
IBM has quietly constructed a robust presence within the open-source AI ecosystem, and its newest launch exhibits why it shouldn’t be neglected. The corporate has launched two new embedding fashions—granite-embedding-english-r2 and granite-embedding-small-english-r2—designed particularly for high-performance retrieval and RAG (retrieval-augmented era) techniques. These fashions are usually not solely compact and environment friendly but additionally licensed below Apache 2.0, making them prepared for business deployment.
What Fashions Did IBM Launch?
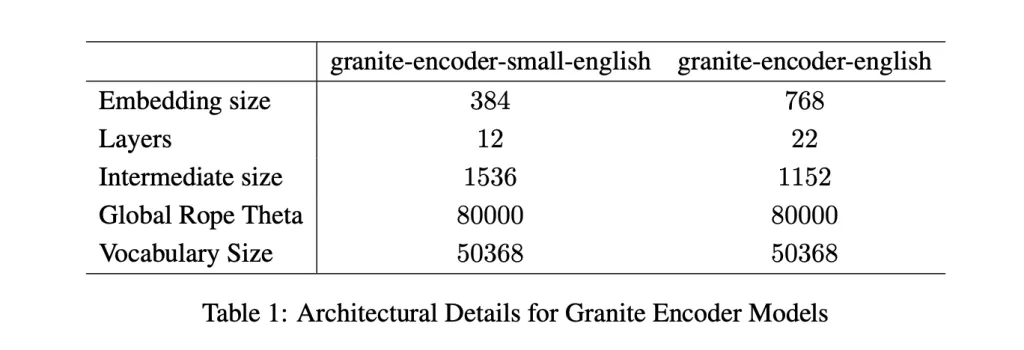
The 2 fashions goal totally different compute budgets. The bigger granite-embedding-english-r2 has 149 million parameters with an embedding measurement of 768, constructed on a 22-layer ModernBERT encoder. Its smaller counterpart, granite-embedding-small-english-r2, is available in at simply 47 million parameters with an embedding measurement of 384, utilizing a 12-layer ModernBERT encoder.
Regardless of their variations in measurement, each assist a most context size of 8192 tokens, a serious improve from the first-generation Granite embeddings. This long-context functionality makes them extremely appropriate for enterprise workloads involving lengthy paperwork and complicated retrieval duties.
What’s Contained in the Structure?
Each fashions are constructed on the ModernBERT spine, which introduces a number of optimizations:
- Alternating international and native consideration to stability effectivity with long-range dependencies.
- Rotary positional embeddings (RoPE) tuned for positional interpolation, enabling longer context home windows.
- FlashAttention 2 to enhance reminiscence utilization and throughput at inference time.
IBM additionally educated these fashions with a multi-stage pipeline. The method began with masked language pretraining on a two-trillion-token dataset sourced from internet, Wikipedia, PubMed, BookCorpus, and inside IBM technical paperwork. This was adopted by context extension from 1k to 8k tokens, contrastive studying with distillation from Mistral-7B, and domain-specific tuning for conversational, tabular, and code retrieval duties.

How Do They Carry out on Benchmarks?
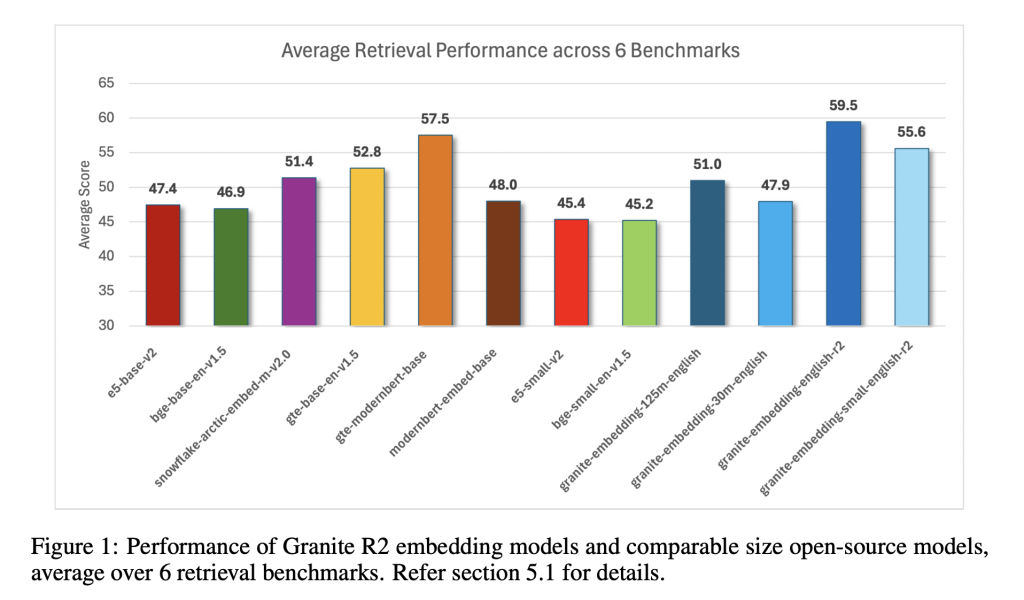
The Granite R2 fashions ship sturdy outcomes throughout extensively used retrieval benchmarks. On MTEB-v2 and BEIR, the bigger granite-embedding-english-r2 outperforms equally sized fashions like BGE Base, E5, and Arctic Embed. The smaller mannequin, granite-embedding-small-english-r2, achieves accuracy near fashions two to 3 occasions bigger, making it notably engaging for latency-sensitive workloads.
