
It looks as if each different week, there’s a brand new AI mannequin making waves, and the tempo is just choosing up. The newest to catch my eye, and plenty of others within the AI neighborhood, is Qwen3-Subsequent. It didn’t arrive with a splashy marketing campaign, however relatively a quiet, but impactful, presence on Hugging Face. With a measly 80 billion parameters and a 32K token context window, it delivers greater than 10x larger throughput — attaining excessive effectivity in each coaching and inference. It appears like a real leap ahead for open-source AI.
However what precisely is Qwen3-Subsequent, and why is it producing a lot buzz? And extra importantly, how does it stack up towards the titans we’ve grown accustomed to? Let’s dive in and discover what makes this mannequin so particular.
What’s Qwen3-Subsequent?
At its core, Qwen3-Subsequent-80B-A3B is Alibaba’s latest massive language mannequin, designed to push the boundaries of efficiency, effectivity, and context understanding. Constructed on hybrid fashions + linear consideration for tremendous lengthy context dealing with, it boasts 80 billion whole parameters. However its actual genius lies in its selective energy. As a substitute of activating all these parameters for each job, it intelligently makes use of solely about 3 billion at a time. This provides it the 80B (max parameters) and A3B, which is the minimal parameters, in its mannequin title. Consider it like having an enormous library of specialists, the place solely essentially the most related specialists are known as upon for a given drawback.
This unimaginable effectivity is the muse upon which specialised variations are constructed. The Qwen3-Subsequent-Instruct mannequin is tuned for general-purpose instruction-following, inventive technology, and on a regular basis duties, whereas the Qwen3-Subsequent-Pondering mannequin is fine-tuned to sort out complicated, multi-step reasoning challenges. So, you don’t simply get a quicker, less expensive operation; you get a framework that assembles completely different groups of specialists for distinct missions, whether or not it’s following directions easily or diving into deep, analytical thought.
Key Options of Qwen3-Subsequent
Key Options of Qwen3-Subsequent embrace:
- Hybrid Consideration (3:1 combine): 75% Gated DeltaNet (linear consideration) for effectivity + 25% Gated Consideration for recall. Optimized with gated head dimensions and partial rotary embeddings.
- Extremely-Sparse MoE: 80B whole params, solely ~3B lively per step. 512 specialists, 10+1 activated per inference. International load-balancing retains coaching secure and environment friendly.
- Coaching Stability: Output gating prevents consideration sinks; Zero-Centered RMSNorm improves norm management; weight decay and truthful router initialization scale back instability.
- Multi-Token Prediction (MTP): Improves speculative decoding acceptance, aligns coaching with inference, and boosts throughput with out sacrificing accuracy.
- Effectivity Positive aspects: Makes use of
- Base Mannequin Power: Regardless of activating just one/tenth of Qwen3-32B’s parameters, it matches or beats it throughout most benchmarks.
- Instruct Mannequin: Robust in instruction-following and ultra-long context duties; rivals Qwen3-235B for lengths as much as 256K tokens.
- Pondering Mannequin: Excels in reasoning, chain-of-thought, and analytical duties; comes near Qwen3-235B-Pondering whereas being less expensive to run.
How you can entry Qwen3-Subsequent?
Alibaba has made Qwen3-Subsequent remarkably accessible. The next are among the methods of accessing it:
- Official Internet App: The simplest approach to strive it’s at Qwen’s net interface at chat.qwen.ai.
- API Entry: Builders can entry Qwen3-Subsequent through its official API. It’s designed to be OpenAI-compatible, so in the event you’ve used OpenAI’s instruments earlier than, integration ought to really feel acquainted. Each the Instruct and Pondering fashions API could be accessed right here.
- Hugging Face: For individuals who wish to run it regionally or fine-tune it, the uncooked weights can be found beneath an open license. That is the place the true energy of open-source comes into play, permitting for personalisation and deeper exploration. Qwen3-Subsequent could be accessed right here.
