
Consideration mechanism laid the inspiration for transformer architectures within the subject of pure language processing (NLP). Since its introduction, now we have witnessed a speedy evolution in NLP. In actual fact, this breakthrough has marked the start of a brand new period for Generative AI and NLP as an entire. Right now, corporations around the globe are releasing more and more superior LLMs. And every of those claims to set a brand new benchmark in efficiency, in the end shaping the way forward for LLMs and AI generally.
To actually grasp the place this way forward for LLMs is headed, it is very important perceive a few of the newest improvements influencing their improvement. On this article, we’ll discover three key developments which might be paving the trail for the following technology of LLMs. These are:
- Swish Activation Perform
- RoPE (Rotary Positional) Embeddings
- Infini Consideration
Let’s dive into every of those subjects and discover how they contribute to the evolving panorama of huge language fashions.
Swish Activation Features
As information scientists, we’ve encountered varied activation features. These vary from the fundamental ones just like the linear and step features, to extra superior features launched with the rise of neural networks, reminiscent of tanh and the extensively used ReLU. Whereas ReLU introduced important enhancements, its limitations led to the event of enhanced alternate options like Leaky ReLU, ELU, and others.
Apparently, most of those activation features have been designed by people. Nevertheless, the Swish activation operate stands out, because it was found by a machine. Fascinating, proper? What’s extra fascinating is that Swish activation performs a key function in shaping the way forward for LLMs. Should you’re conversant in pc imaginative and prescient, you might have come throughout the YOLO-NAS mannequin. Here’s what it means.
Neural Structure Search
The NAS in YOLO-NAS stands for Neural Structure Search. It’s a approach developed by Google to automate the design of neural community architectures. NAS goals to establish the best-performing mannequin configuration for a given job. This contains selections just like the variety of layers and neurons.
