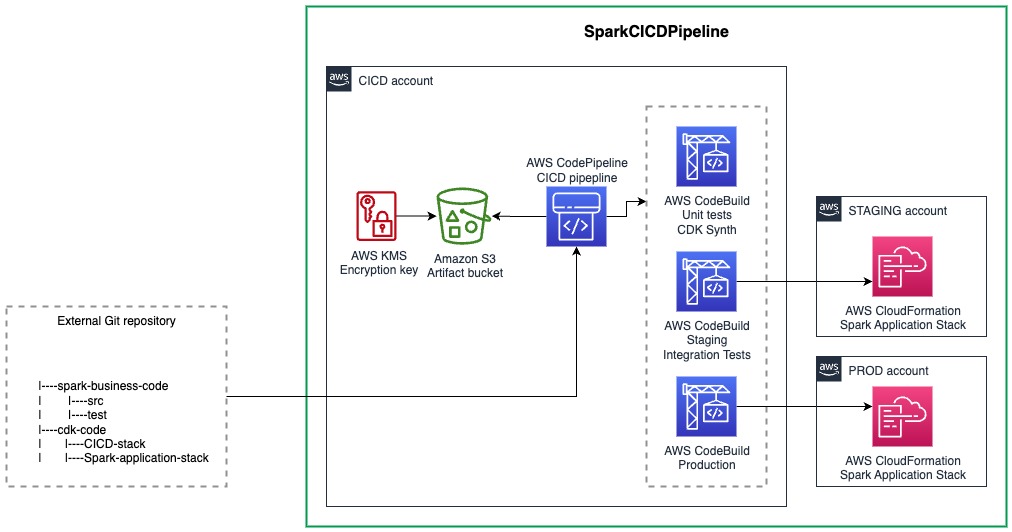
Let’s dive into every of those parts.
Outline cross-account deployment and CI/CD levels
With the SparkEmrCICDPipeline assemble, you possibly can deploy your Spark software stack throughout completely different AWS accounts. For instance, you possibly can have a separate account on your CI/CD processes and completely different accounts on your staging and manufacturing environments.To set this up, first bootstrap the varied AWS accounts (staging, manufacturing, and so forth):
This step units up the required assets within the atmosphere accounts and creates a belief relationship between these accounts and the CI/CD account the place the pipeline will run.Subsequent, select between two choices to outline the environments (each choices require the related configuration within the cdk.context.json file.The primary choice is to make use of pre-defined environments, which is outlined as follows:
Alternatively, you should utilize user-defined environments, which is outlined as follows:
Customise the stack to be deployed
Now that the environments have been bootstrapped and configured, let’s take a look at the precise stack that comprises the assets that will likely be deployed within the varied environments. Two lessons have to be carried out:
- A category that extends the stack – That is the place the assets which might be going to be deployed in every of the environments are outlined. This is usually a regular AWS CDK stack, however it may be deployed in one other AWS account relying on the atmosphere configuration outlined within the earlier part.
- A category that extends ApplicationStackFactory – That is DSF particular, and makes it doable to configure after which return the stack that’s created.
The next code reveals a full instance:
ApplicationStackFactory helps customization of the stack earlier than returning the initialized object to be deployed by the CI/CD pipeline. You’ll be able to customise your stack conduct by passing the present stage to your stack. For instance, you possibly can skip scheduling the Spark software within the integration checks stage as a result of the combination checks set off it manually as a part of the CI/CD pipeline. For the manufacturing stage, the scheduling facilitates computerized execution of the Spark software.
Write the combination take a look at script
The mixing take a look at script is a bash script that’s triggered after the primary software stack has been deployed. Inputs to the bash script can come from the AWS CloudFormation outputs of the primary software stack. These outputs are mapped into atmosphere variables that the bash script can entry instantly.
Within the Spark CI/CD instance, the software stack makes use of the SparkEMRServerlessJob CDK assemble. This assemble makes use of a Step Features state machine to handle the execution and monitoring of the Spark job. The next is an instance integration take a look at bash script that we use to check that the deployed stack can run the related Spark job efficiently:
The mixing take a look at scripts are executed inside an AWS CodeBuild challenge. As a part of the IntegrationTestStack, we’ve included a customized useful resource that periodically checks the standing of the combination take a look at script because it runs. Failure of the CodeBuild execution causes the dad or mum pipeline (residing within the pipeline account) to fail. This helps groups solely promote modifications that go all of the required testing.