Arms-On: Testing the Mettle
Sufficient phrases; time for some motion! Right here, I’d be testing the capabilities of Qwen-Subsequent throughout a number of duties:
- Agentic Capabilities
- Coding Capabilities
- Multimodal Capabilities
1. Agentic Capabilities
Immediate: “I learn a analysis paper about K2 Assume, a brand new LLM. Discover the related analysis paper after which write a weblog explaining the principle parts of the analysis paper. Lastly, create a LinkedIn publish and an Instagram publish speaking about the identical”
Response:
-

Weblog Part
-

LinkedIn Publish
2. Coding Capabilities
Immediate: “Create an internet site that could be a mixture of Reddit and Instagram.”
The enter file could be discovered right here.
Response:
You’ll be able to see the created web site your self through this deployed hyperlink.
3. Multimodal Capabilities
Immediate: “Undergo the contents of this video SRT and in 5 traces clarify to me what is occurring within the video. Lastly, write a immediate to generate an appropriate cowl picture for this video.”
The file supplied as enter could be accessed right here.
Response:
Picture Generated:

Verdict
My expertise with the most recent Qwen3-Subsequent mannequin has been largely constructive. Whereas it may appear a bit sluggish primarily based on Qwen’s personal benchmarks, in observe, it feels faster than most reasoning fashions. It understands duties effectively, follows