In NAS, we outline each the search house (potential architectures) and the search technique (how we discover that house). It usually focuses on metrics like accuracy or mannequin dimension. Constraints are set accordingly, and quite a few experiments are run to find the optimum structure.
Notably, EfficientNet is among the profitable architectures created utilizing NAS, which leverages reinforcement studying to information its search course of.
This automated seek for environment friendly neural networks was additionally leveraged to find new activation features. Because of this, a number of promising activation operate candidates have been recognized. A few of these embody:
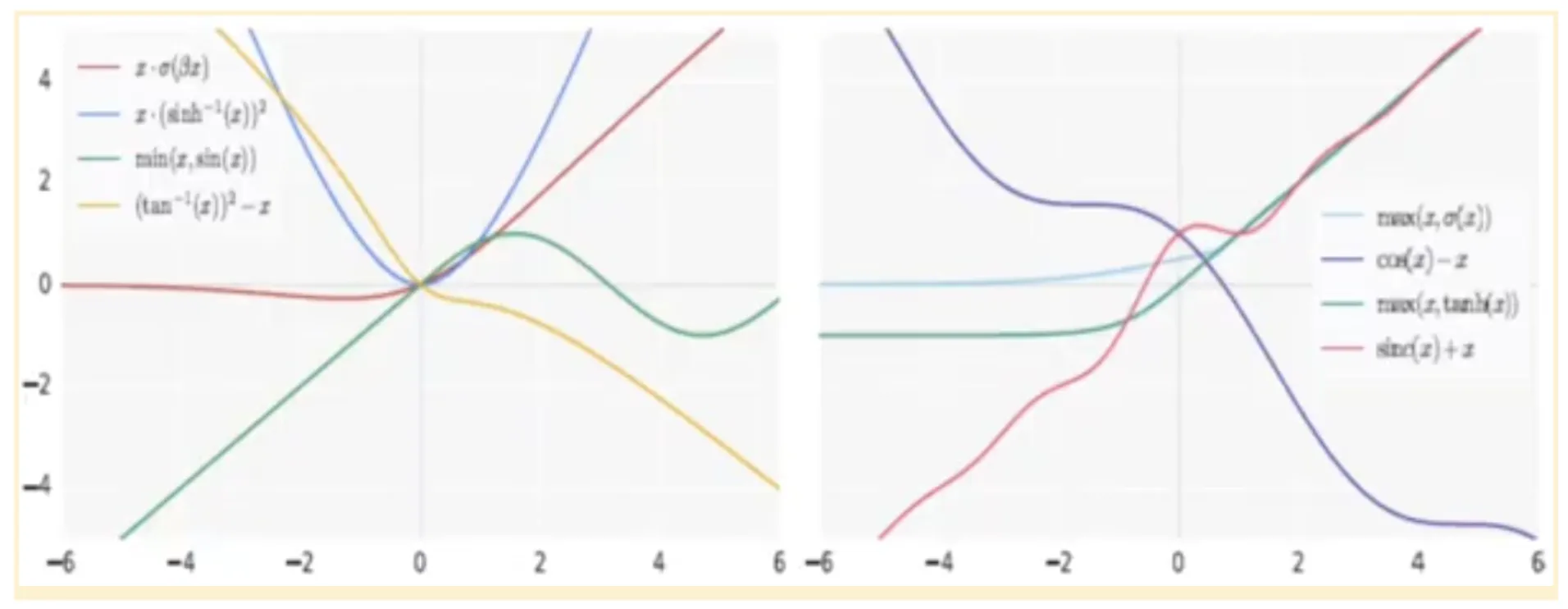
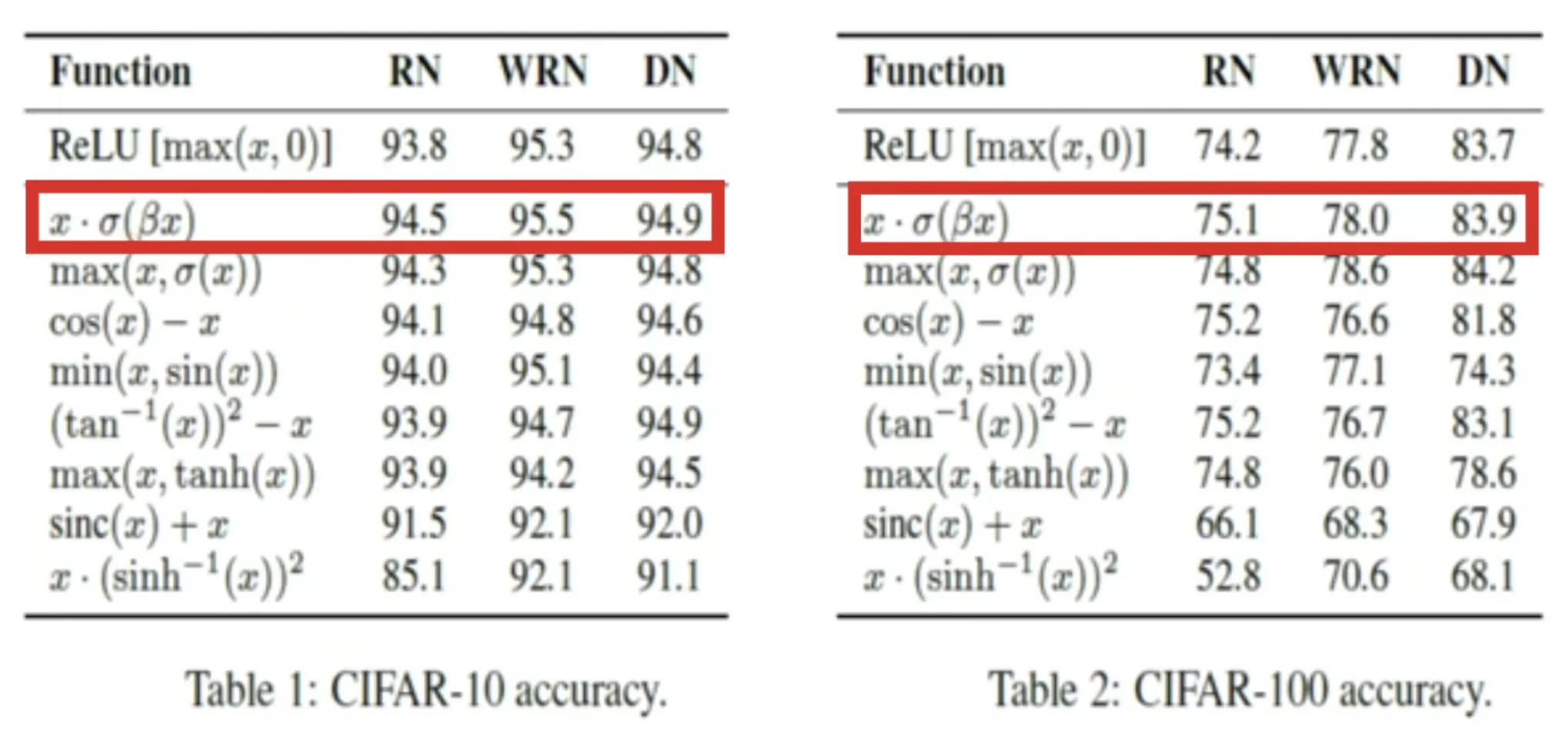
These activation features have been evaluated on benchmark datasets reminiscent of CIFAR-10 and CIFAR-100. Their efficiency was in contrast in opposition to normal fashions like ResNet, Vast ResNet, and DenseNet. It significantly centered on accuracy metrics in comparison with ReLU.
Activation features like ReLU, Leaky ReLU, ELU, and tanh are all monotonic; they both repeatedly enhance or lower from the detrimental to the constructive facet of the X-axis. Whereas Swish activation is non-monotonic. Swish activation decreases barely initially earlier than rising, making a curve that features each downward and upward slopes.
This non-monotonicity enhances the expressive energy of the community and improves gradient circulation throughout each ahead and backward passes. Because of this, fashions utilizing Swish activation present robustness to variations in weight initialisation and studying charges, main to higher general coaching stability and efficiency.
Swish activation operate appears like this f(x) = x * sigmoid(βx)
The place β right here is a continuing or a trainable parameter.
If β
If β > 1, it acts extra like a ReLU operate
Code Implementation of the Swish Perform
import numpy as np
def swish(x):
return x * (1 / (1 + np.exp(-x)))
The place is SiLU principally used?
SiLU is used within the Feed-Ahead block of every Transformer layer, particularly after the primary linear transformation, earlier than projecting again to the mannequin dimension.
