
AI fashions are getting smarter by the day – reasoning higher, working sooner, and dealing with longer contexts than ever earlier than. The Qwen3-Subsequent-80B-A3B takes this leap ahead with environment friendly coaching patterns, a hybrid consideration mechanism, and an ultra-sparse combination of consultants. Add stability-focused tweaks, and also you get a mannequin that’s faster, extra dependable, and stronger on benchmarks. On this article, we’ll discover its structure, coaching effectivity, and efficiency on Instruct and Considering prompts. We’ll additionally have a look at upgrades in long-context dealing with, multi-token prediction, and inference optimization. Lastly, we’ll present you entry and use the Qwen 3 Subsequent API by Hugging Face.
Understanding the Structure of Qwen3-Subsequent-80B-A3B
Qwen3-Subsequent makes use of a forward-looking structure that balances computational effectivity, recall, and coaching stability. It displays deep experimentation with hybrid consideration mechanisms, ultra-sparse mixture-of-experts scaling, and inference optimizations.
Let’s break down its key parts, step-by-step:
Hybrid Consideration: Gated DeltaNet + Gated Consideration
Conventional scaled dot-product consideration is powerful however computationally costly because of quadratic complexity. Linear consideration scales higher however struggles with long-range recall. Qwen3-Subsequent-80B-A3B takes a hybrid strategy:
- 75% of layers use Gated DeltaNet (linear consideration) for environment friendly sequence processing.
- 25% of layers use customary gated consideration for stronger recall.
This 3:1 combine improves inference velocity whereas preserving accuracy in context studying. Further enhancements embody:
- Bigger gated head dimensions (256 vs. 128).
- Partial rotary embeddings utilized to 25% of place dimensions.
Extremely-Sparse Combination of Specialists (MoE)
Qwen3-Subsequent implements a really sparse MoE design: 80B whole parameters, however solely ~3B activated at every inference step. Experiments present that world load balancing incurs coaching loss constantly, lowering from growing whole skilled parameters, whereas preserving activated consultants fixed. Qwen3-Subsequent pushes MoE design to a brand new scale:
- 512 consultants in whole, with 10 routed + 1 shared skilled activated per step.
- Regardless of having 80B whole parameters, solely ~3B are lively per inference, putting a wonderful stability between capability and effectivity.
- A world load-balancing technique ensures even skilled utilization, minimizing wasted capability whereas steadily lowering coaching loss as skilled rely grows.
This sparse activation design is what allows the mannequin to scale massively with out proportionally growing inference prices.
Coaching Stability Improvements
Scaling fashions usually introduce hidden pitfalls akin to exploding norms or activation sinks. Qwen3-Subsequent addresses this with a number of stability-first mechanisms:
- Output gating in consideration eliminates low-rank points and a spotlight sink results.
- Zero-Centered RMSNorm replaces QK-Norm, stopping runaway norm weights.
- Weight decay on norm parameters avoids unbounded progress.
- Balanced router initialization ensures honest skilled choice from the very begin, lowering coaching noise.
These cautious changes make each small-scale checks and large-scale coaching considerably extra dependable.
Multi-Token Prediction (MTP)
Qwen3-Subsequent integrates a local MTP module with a excessive acceptance charge for speculative decoding, together with multi-step inference optimizations. Utilizing a multi-step coaching strategy, it aligns coaching and inference to scale back mismatch and enhance real-world efficiency.
Key advantages:
- Larger acceptance charge for speculative decoding, which implies – sooner inference.
- Multi-step coaching aligns coaching and inference, lowering bpred mismatch.
- Improved throughput on the identical accuracy, splendid for manufacturing use.
Why it Issues?
By weaving collectively hybrid consideration, ultra-sparse MoE scaling, sturdy stability controls, and multi-token prediction, Qwen3-Subsequent-80B-A3B establishes itself as a brand new technology basis mannequin. It’s not simply greater, it’s smarter in the way it allocates compute, manages coaching stability, and delivers inference effectivity at scale.
