
Reinforcement Studying is a kind of machine studying by which an agent learns to behave by interacting with an surroundings, performing actions, and getting suggestions within the type of reward or penalty. Relatively than being instructed what to do, the agent finds out the optimum technique by trial and error, attempting to maximise cumulative rewards in the long term. It alternates between exploration of novel actions and exploitation of acquainted good ones, adjusts in line with altering circumstances, and incessantly faces delayed rewards requiring long-term planning.
Reinforcement Studying Structure is based on a continuing suggestions cycle between an surroundings and an agent. The agent reads the state of the surroundings, selects an motion primarily based on its coverage (its technique for making selections), and applies it. The surroundings reacts by altering to a distinct state and issuing a reward or penalty. As time progresses, the agent alters its coverage primarily based on this suggestions to optimize long-term cumulative rewards. Key elements are the coverage ( choose actions), the worth perform (predicting future rewards), and probably an surroundings mannequin for planning.
Fundamental forms of Reinforcement Studying:
- Coverage-Primarily based Reinforcement Studying
Coverage-based approaches bypass the worth perform and be taught a coverage immediately, i.e., a mapping from states to actions. These approaches are particularly helpful to be used in high-dimensional or steady motion areas. They be taught the coverage with strategies reminiscent of gradient ascent. REINFORCE and Proximal Coverage Optimization (PPO) are examples of common algorithms used on this class, offering stability and coaching effectivity.
- Mannequin-Primarily based Reinforcement Studying
Mannequin-based strategies consist of making an surroundings mannequin that estimates the following state and reward primarily based on a present state and motion. The agent makes use of this mannequin to cause about future penalties and resolve its actions. This strategy is probably extra sample-efficient than model-free strategies. Some examples are Dyna-Q, which mixes planning and studying, and Monte Carlo Tree Search, utilized in game-playing brokers.
- Actor-Critic Strategies
Actor-Critic strategies mix some great benefits of value-based and policy-based approaches. The actor selects what motion to carry out, and the critic judges how nicely the motion was chosen via a worth perform. Double construction diminishes variance and enhances studying stability. A3C (Asynchronous Benefit Actor-Critic) and DDPG (Deep Deterministic Coverage Gradient) algorithms are mostly utilized in steady management issues.
Reinforcement Studying Structure:
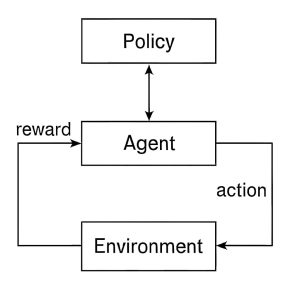
The diagram depicts the essential construction of a reinforcement studying system, displaying how an agent learns to behave optimally by interacting with its surroundings. On the high, the coverage determines the agent’s decisions by mapping states to actions. The agent, proven centrally, applies this coverage to decide on an motion that it then performs within the surroundings. The surroundings responds with a reward given in suggestions type, which is a sign of the success of the carried out motion. This reward is fed again to the agent so it might modify its coverage and make higher selections sooner or later. The coverage of cyclical stream from agent to agent, agent to surroundings via motion, and surroundings to agent via reward completely describes trial-and-error studying attribute of reinforcement studying. Step by step, this cycle allows the agent to enhance its plan and obtain most cumulative rewards via ongoing interplay and studying.

{kind=link}