
Have you ever ever questioned how your telephone understands voice instructions or suggests the proper phrase, even with out an web connection? We’re in the course of a significant AI shift: from cloud-based processing to on-device intelligence. This isn’t nearly pace; it’s additionally about privateness and accessibility. On the heart of this shift is EmbeddingGemma, Google’s new open embedding mannequin. It’s compact, quick, and designed to deal with giant quantities of knowledge straight in your machine.
On this weblog, we’ll discover what EmbeddingGemma is, its key options, easy methods to use it, and the functions it may possibly energy. Let’s dive in!
What Precisely is an “Embedding Mannequin”?
Earlier than we dive into the small print, let’s break down a core idea. After we educate a pc to know language, we can not simply feed it phrases as a result of computer systems solely course of numbers. That’s the place an embedding mannequin is available in. It really works like a translator, changing textual content right into a collection of numbers (a vector) that captures that means and context.
Consider it as a fingerprint for textual content. The extra comparable two items of textual content are, the nearer their fingerprints will likely be in a multi-dimensional house. This easy thought powers functions like semantic search (discovering that means quite than simply key phrases) and chatbots that retrieve probably the most related solutions.
Understanding EmbeddingGemma
So, what makes EmbeddingGemma particular? It’s all about doing extra with much less. Constructed by Google DeepMind, the mannequin has simply 308 million parameters. Which may sound large, however within the AI world it’s thought of light-weight. This compact dimension is its power, permitting it to run straight on a smartphone, laptop computer, or perhaps a small sensor with out counting on a knowledge heart connection.
This capacity to work on-device is greater than only a neat function. It represents an actual paradigm shift.
Key Options
- Unmatched Privateness: Your knowledge stays in your machine. The mannequin processes every part domestically, so that you don’t have to fret about your non-public queries or private data being despatched to the cloud.
- Offline Performance: No web? No drawback. Functions constructed with EmbeddingGemma can carry out advanced duties like looking out by means of your notes or organizing your pictures, even once you’re fully offline.
- Unimaginable Velocity: With no latency from sending knowledge backwards and forwards to a server, the response time is instantaneous.
And right here’s the cool half: regardless of its compact dimension, EmbeddingGemma delivers state-of-the-art efficiency.
- It holds the best rating for an open multilingual textual content embedding mannequin below 500M on the Huge Textual content Embedding Benchmark (MTEB).
- Its efficiency is corresponding to or exceeds that of fashions practically twice its dimension.
- This is because of its extremely environment friendly design, which might run on lower than 200MB of RAM with quantization and gives a low inference latency of sub-15ms on EdgeTPU for 256 enter tokens, making it appropriate for real-time functions.
Additionally Learn: The way to Select the Proper Embedding for Your RAG Mannequin?
How is EmbeddingGemma Designed?
One in all EmbeddingGemma’s standout options is Matryoshka Illustration Studying (MRL). This provides builders the flexibleness to regulate the mannequin’s output dimensions primarily based on their wants. The total mannequin produces an in depth 768-dimensional vector for optimum high quality, however it may be diminished to 512, 256, and even 128 dimensions with little loss in accuracy. This adaptability is particularly worthwhile for resource-constrained units, enabling sooner similarity searches and decrease storage necessities.
Now that we perceive what makes EmbeddingGemma highly effective, let’s see it in motion.
Embedding Gemma: Handson
Let’s create a RAG utilizing Embedding Gemma and LangGraph.
Set 1: Obtain the Dataset
!gdown 1u8ImzhGW2wgIib16Z_wYIaka7sYI_TGKStep 2: Load and Preprocess the Information
from pathlib import Path
import json
from langchain.docstore.doc import Doc
# ---- Configure dataset path (replace if wanted) ----
DATA_PATH = Path("./rag_demo_docs052025.jsonl") # similar file identify as earlier pocket book
if not DATA_PATH.exists():
increase FileNotFoundError(
f"Anticipated dataset at {DATA_PATH}. "
"Please place the JSONL file right here or replace DATA_PATH."