This improves:
- Coaching stability
- Gradient circulation
- Ultimate mannequin efficiency (particularly in large-scale settings)
Swish activation Perform gives loads of fascinating options, in the end shaping the way forward for LLMs. These are:
- Unboundness helps do away with the vanishing gradient downside right here.
- Monotonicity may be very efficient because it incorporates each a lowering and an rising slope.
- It gives a easy curve, so a gradient exists at each level.
Let’s take a look at how SILU is carried out inside a transformer block. This code snippet gives an summary of how SiLU is utilized in ahead propagation.
class TransformerBlock(nn.Module):
def __init__(self, d_model, d_ff):
tremendous().__init__()
self.attn = MultiHeadAttention(...)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.SiLU(), # SiLU utilized right here
nn.Linear(d_ff, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def ahead(self, x):
x = x + self.attn(self.norm1(x)) # residual + consideration
x = x + self.ffn(self.norm2(x)) # residual + feedforward
return xThe Feed-Ahead Community (FFN) is answerable for studying complicated, non-linear transformations of the token embeddings. The activation operate on this FFN (traditionally ReLU, then GELU, and now SiLU) performs a vital function in including non-linearity and easy transitions, bettering studying capability.
In Meta’s LLaMA (open-source), you’ll usually discover this sample:
self.act_fn = nn.SiLU()
self.ffn = nn.Sequential(
nn.Linear(dim, hidden_dim),
self.act_fn,
nn.Linear(hidden_dim, dim)
)As an illustration, the Llama and Llama2 fashions from Meta’s Fb Analysis use Swish activation/SwiGLU for his or her activation operate. The precise particulars of GPT-4’s structure are confidential. Although it’s rumoured to make use of the sigmoid activation operate (i.e., SiLU) in its loss operate. Moreover, the SiLU activation operate can also be used within the Ultralytics YOLO (e.g. YOLOv7) fashions for object detection duties.
Now, now we have understood what the Swish activation operate is and the place it’s successfully utilised within the transformers, giving us essential insights into the way forward for LLMs. Just lately, we noticed the OpenAI GPT-oss mannequin makes use of a variant of the Swish activation operate by the title SwiGLU. SwiGLU makes use of the Swish activation operate, which is outlined as Swish(x)=x⋅σ(x) the place σ(x) is the sigmoid operate, alongside a gating mechanism much like that in GLU.
RoPE Embeddings
The Consideration Is All You Want paper, printed in 2017, launched the Transformer structure, which revolutionised the sphere of pure language processing. Since then, many new architectures have been proposed, although not all have confirmed to be equally efficient. One widespread characteristic amongst these early transformers is their reliance on sinusoidal positional embeddings to encode the place of tokens inside a sequence.
In 2022, a more practical method to positional encoding was launched: Rotary Positional Embeddings (RoPE). This system has since been adopted by a number of giant language fashions, together with PaLM, LLaMA 1, LLaMA 2, and others. That is due to its potential to higher deal with longer context lengths and protect relative place data.
You possibly can learn our in-depth article on the evolution of embeddings right here.
Absolute Positional Embeddings
The earlier methods of producing positional embeddings have been principally depending on absolute positional embeddings. In absolute positional embeddings, we characterize one phrase with its positional data. Mainly we characterize every phrase with its particular place throughout the sequence. And right here the ultimate tokens are made by summing the phrase embeddings with the positional embedding.
There have been primarily 2 methods of producing positional embeddings:
- Discovered from Information: Embedding vectors are initialised randomly after which skilled through the coaching course of. This technique is employed within the authentic transformers and in fashionable fashions like BERT, GPT, and RoBERTa.
However let’s say there’s a positional vector starting from 1 to 512. This posed an enormous downside for the reason that max size was bounded, making it arduous to utilise this logic for lengthy contexts because it couldn’t generalise it nicely. - Sinusoidal Perform: It supplied a singular positional embedding for every potential place throughout the sequence. This gives nice flexibility in dealing with various enter sizes.
It’s also obscure the sample within the methods it shifts since each the magnitude and angle change considerably.