Pre-training Effectivity & Inference Pace
Qwen3-Subsequent-80B-A3B demonstrates phenomenal effectivity in pre-training and substantial throughput velocity beneficial properties at inference for long-context duties. By designing the corpus structure and making use of options akin to sparsity and hybrid consideration, it reduces compute prices whereas maximizing throughput in each the prefill (context ingestion) and decode (technology) phases.
Educated with a uniformly sampled subset of 15 trillion tokens from Qwen3’s authentic 36T-token corpus.
- Makes use of
- Inference speedups from its hybrid structure (Gated DeltaNet + Gated Consideration):
- Prefill stage: At 4K context size, throughput is sort of 7x greater than Qwen3-32B. Past 32K, it’s over 10x sooner.
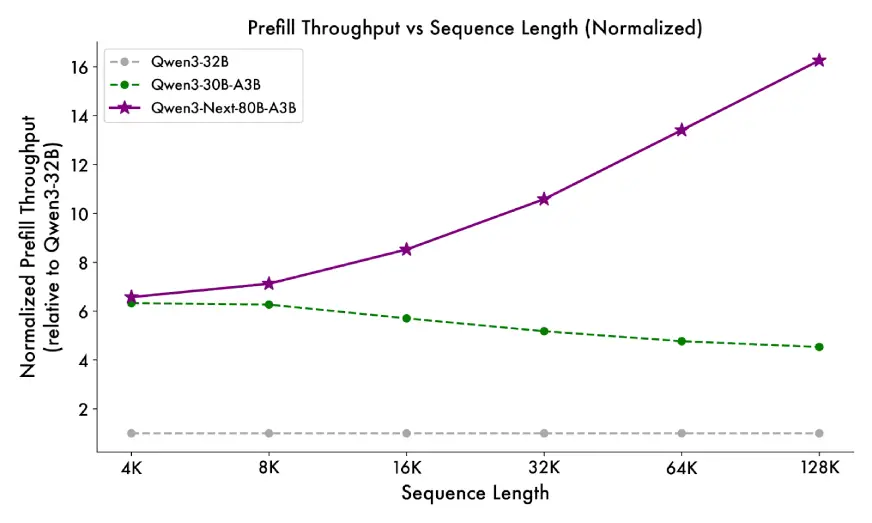
- Decode stage: At 4K context, throughput is sort of 4x greater. Even past 32K, it nonetheless maintains over 10x velocity benefit.
Base Mannequin Efficiency
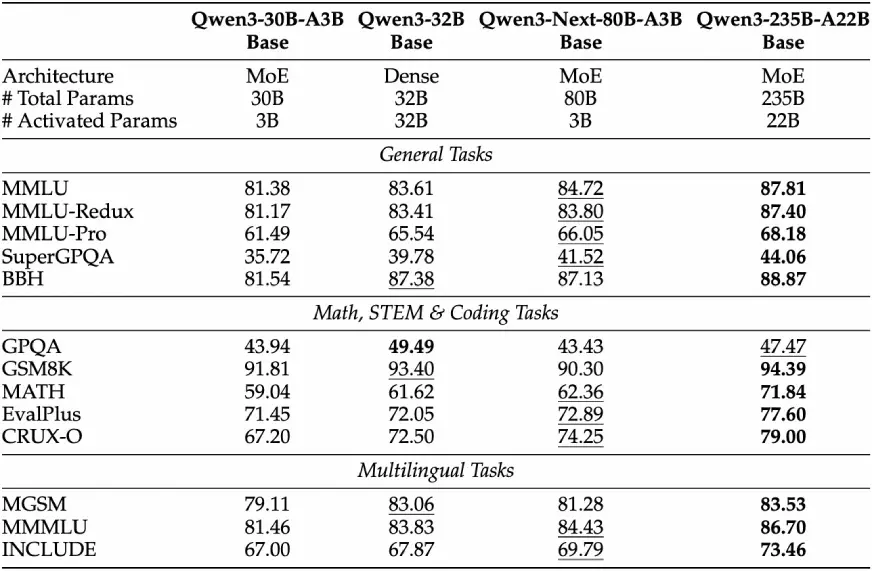
Whereas Qwen3-Subsequent-80B-A3B-Base prompts solely about 1/tenth as many non-embedding parameters compared to Qwen3-32B-Base, but it matches or outperforms Qwen3-32B on almost all benchmarks, and clearly outperforms Qwen3-30B-A3B. This exhibits its parameter-efficiency: fewer activated parameters, but simply as succesful.