Carry all of the parts collectively
When you have got your parts prepared, you should utilize the SparkEmrCICDPipeline to deliver them collectively. See the next instance code:
The next components of the code are price highlighting:
- With the integ_test_env parameter, you possibly can outline the atmosphere variable mapping with the output of your software stack that’s outlined within the application_stack_factory parameter
- The integ_test_permissions parameter specifies the AWS Identification and Entry Administration (IAM) permissions which might be hooked up to the CodeBuild challenge the place the combination take a look at script runs in
- CDK Pipelines wants an AWS code connection Amazon Useful resource Identify (ARN) to connect with your Git repository whenever you host your code
Now you possibly can deploy the stack containing the CI/CD pipeline. It is a one-time operation as a result of the CI/CD pipeline will dynamically be up to date primarily based on code modifications that influence the CI/CD pipeline itself:
Then you possibly can commit and push the code into the supply code repository outlined within the supply parameter. This step triggers the pipeline and deploys the applying within the configured environments. You’ll be able to verify the pipeline definition and standing on the AWS CodePipeline console.
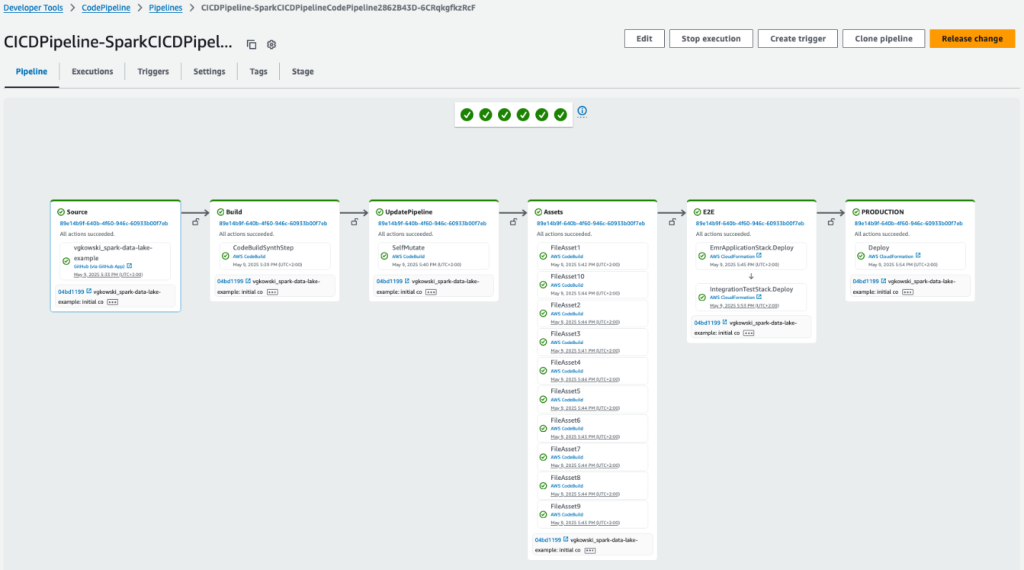
Yow will discover the complete instance on the Knowledge Options Framework GitHub repository.
Clear up
Comply with the readme information to delete the assets created by the answer.
Conclusion
By utilizing Amazon EMR, the AWS CDK, DSF on AWS, and the Amazon EMR toolkit, builders can now streamline their Spark software growth course of. The answer described on this publish helps builders acquire full management over their code and infrastructure, making it doable to arrange native growth environments, implement automated CI/CD pipelines, and deploy serverless Spark infrastructure throughout a number of environments.
DSF helps different patterns, equivalent to streaming governance and information sharing and Amazon Redshift information warehousing. The DSF roadmap is publicly obtainable, and we sit up for your characteristic requests, contributions, and suggestions. You may get began utilizing DSF by following our Fast begin information.
In regards to the authors

{kind=link}