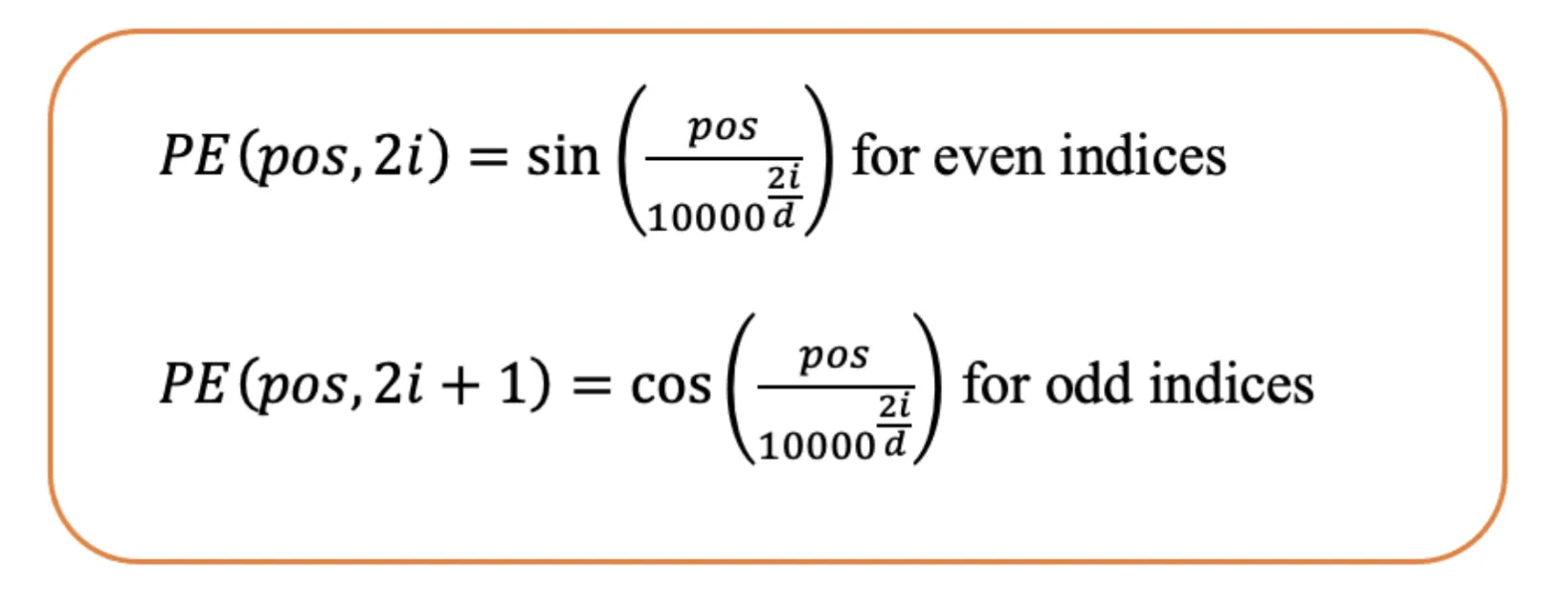
From completely different experiments, each realized and sinusoidal positional embeddings carry out equally. However one situation is that every place is handled individually. For instance, the mannequin sees the distinction between place 1 and a couple of as the identical as between place 2 and 500, despite the fact that close by positions are normally extra associated in which means.

One other factor to notice is that every token right here will get a singular positional embedding. So, if a phrase is moved to a special place within the sentence, even when its which means doesn’t change a lot, it nonetheless will get a very new positional worth. This will make it more durable for the mannequin to know and generalize.
Relative Positional Embeddings
In relative positional embeddings, we don’t characterize absolutely the place of every token. As a substitute, we learn the way far aside every pair of tokens is in a sentence. For the reason that place is determined by the pair, we will’t simply add the positional embedding to the token embedding like we do in absolute embeddings. As a substitute, we have to modify the eye mechanism itself to incorporate this relative place data.
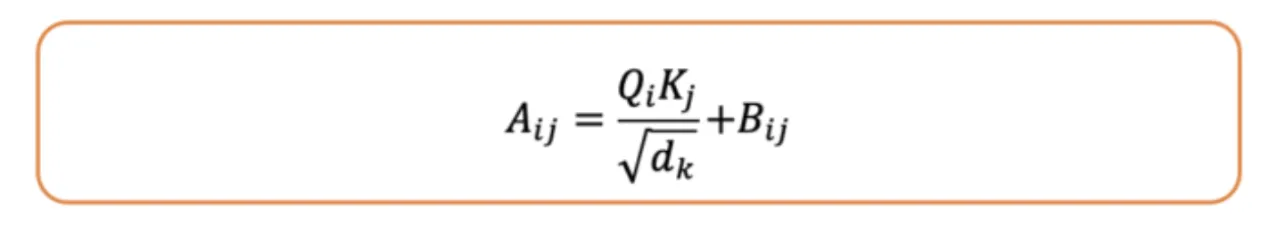
On this picture, we will see the bias matrix, which denotes the relation between the phrases with a sure distance. This B matrix created could be summed with the eye rating matrix right here.
The principle benefit of relative positional embeddings is that tokens which might be, say, 3 phrases aside will at all times be handled the identical method, irrespective of the place they seem within the sentence. This makes them helpful for dealing with lengthy sequences. Nevertheless, they’re slower as a result of they want an additional step so as to add a bias matrix to the eye scores.
Additionally, for the reason that embeddings rely on the place between every pair of tokens, we will’t simply reuse earlier key-value pairs, making it arduous to make use of key-value caching effectively. That’s why this technique isn’t extensively utilized in observe.