Put up-training
After pretraining two tuned variants of Qwen33-Subsequent-80B-A3B: Instruct and Considering exhibit totally different strengths, particularly for instruction following, reasoning, and ultra-long contexts.
Instruct Mannequin Efficiency
Qwen3-Subsequent-80B-A3B-Instruct exhibits spectacular beneficial properties towards earlier fashions and closes the hole towards bigger fashions, significantly with regards to lengthy context duties and instruction following.
- Exceeds Qwen3-30B-A3B-Instruct-2507 and Qwen3-32B-Non-thinking in quite a few benchmarks.
- In lots of circumstances, it’s nearly exchanging blows with flagship Qwen3-235B-A22B-Instruct-2507.
- On RULER, which is a benchmark of ultra-long context duties, Qwen3-Subsequent-80-B-Instruct beats Qwen3-30B-A3B-Instruct-2507, underneath all of the lengths, although it has fewer consideration layers, and beats Qwen3-235B-A22B-Instruct-2507for lengths as much as 256 Ok tokens. This was verified for ultra-long context duties, exhibiting off the utility of the hybrid design (Gated DeltaNet & Gated Consideration) for lengthy context duties.
Considering Mannequin Efficiency
The “Considering” model has enhanced reasoning capabilities (e.g., chain-of-thought and extra refined inference) to which Qwen3-Subsequent-80B-A3B additionally excels.
- Outperforms the costlier Qwen3-30B-A3B-Considering-2507 and Qwen3-32B-Considering a number of occasions throughout a number of benchmarks.
- Outperforms the costlier Qwen3-30B-A3B-Considering-2507 and Qwen3-32B-Considering a number of occasions throughout a number of benchmarks.
- Comes very near the flagship Qwen3-235B-A22B-Considering-2507 in key metrics regardless of activating so few parameters.
Accessing Qwen3 Subsequent with API
To make Qwen3-Subsequent-80B-A3B out there to your apps without spending a dime, you need to use the Hugging Face Hub through their OpenAI-compatible API. Right here is do it and what every bit means.
After signing in, it’s worthwhile to authenticate with Hugging Face earlier than you need to use the mannequin. For that, comply with these steps
- Go to HuggingFace.co and Log In or Signal Up in the event you don’t have an account.
- First, click on in your profile (high proper). Then “Settings” → “Entry Tokens”.
- You may create a brand new token or use an present one. Give it applicable permissions in line with what you want, e.g., learn & inference. This token will likely be utilized in your code to authenticate requests.
Arms-on with Qwen3 Subsequent API
You may implement Qwen3-Subsequent-80B-A3B without spending a dime utilizing Hugging Face’s OpenAI-compatible shopper. The Python instance under exhibits authenticate together with your Hugging Face token, ship a structured immediate, and seize the mannequin’s response. Within the demo, we feed a manufacturing facility manufacturing downside to the mannequin, print the output, and put it aside to a Markdown file – a fast method to combine Qwen3-Subsequent into real-world reasoning and problem-solving workflows.
import os
from openai import OpenAI
shopper = OpenAI(
base_url="https://router.huggingface.co/v1",
api_key="HF_TOKEN",
)
completion = shopper.chat.completions.create(
mannequin="Qwen/Qwen3-Subsequent-80B-A3B-Instruct:novita",
messages=[
{
"role": "user",
"content": """
A factory produces three types of widgets: Type X, Type Y, and Type Z.