)
# Load JSONL
raw_docs = []
with DATA_PATH.open("r", encoding="utf-8") as f:
for line in f:
raw_docs.append(json.hundreds(line))
# Convert to Doc objects with metadata
paperwork = []
for i, d in enumerate(raw_docs):
sect = d.get("sectioned_report", {})
textual content = (
f"Difficulty:n{sect.get('Difficulty','')}nn"
f"Impression:n{sect.get('Impression','')}nn"
f"Root Trigger:n{sect.get('Root Trigger','')}nn"
f"Advice:n{sect.get('Advice','')}"
)
paperwork.append(Doc(page_content=textual content))
print(paperwork[0].page_content)
Step 3: Create a Vector DB
Use the preprocessed knowledge and Embedding Gemma to create a vector db:
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
persist_dir = "./reports_db"
assortment = "reports_db"
embedder = HuggingFaceEmbeddings(model_name="google/embeddinggemma-300m")
# Construct or rebuild the vector retailer
vectordb = Chroma.from_documents(
paperwork=paperwork,
embedding=embedder,
collection_name=assortment,
collection_metadata={"hnsw:house": "cosine"},
persist_directory=persist_dir
)Step 4: Create a Hybrid Retriever (Semantic + BM25 key phrase retriever)
# Reopen deal with (demonstrates persistence)
vectordb = Chroma(
embedding_function=embedder,
collection_name=assortment,
persist_directory=persist_dir,
)
vectordb._collection.rely()
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.retrievers import ContextualCompressionRetriever
# Base semantic retriever (cosine sim + threshold)
semantic = vectordb.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"ok": 5, "score_threshold": 0.2},
)
# BM25 key phrase retriever
bm25 = BM25Retriever.from_documents(paperwork)
bm25.ok = 3
# Ensemble (hybrid)
hybrid_retriever = EnsembleRetriever(
retrievers=[bm25, semantic],
weights=[0.6, 0.4],
ok=5
)
# Fast check
hybrid_retriever.invoke("What are the key points in finance approval workflows?")[:3]
Step 5: Create Nodes
Now let’s create two nodes – one for Retrieval and the opposite for Era:
Defining LangGraph State
from typing import Listing, TypedDict, Annotated
from langgraph.graph import StateGraph, START, END
from langchain.docstore.doc import Doc as LCDocument
# We maintain overwrite semantics for all keys (no reducers wanted for appends right here).
class RAGState(TypedDict):
query: str
retrieved_docs: Listing[LCDocument]
reply: strNode 1: Retrieval
def retrieve_node(state: RAGState) -> RAGState:
question = state["question"]
docs = hybrid_retriever.invoke(question) # returns checklist[Document]
return {"retrieved_docs": docs}Node 2: Era
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
PROMPT = ChatPromptTemplate.from_template(
"""You might be an assistant for Analyzing inner stories for Operational Insights.
Use the next items of retrieved context to reply the query.
If you do not know the reply or there isn't a related context, simply say that you do not know.
give a well-structured and to the purpose reply utilizing the context data.
Query:
{query}
Context:
{context}
"""
)
def _format_docs(docs: Listing[LCDocument]) -> str:
return "nn".be part of(d.page_content for d in docs) if docs else ""
def generate_node(state: RAGState) -> RAGState:
query = state["question"]
docs = state.get("retrieved_docs", [])
context = _format_docs(docs)
immediate = PROMPT.format(query=query, context=context)
resp = llm.invoke(immediate)
return {"reply": resp.content material}
Construct the Graph and Edges
builder = StateGraph(RAGState)
builder.add_node("retrieve", retrieve_node)
builder.add_node("generate", generate_node)
builder.add_edge(START, "retrieve")
builder.add_edge("retrieve", "generate")
builder.add_edge("generate", END)
graph = builder.compile()
from IPython.show import Picture, show, display_markdown
show(Picture(graph.get_graph().draw_mermaid_png()))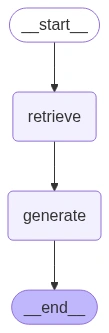
Step 6: Run the Mannequin
Now let’s run some examples on the RAG that we constructed:
example_q = "What are the key points in finance approval workflows?"
final_state = graph.invoke({"query": example_q})
display_markdown(final_state["answer"], uncooked=True)
example_q = "What brought on bill SLA breaches within the final quarter?"
final_state = graph.invoke({"query": example_q})
display_markdown(final_state["answer"], uncooked=True)
example_q = "How did AutoFlow Perception enhance SLA adherence?"