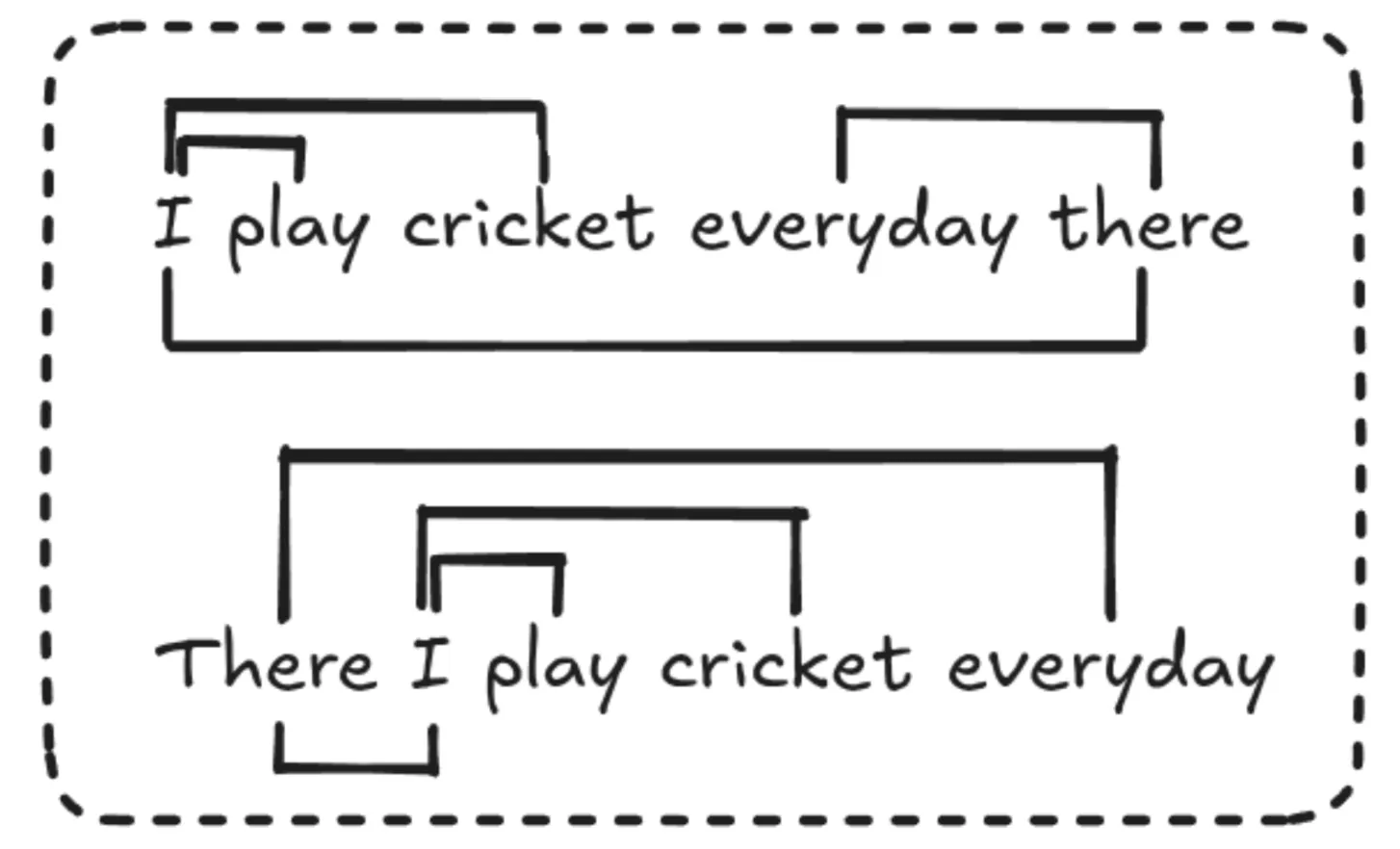
As we see right here, relative positional embeddings assist us to know the sequence order with out worrying in regards to the precise positions and have a key function to play in the way forward for LLMs.
RoPE
The Rotary Positional Embeddings mix one of the best components of absolute and relative positional embeddings. Right here in RoPE, as a substitute of including a positional vector to encode the place of a phrase in a sequence, they suggest to use rotation to the vector.
The quantity we rotate is simply an integer a number of of the place of the phrase within the sentence, so to characterize the place m within the sentence. We rotate the unique phrase vector by the angle of m occasions θ (theta). This has a number of benefits of absolute positional embeddings, like if we add extra tokens to the top of a sentence keep the identical, which makes them simpler to catch.
The quantity of rotation relies upon solely on the token’s place within the sentence, so any variety of tokens after a sure phrase doesn’t have an effect on the embedding like in absolute positional embeddings.
For eg:
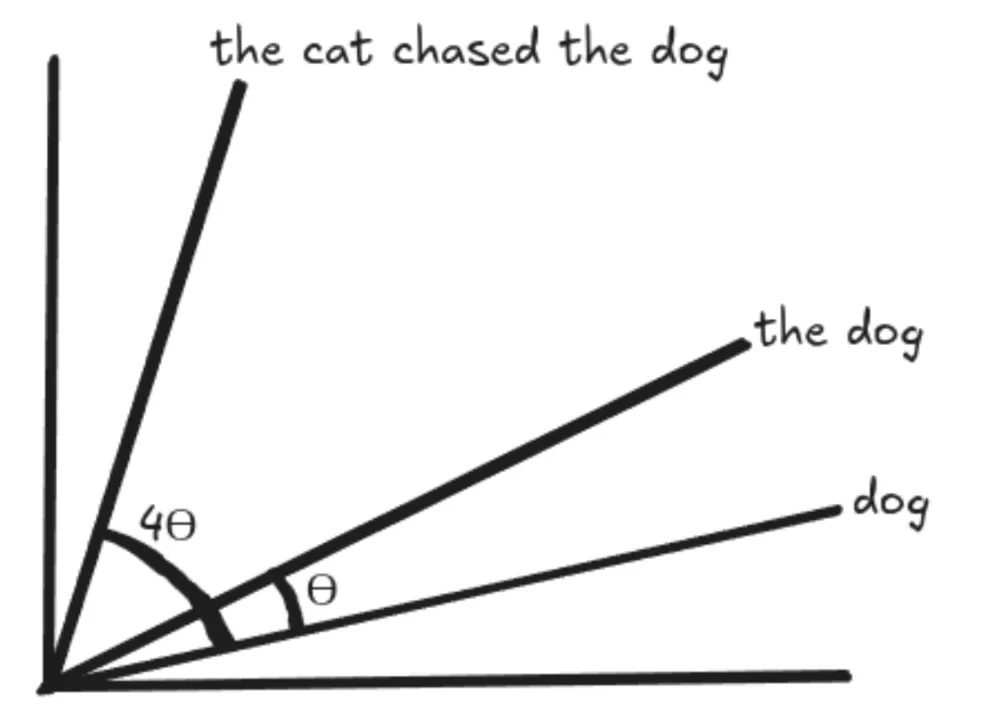
The cat chased the canine
Some days in the past, the cat chased the canine away from right here.
