
Determination Tree Studying’s structure is a tree-like, hierarchical construction employed in each classification and regression in supervised machine studying. It begins with a root node, which is the entire dataset and the place to begin of the primary cut up in keeping with a selected characteristic. From there, the tree splits into inner resolution nodes, the place every of them is a take a look at on an attribute, and branches, which signify the outcomes of these exams. The algorithm repeats recursively, splitting the information into subsets till reaching leaf nodes, the place the terminal output is represented as both a category label or a numeric worth.
Such an structure is constructed primarily based on algorithms comparable to CART (Classification and Regression Bushes), which choose the optimum splits primarily based on analysis of standards comparable to Gini impurity or entropy. The purpose is to provide a mannequin imitating human decision-making by posing a sequence of questions that progressively give extra specific conclusions. The benefit of interpretability and ease of this group make resolution bushes broadly utilized in predictive analytics and information mining.
Varieties of Determination Tree Studying:
- Classification Tree
A Classification Tree is created to unravel issues the place the output variable is a class, i.e., it’s a member of a specific class or class. The tree divides the information primarily based on characteristic values that may finest distinguish the classes. For every node, the algorithm selects the characteristic that offers the utmost info achieve or decreases Gini impurity most. This goes on till the information has been separated into pure subsets, or leaf nodes, that are the ultimate class prediction. For example, it could distinguish between emails and non-spams.
- Regression Tree
A Regression Tree is employed when the goal variable is steady, i.e., it has numerical values. Slightly than dividing information into classes, it estimates a numeric worth by averaging the values in every leaf node. The tree splits information in keeping with options that scale back the variance or imply squared error within the goal variable. Every cut up is designed to provide subsets as homogeneous as doable primarily based on the numerical output. For instance: Predicting home costs, forecasting gross sales.
Determination Tree Studying Diagram:
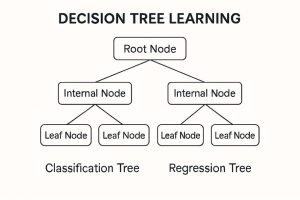
The determine reveals the resolution tree studying structure, a supervised studying machine mannequin that applies to each classification and regression studying. On the apex is the root node, which symbolizes your complete information set and makes the primary resolution primarily based on a selected characteristic. It divides into inner nodes, every symbolizing a degree of resolution which additional divides the information alongside particular characteristic values. These inner nodes subsequently department out to leaf nodes that give the terminal output both a category label for a classification tree or a numerical worth for a regression tree. The left half of the diagram illustrates a classification tree the place the choices find yourself in discrete classes, and the precise half illustrates a regression tree the place the outputs are steady values. The framework is binary and symmetrical, highlighting the way in which information recursively splits so as to make a predictive judgment. The graphical framework serves to demystify how resolution bushes work by way of the gradual elimination of potentialities primarily based on characteristic divisions.
Conclusion:
Determination bushes are usually not solely mannequin they’re reasoning frameworks. Their readability, interpretableness, and adaptability make them a place to begin for information science, notably when understanding and actionable outcomes are paramount. From classifying emails to forecasting actual property values, resolution bushes present a step-by-step, logical course of to grasp the information.

{kind=link}