
Massive language fashions (LLMs) have reshaped AI reasoning, with parallel considering and self-consistency strategies typically cited as pivotal advances. Nonetheless, these methods face a elementary trade-off: sampling a number of reasoning paths boosts accuracy however at a steep computational value. A group of researchers from Meta AI and UCSD introduce Deep Assume with Confidence (DeepConf), a brand new AI approachthat almost eliminates this trade-off. DeepConf delivers state-of-the-art reasoning efficiency with dramatic effectivity features—reaching, for instance, 99.9% accuracy on the grueling AIME 2025 math competitors utilizing the open-source GPT-OSS-120B, whereas requiring as much as 85% fewer generated tokens than typical parallel considering approaches.
Why DeepConf?
Parallel considering (self-consistency with majority voting) is the de facto commonplace for enhancing LLM reasoning: generate a number of candidate options, then choose the commonest reply. Whereas efficient, this methodology has diminishing returns—accuracy plateaus and even declines as extra paths are sampled, as a result of low-quality reasoning traces can dilute the vote. Furthermore, producing a whole lot or hundreds of traces per question is dear, each in time and compute.
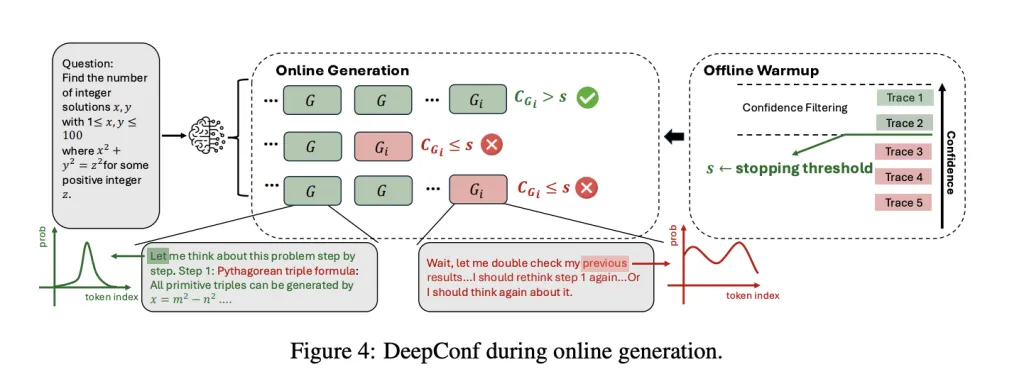
DeepConf tackles these challenges by exploiting the LLM’s personal confidence indicators. Relatively than treating all reasoning traces equally, it dynamically filters out low-confidence paths—both throughout era (on-line) or afterward (offline)—utilizing solely essentially the most dependable trajectories to tell the ultimate reply. This technique is model-agnostic, requires no coaching or hyperparameter tuning, and will be plugged into any current mannequin or serving framework with minimal code modifications.
How DeepConf Works: Confidence as a Information
DeepConf introduces a number of developments in how confidence is measured and used:
- Token Confidence: For every generated token, compute the unfavorable common log-probability of the top-k candidates. This offers an area measure of certainty.
- Group Confidence: Common token confidence over a sliding window (e.g., 2048 tokens), offering a smoothed, intermediate sign of reasoning high quality.
- Tail Confidence: Concentrate on the ultimate section of the reasoning hint, the place the reply typically resides, to catch late breakdowns.
- Lowest Group Confidence: Establish the least assured section within the hint, which regularly indicators reasoning collapse.
- Backside Percentile Confidence: Spotlight the worst segments, that are most predictive of errors.
These metrics are then used to weight votes (high-confidence traces depend extra) or to filter traces (solely the highest η% most assured traces are stored). In on-line mode, DeepConf stops producing a hint as quickly as its confidence drops beneath a dynamically calibrated threshold, dramatically lowering wasted computation.