RoPE Matrix
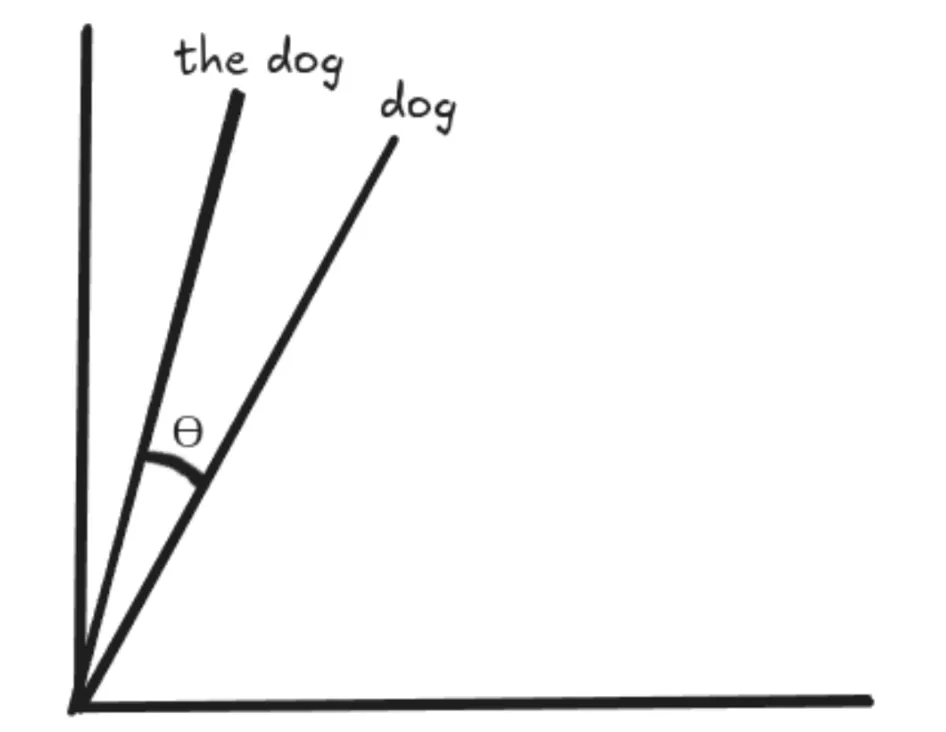
RoPE is designed in such a way that the vectors for “canine” and “the canine” are rotated by the identical quantity. Subsequently, the angle between the vectors is preserved and stays the identical in every single place. This implies the dot product between 2 vectors would stay the identical even after we add phrases in the beginning or the top of these vectors, with the idea that the gap between the vectors stays the identical.
RoPE’s essential thought is to rotate the question and key vectors based mostly on their positions within the sequence.
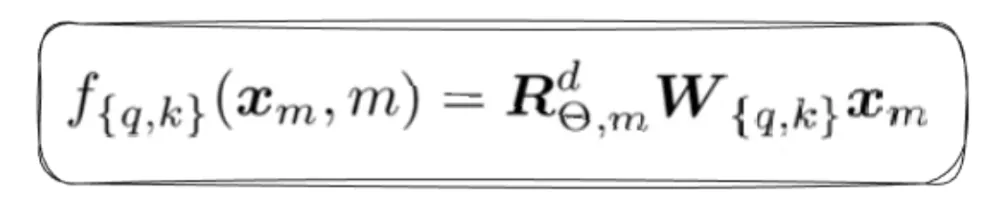
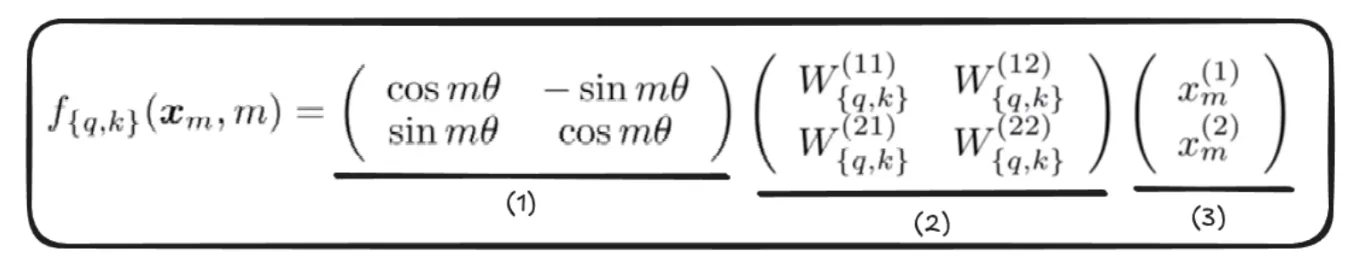
- The Rotation Matrix, which helps rotate the vector by an angle of “m x ϴ”.