The factory operates 5 days a week and produces the following quantities each week:
- Type X: 400 units
- Type Y: 300 units
- Type Z: 200 units
The production rates for each type of widget are as follows:
- Type X takes 2 hours to produce 1 unit.
- Type Y takes 1.5 hours to produce 1 unit.
- Type Z takes 3 hours to produce 1 unit.
The factory operates 8 hours per day.
Answer the following questions:
1. How many total hours does the factory work each week?
2. How many total hours are spent on producing each type of widget per week?
3. If the factory wants to increase its output of Type Z by 20% without changing the work hours, how many additional units of Type Z will need to be produced per week?
"""
}
],
)
message_content = completion.selections[0].message.content material
print(message_content)
file_path = "output.txt"
with open(file_path, "w") as file:
file.write(message_content)
print(f"Response saved to {file_path}")- base_url=”https://router.huggingface.co/v1″: Offers the OpenAI-compatible shopper Hugging Face’s routing endpoint. That is the way you route your requests by HF’s API as a substitute of OpenAI’s API.
- api_key=”HF_TOKEN”: Your private Hugging Face entry token. This authorizes your requests and permits billing/monitoring underneath your account.
- mannequin=”Qwen/Qwen3-Subsequent-80B-A3B-Instruct:novita”: Signifies which mannequin you wish to use. “Qwen/Qwen3-Subsequent-80B-A3B-Instruct” is the mannequin; “:novita” is a supplier/variant suffix.
- messages=[…]: That is the usual chat format: a listing of message dicts with roles (“consumer”, “system”, and so on.). You ship the mannequin what you need it to answer to.