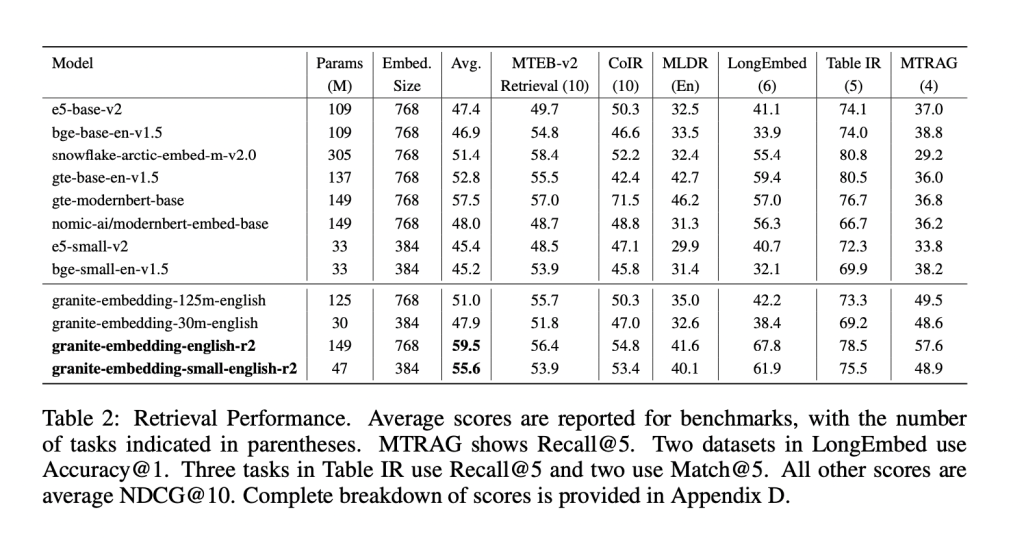
Each fashions additionally carry out nicely in specialised domains:
- Lengthy-document retrieval (MLDR, LongEmbed) the place 8k context assist is crucial.
- Desk retrieval duties (OTT-QA, FinQA, OpenWikiTables) the place structured reasoning is required.
- Code retrieval (CoIR), dealing with each text-to-code and code-to-text queries.
Are They Quick Sufficient for Giant-Scale Use?
Effectivity is likely one of the standout elements of those fashions. On an Nvidia H100 GPU, the granite-embedding-small-english-r2 encodes practically 200 paperwork per second, which is considerably quicker than BGE Small and E5 Small. The bigger granite-embedding-english-r2 additionally reaches 144 paperwork per second, outperforming many ModernBERT-based alternate options.
Crucially, these fashions stay sensible even on CPUs, permitting enterprises to run them in much less GPU-intensive environments. This stability of pace, compact measurement, and retrieval accuracy makes them extremely adaptable for real-world deployment.
What Does This Imply for Retrieval in Apply?
IBM’s Granite Embedding R2 fashions display that embedding techniques don’t want huge parameter counts to be efficient. They mix long-context assist, benchmark-leading accuracy, and excessive throughput in compact architectures. For firms constructing retrieval pipelines, data administration techniques, or RAG workflows, Granite R2 supplies a production-ready, commercially viable various to present open-source choices.
Abstract
Briefly, IBM’s Granite Embedding R2 fashions strike an efficient stability between compact design, long-context functionality, and robust retrieval efficiency. With throughput optimized for each GPU and CPU environments, and an Apache 2.0 license that allows unrestricted business use, they current a sensible various to bulkier open-source embeddings. For enterprises deploying RAG, search, or large-scale data techniques, Granite R2 stands out as an environment friendly and production-ready choice.
Take a look at the Paper, granite-embedding-small-english-r2 and granite-embedding-english-r2. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}