- We apply linear transformations to get the question and key vector earlier than we apply a rotation matrix, such that the rotational invariance property is preserved.
Rotational invariance refers back to the property of a system or operate that continues to be unchanged beneath rotations.
Word: We solely apply rotation to question and key vectors, not the worth vectors - That is the vector we rotate.
However in actuality, the matrix is unquestionably not in 2D and might prolong as much as N dimensions like this:
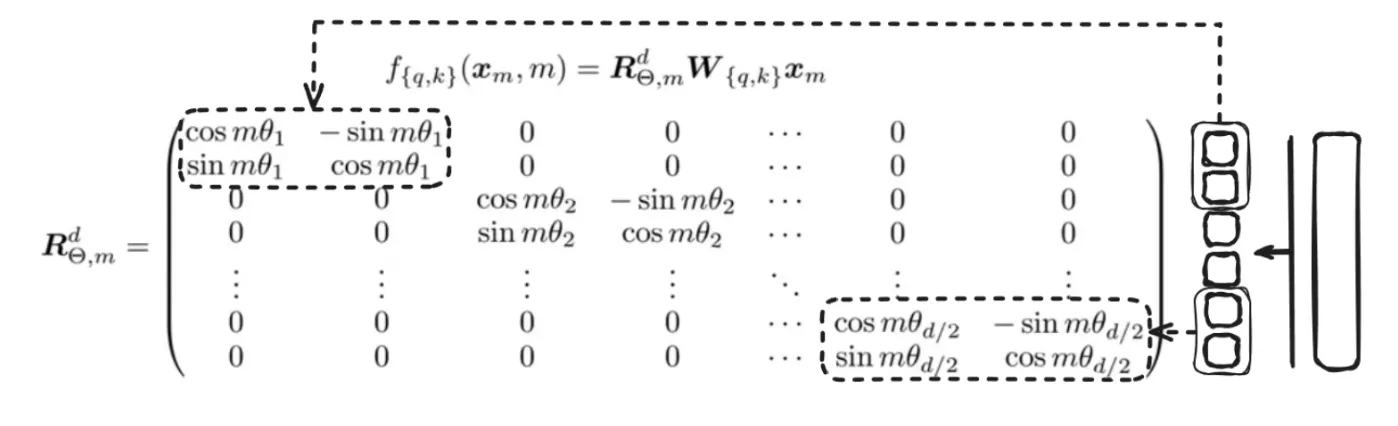
Right here, the vector is split into chunks of two and rotated by a sure m occasions θ.
However this sort of logic is absolutely dangerous as a consequence of pointless reminiscence and computation complexity. So, as a substitute of this, we’ll implement utilizing element-wise operations like this:
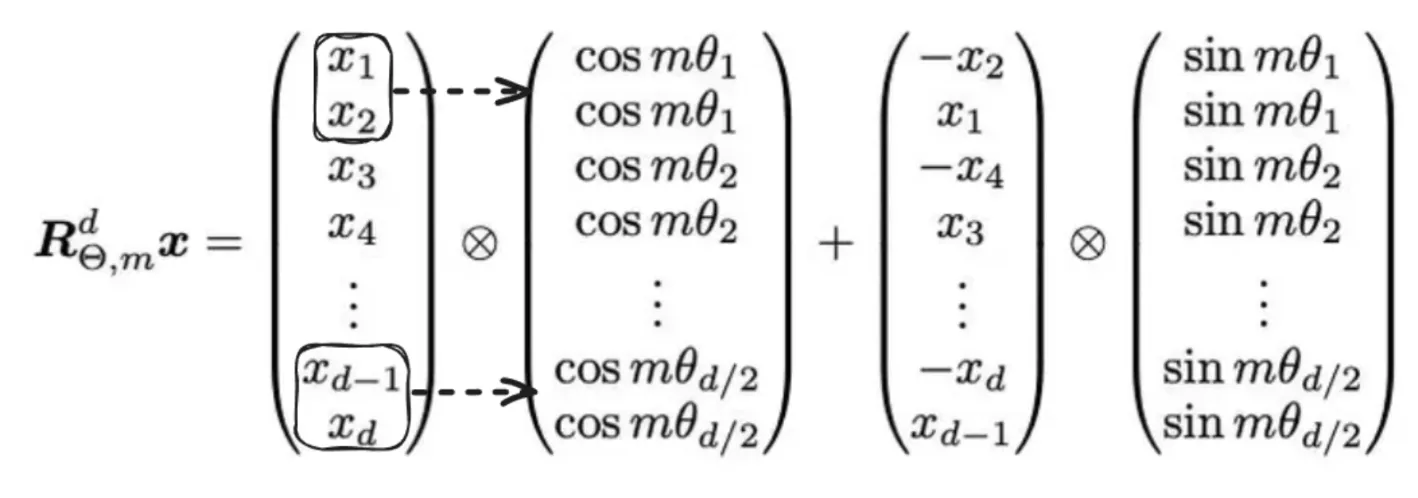
Usually, it’s assumed that the dimension of the vector is even, which is generally the case, therefore the idea of creating chunks of two right here.