directions carefully, and delivers sturdy outcomes with effectivity. The one downside is that it doesn’t but auto-trigger its built-in instruments—for instance, testing generated code requires manually enabling the artifact software, and document-based picture technology wants the picture software chosen individually. That mentioned, QwenChat provides practically each software you might need, and mixed with Qwen3-Subsequent’s extra pure responses in comparison with its counterparts, it’s a mannequin I see myself spending rather more time with.
Qwen3-Subsequent: Benchmarks and Efficiency
You’d suppose: 80b parameters solely! That’s like 1 / 4 of the state-of-the-art mannequin’s parameters. Certainly, it reveals up in its efficiency, proper?
That is the place Qwen3-Subsequent turns the tables. As a substitute of providing a downsampled model of the most recent fashions which can be out there on the market, it goes shoulder-to-shoulder with them by way of their efficiency. And the benchmarks hit this level house.
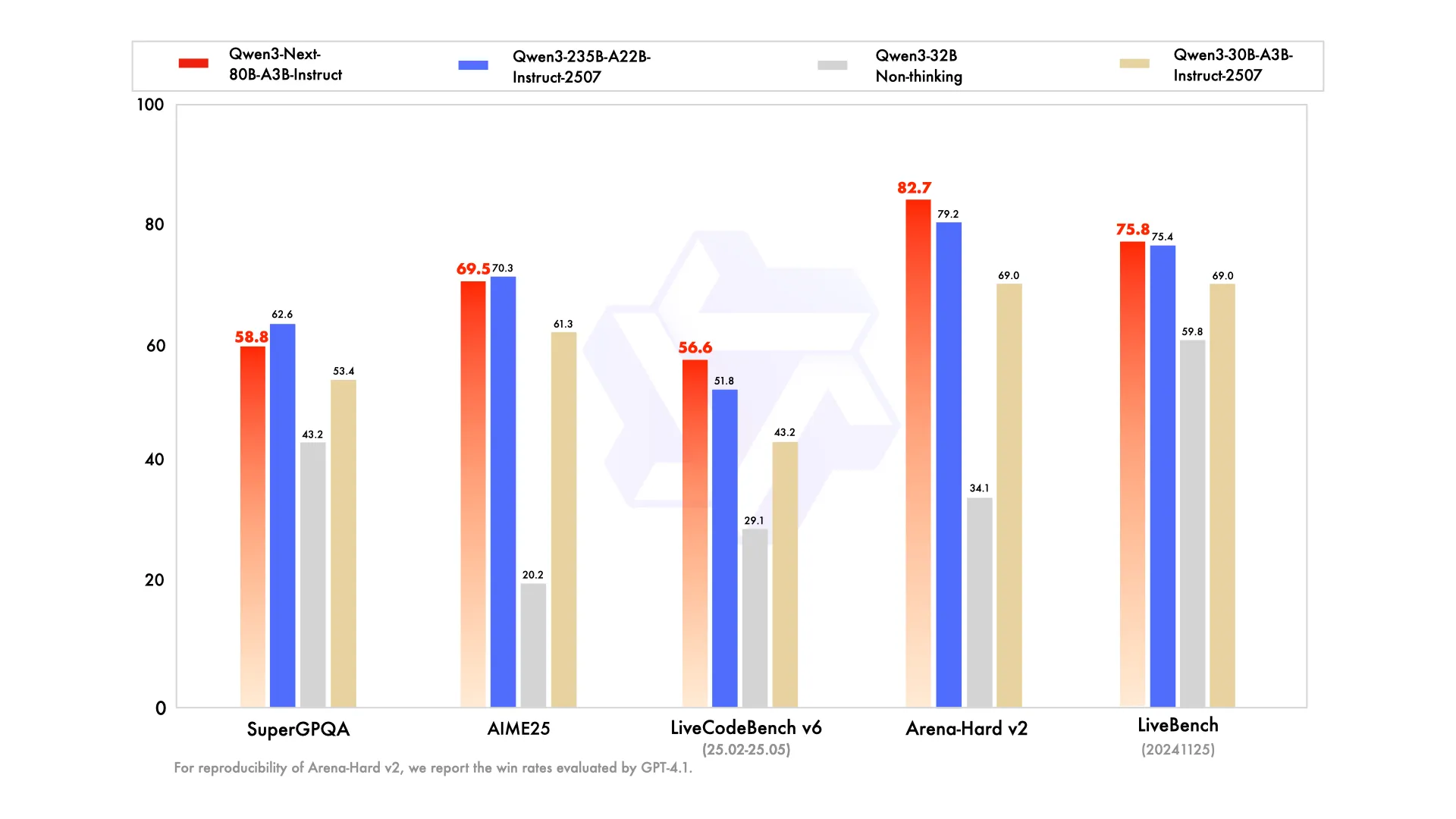
The efficiency of this optimized mannequin is corresponding to Qwen’s earlier flagship fashions. Extra notably, on sure complicated reasoning benchmarks, it has even been noticed to surpass Google’s Gemini-2.5-Flash-Pondering. It is a important achievement, significantly given its deal with effectivity and long-context processing, suggesting that “smarter” can certainly be “leaner.”