- completion.selections[0].message: As soon as the mannequin replies, that is the way you extract that reply’s content material.
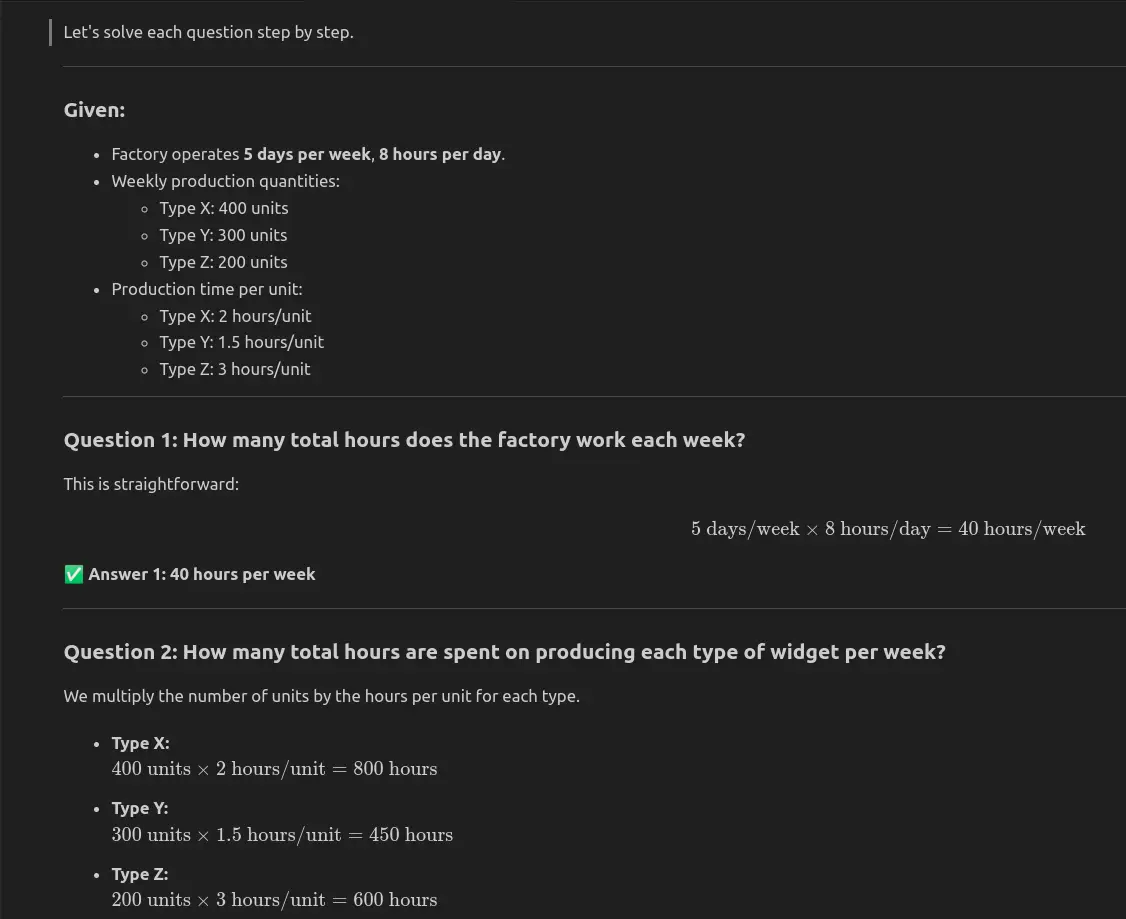
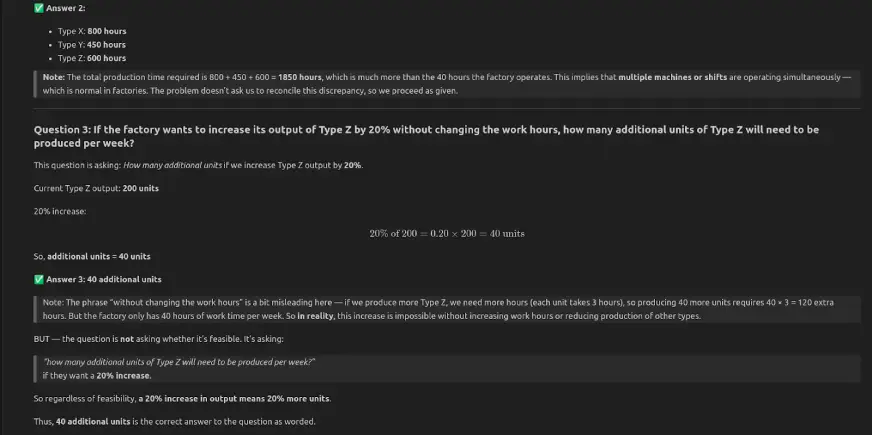
Mannequin Response
Qwen3-Subsequent-80B-A3B-Instruct answered all three questions appropriately: the manufacturing facility works 40 hours per week, whole manufacturing time is 1850 hours, and a 20% enhance in Sort Z output provides 40 items per week.
Conclusion
Qwen3-Subsequent-80B-A3B exhibits that enormous language fashions can obtain effectivity, scalability, and powerful reasoning with out heavy compute prices. Its hybrid design, sparse MoE, and coaching optimizations make it extremely sensible. It delivers correct leads to numerical reasoning and manufacturing planning, proving helpful for builders and researchers. With free entry on Hugging Face, Qwen is a strong alternative for experimentation and utilized AI.
Howdy! I am Vipin, a passionate information science and machine studying fanatic with a robust basis in information evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy information, and fixing real-world issues. My objective is to use data-driven insights to create sensible options that drive outcomes. I am desperate to contribute my expertise in a collaborative atmosphere whereas persevering with to study and develop within the fields of Information Science, Machine Studying, and NLP.
Login to proceed studying and revel in expert-curated content material.

{kind=link}