final_state = graph.invoke({"query": example_q})
display_markdown(final_state["answer"], uncooked=True)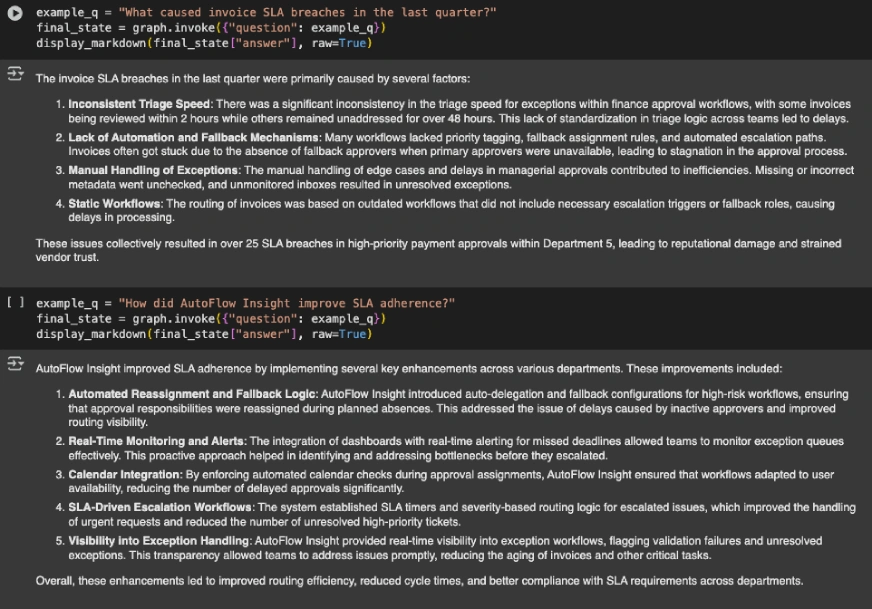
Try all the pocket book right here.
Embedding Gemma: Efficiency Benchmarks
Now that we now have seen EmbeddingGemma in motion, let’s shortly see the way it performs towards its friends. The next chart breaks down the variations amongst all the highest embedding fashions:
- EmbeddingGemma achieves a imply MTEB rating of 61.15, clearly beating a lot of the fashions of comparable and even bigger dimension.
- The mannequin excels in retrieval, classification with stable clustering.
- It beats bigger fashions like multilingual-e5-large (560M) and bge-m3(568M).
- The one mannequin that beats its scores is Qwen-Embedding-0.6B which is almost double its dimension.
Additionally Learn: 14 Highly effective Strategies Defining the Evolution of Embedding
Embedding Gemma vs OpenAI Embedding Fashions
An essential comparability is between EmbeddingGemma and OpenAI’s embedding fashions. OpenAI embeddings are typically less expensive for small tasks, however for bigger, scalable functions, EmbeddingGemma has the benefit. One other key distinction is context dimension: OpenAI embeddings assist as much as 8k tokens, whereas EmbeddingGemma presently helps as much as 2k tokens.
Functions of EmbeddingGemma
The true energy of EmbeddingGemma lies within the big range of functions it allows. By producing high-quality textual content embeddings straight on the machine, it powers a brand new technology of privacy-centric and environment friendly AI experiences.
Listed here are a couple of key functions:
- RAG: As mentioned earlier, EmbeddingGemma can be utilized to construct a strong RAG pipeline that works totally offline. You possibly can create a private AI assistant that may flick thru your paperwork and supply exact, grounded solutions. That is particularly helpful for creating chatbots that may reply questions primarily based on a particular, non-public information base.
- Semantic Search & Data Retrieval: As an alternative of simply trying to find key phrases, you possibly can construct search capabilities that perceive the that means behind a person’s question. That is good for looking out by means of giant doc libraries, your private notes, or an organization’s information base, guaranteeing you discover probably the most related data shortly and precisely.
- Classification & Clustering: EmbeddingGemma can be utilized to construct on-device functions for duties like classifying texts (e.g., sentiment evaluation, spam detection) or clustering them into teams primarily based on their similarities (e.g., organizing paperwork, market analysis).
- Semantic Similarity & Advice Programs: The mannequin’s capacity to measure the similarity between texts is a core element of advice engines. For instance, it may possibly suggest new articles or merchandise to a person primarily based on their studying historical past, all whereas conserving their knowledge non-public.
- Code Retrieval & Truth Verification: Builders can use EmbeddingGemma to construct instruments that retrieve related code blocks primarily based on a pure language question. It may also be utilized in fact-checking programs to retrieve paperwork that assist or refute a press release, enhancing the reliability of data.
Conclusion
Google has not simply launched a mannequin; they’ve launched a toolkit. EmbeddingGemma integrates with frameworks like sentence-transformers, llama.cpp, and LangChain, making it simple for builders to construct highly effective functions. The longer term is native. EmbeddingGemma allows privacy-first, environment friendly, and quick AI that runs straight on units. It democratizes entry and places highly effective instruments within the fingers of billions.
Anu Madan is an professional in tutorial design, content material writing, and B2B advertising, with a expertise for reworking advanced concepts into impactful narratives. Together with her give attention to Generative AI, she crafts insightful, modern content material that educates, conjures up, and drives significant engagement.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}