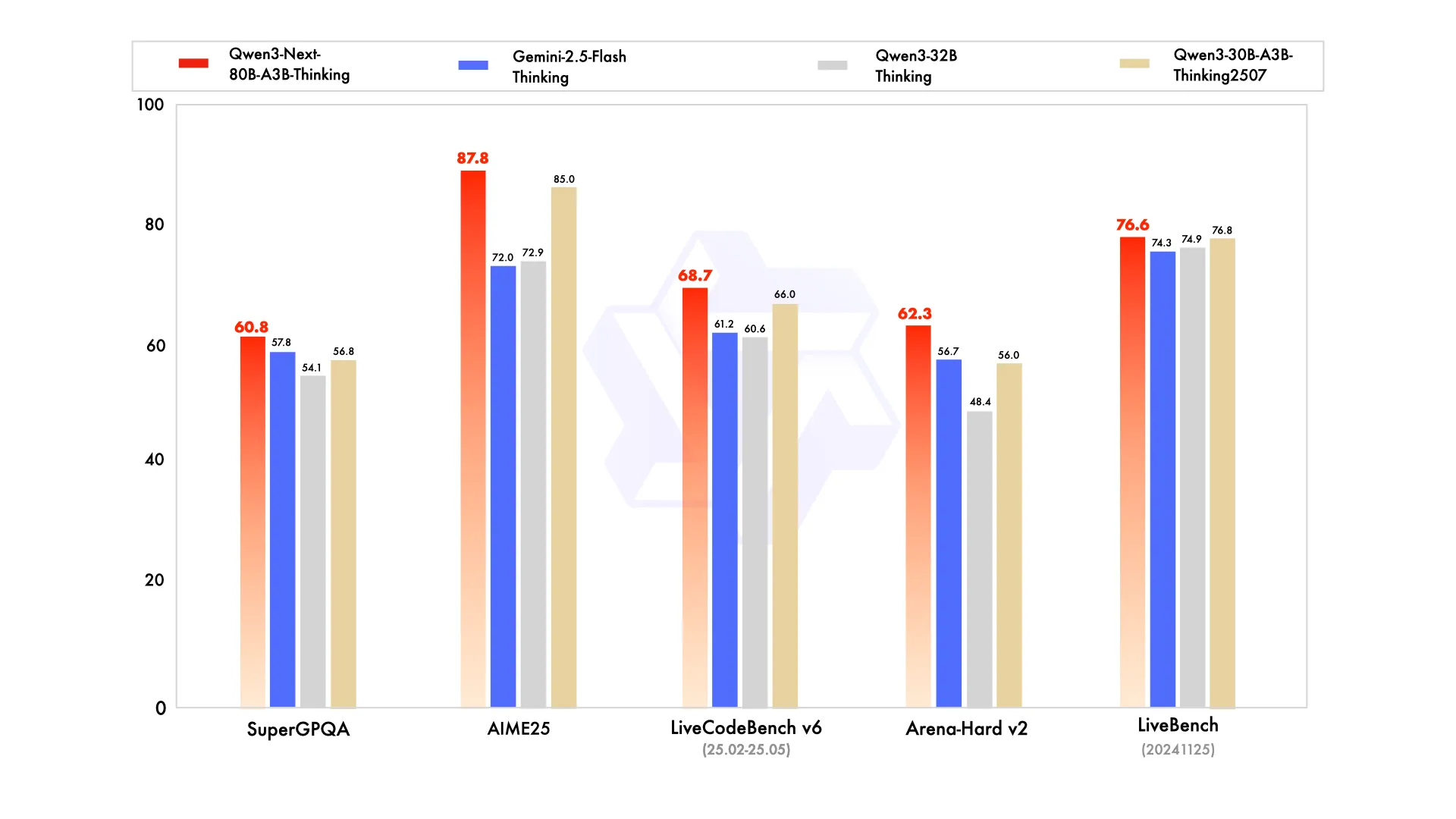
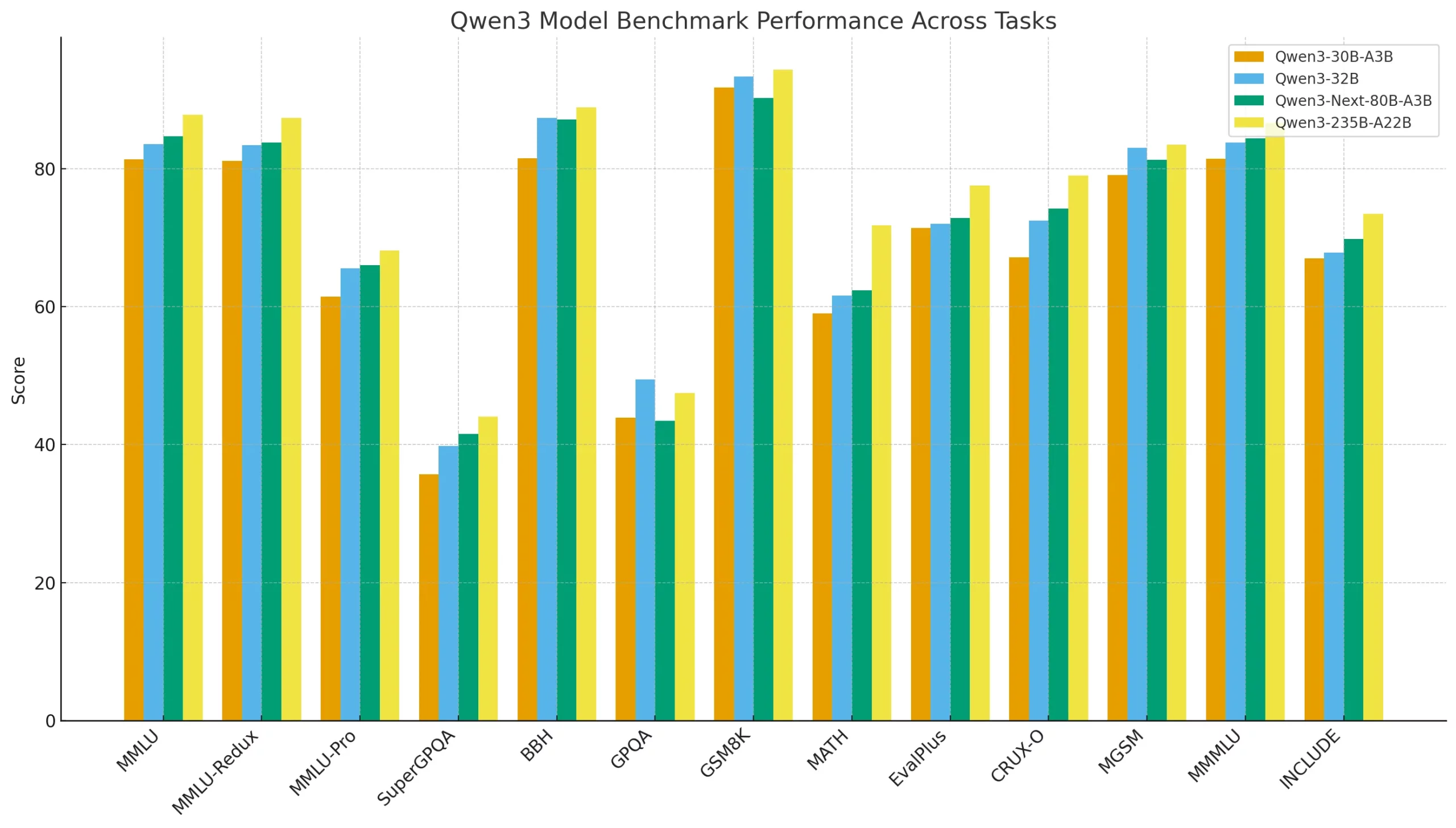
However what in regards to the efficiency throughout business benchmarks? There too, Qwen-Subsequent produces favorable outcomes. The desk under compares the efficiency of various Qwen3 fashions throughout quite a lot of benchmarks. It reveals how the newer Qwen3-Subsequent-80B-A3B stacks up towards smaller fashions like Qwen3-30B-A3B, a dense baseline (Qwen3-32B), and the large Qwen3-235B-A22B. The metrics span common reasoning (MMLU, BBH), math and coding duties (GSM8K, MATH, EvalPlus), and multilingual evaluations. It highlights not simply uncooked functionality, but additionally the trade-offs between dense and sparse Combination-of-Specialists (MoE) architectures.
The Highway Forward
Qwen3-Subsequent isn’t simply one other massive mannequin; it’s a blueprint for a extra sustainable and accessible AI future. By masterfully mixing completely different architectural strategies, the Qwen workforce has proven that we are able to obtain top-tier efficiency with out the brute-force method of merely scaling up dense fashions.
This supplies a promising outlook for many who don’t home whole workstations for coaching their fashions. With a transparent emphasis on optimization, the times of endlessly scaling {hardware} to up the ante are gone.
For builders and companies, this implies extra energy at a decrease value, quicker inference for higher person experiences, and the liberty to innovate that solely open-source can present. That is greater than only a good mannequin; it’s the beginning of a brand new and thrilling journey.
Continuously Requested Questions
A. Alibaba’s newest massive language mannequin makes use of a Sparse Combination-of-Specialists design. It has 80B parameters however solely prompts ~3B per job, making it environment friendly and cost-effective.
A. It makes use of a hybrid consideration mechanism that may natively course of as much as 256,000 tokens, enabling it to work with whole books or massive paperwork.
A. You’ll be able to entry it through Qwen’s net app (chat.qwen.ai), by means of their API, or obtain the uncooked weights from Hugging Face.
A. There’s an Instruct model for common duties and a Pondering model tuned for reasoning and analytical purposes.
A. Benchmarks present it competes with Alibaba’s earlier flagships and even surpasses Google’s Gemini-2.5-Flash-Pondering on sure reasoning benchmarks.
I concentrate on reviewing and refining AI-driven analysis, technical documentation, and content material associated to rising AI applied sciences. My expertise spans AI mannequin coaching, knowledge evaluation, and knowledge retrieval, permitting me to craft content material that’s each technically correct and accessible.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}