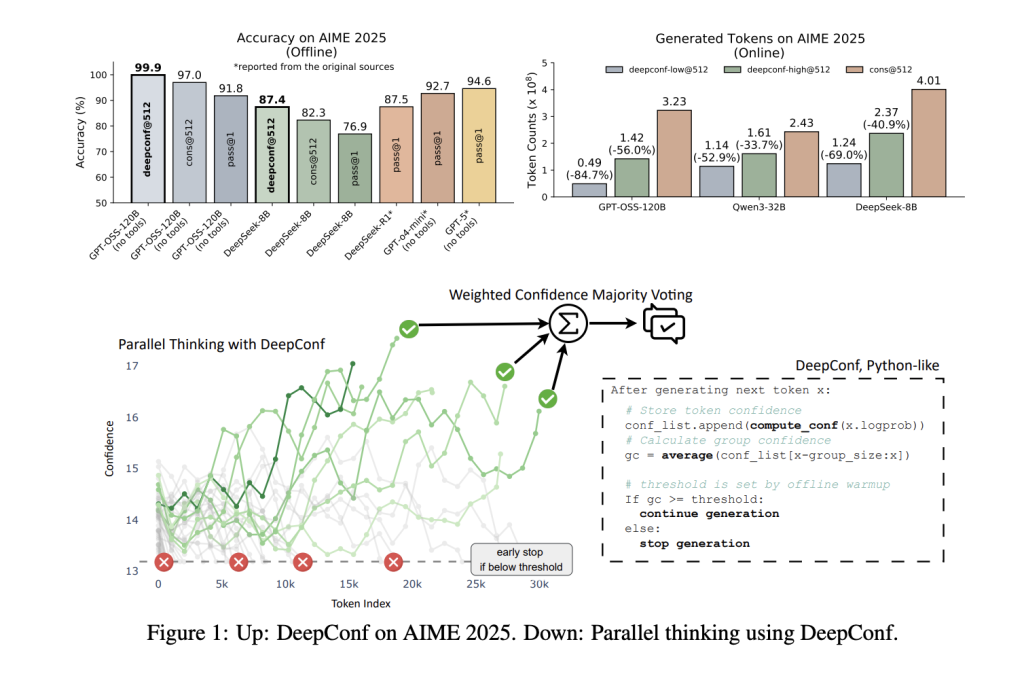
Key Outcomes: Efficiency & Effectivity
DeepConf was evaluated throughout a number of reasoning benchmarks (AIME 2024/2025, HMMT 2025, BRUMO25, GPQA-Diamond) and fashions (DeepSeek-8B, Qwen3-8B/32B, GPT-OSS-20B/120B). The outcomes are hanging:
| Mannequin | Dataset | Go@1 Acc | Cons@512 Acc | DeepConf@512 Acc | Tokens Saved |
|---|---|---|---|---|---|
| GPT-OSS-120B | AIME 2025 | 91.8% | 97.0% | 99.9% | -84.7% |
| DeepSeek-8B | AIME 2024 | 83.0% | 86.7% | 93.3% | -77.9% |
| Qwen3-32B | AIME 2024 | 80.6% | 85.3% | 90.8% | -56.0% |
Efficiency increase: Throughout fashions and datasets, DeepConf improves accuracy by as much as ~10 share factors over commonplace majority voting, typically saturating the benchmark’s higher restrict.
Extremely-efficient: By early-stopping low-confidence traces, DeepConf reduces the full variety of generated tokens by 43–85%, with no loss (and sometimes a acquire) in closing accuracy.
Plug & play: DeepConf works out of the field with any mannequin—no fine-tuning, no hyperparameter search, and no modifications to the underlying structure. You may drop it into your current serving stack (e.g., vLLM) with ~50 traces of code.
Straightforward to deploy: The tactic is carried out as a light-weight extension to current inference engines, requiring solely entry to token-level logprobs and some traces of logic for confidence calculation and early stopping.
Easy Integration: Minimal Code, Most Influence
DeepConf’s implementation is kind of easy. For vLLM, the modifications are minimal:
- Lengthen the logprobs processor to trace sliding-window confidence.
- Add an early-stop test earlier than emitting every output.
- Go confidence thresholds by way of the API, with no mannequin retraining.
This permits any OpenAI-compatible endpoint to assist DeepConf with a single further setting, making it trivial to undertake in manufacturing environments.
Conclusion
Meta AI’s DeepConf represents a leap ahead in LLM reasoning, delivering each peak accuracy and unprecedented effectivity. By dynamically leveraging the mannequin’s inside confidence, DeepConf achieves what was beforehand out of attain for open-source fashions: near-perfect outcomes on elite reasoning duties, with a fraction of the computational value.
FAQs
FAQ 1: How does DeepConf enhance accuracy and effectivity in comparison with majority voting?
DeepConf’s confidence-aware filtering and voting prioritizes traces with increased mannequin certainty, boosting accuracy by as much as 10 share factors throughout reasoning benchmarks in comparison with majority voting alone. On the similar time, its early termination of low-confidence traces slashes token utilization by as much as 85%, providing each efficiency and large effectivity features in sensible deployments
FAQ 2: Can DeepConf be used with any language mannequin or serving framework?
Sure. DeepConf is totally model-agnostic and will be built-in into any serving stack—together with open-source and industrial fashions—with out modification or retraining. Deployment requires solely minimal modifications (~50 traces of code for vLLM), leveraging token logprobs to compute confidence and deal with early stopping.
FAQ 2: Does DeepConf require retraining, particular information, or complicated tuning?
No. DeepConf operates totally at inference-time, requiring no further mannequin coaching, fine-tuning, or hyperparameter searches. It makes use of solely built-in logprob outputs and works instantly with commonplace API settings for main frameworks; it’s scalable, strong, and deployable on actual workloads with out interruption.
Try the Paper and Challenge Web page. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}