These Embeddings have been utilised to coach on a number of language fashions like BERT, RoFormer, and many others., which showcased that these fashions skilled quicker with RoPE Embeddings over Sinusoidal Embeddings.
RoPE Elements
RoPE has 2 kinds of parts – Excessive Frequency and Low Frequency parts. Excessive-frequency parts are extremely delicate to positional modifications. Low-frequency parts, alternatively, are much less delicate to relative positions, which permits transformers to keep up semantic consideration over longer distances.
Subsequently, the bottom N is elevated from 10000 to 500000, which additional slows down the low-frequency parts, permitting the transformers to take care of relative tokens with giant relative distance for capturing long-range dependencies.
However we have to perceive how we will be sure RoPE could be utilised for longer context size sequences. Coaching a mannequin straight on login context may be very difficult as a consequence of coaching pace, reminiscence footprint, and lack of large-scale information. These sorts of sources are very restricted since solely the highest corporations have this potential. We can even talk about longer context lengths within the subsequent part, known as Infini Consideration, and their impression on the way forward for LLMs.
In brief: One efficient technique is to rescale the place into the coaching context size; that is known as place interpolation. This usually principally scales the place even additional, slowing down the low-frequency parts, therefore permitting for longer context-length sequence data to be saved.
Infini Consideration
Transformer fashions usually have limited-sized context home windows. Infini Consideration incorporates compressive reminiscence right into a vanilla consideration mechanism and builds in each masked native attentions and lengthy linear consideration mechanisms in a single transformer block. Consideration Mechanism comes with extra disadvantages too, like:
- It has quadratic complexity in each reminiscence and computation time.
- Limitations in scaling the transformer to longer sequences (principally, studying a very good illustration from longer sequences turns into expensive).
There have been a number of experiments earlier than the discharge of the “Go away No Context Behind: Environment friendly Infinite with Infini Consideration”. Some methods have been like doing the computation row by row, by which we’re buying and selling off computation in opposition to reminiscence, however nonetheless, now we have quadratic complexity in computation, irrespective of how we distribute it. There have been additionally makes an attempt to do linear consideration computations, which have been additionally known as linear consideration or quick weights. A number of approaches have been made to recover from this quadratic complexity bottleneck, however Infini Consideration got here forward.
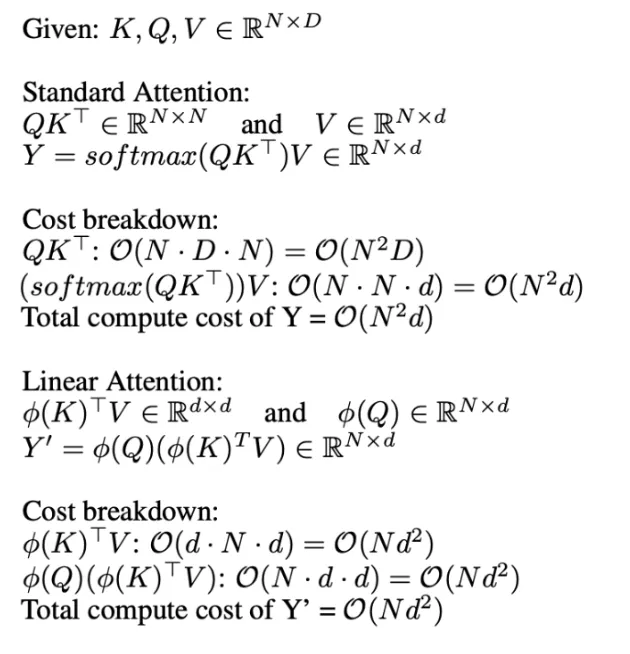
Compressive Reminiscence
Infini Consideration has a compressive reminiscence unit along with the vanilla consideration mechanism.
Compressive reminiscence programs inside Infini Consideration are designed to effectively deal with lengthy sequences by summarizing previous data in a compact kind. As a substitute of storing all previous information, they preserve a set set of parameters that act as a abstract of the sequence historical past. This abstract could be up to date over time and nonetheless retain helpful data. The important thing thought is that every time new data arrives, the reminiscence is up to date and its parameters are modified in such a method that probably the most related features of that new data are captured. This permits the mannequin to recall essential particulars later, without having to retailer or course of the whole sequence explicitly.
Because of this, each the storage and computation necessities stay inside a sure restrict, making it way more scalable for processing lengthy inputs, and therefore a key participant in shaping the way forward for LLMs.
Very lengthy sequences are damaged into “s” segments. Every of those segments is processed by a causal consideration mechanism, and an area illustration is extracted from this present section. Above this, one other illustration that has details about the sequence historical past is retrieved from compressed reminiscence. Then, the present section illustration is appended or up to date into the compressed reminiscence. Lastly, on the finish, the native illustration from the present section and the retrieved data illustration are mixed to kind a world long-range illustration.
Mainly, there are 4 essential steps – Native Illustration, Retrieval, Compressive Reminiscence Replace, and Illustration Aggregation.
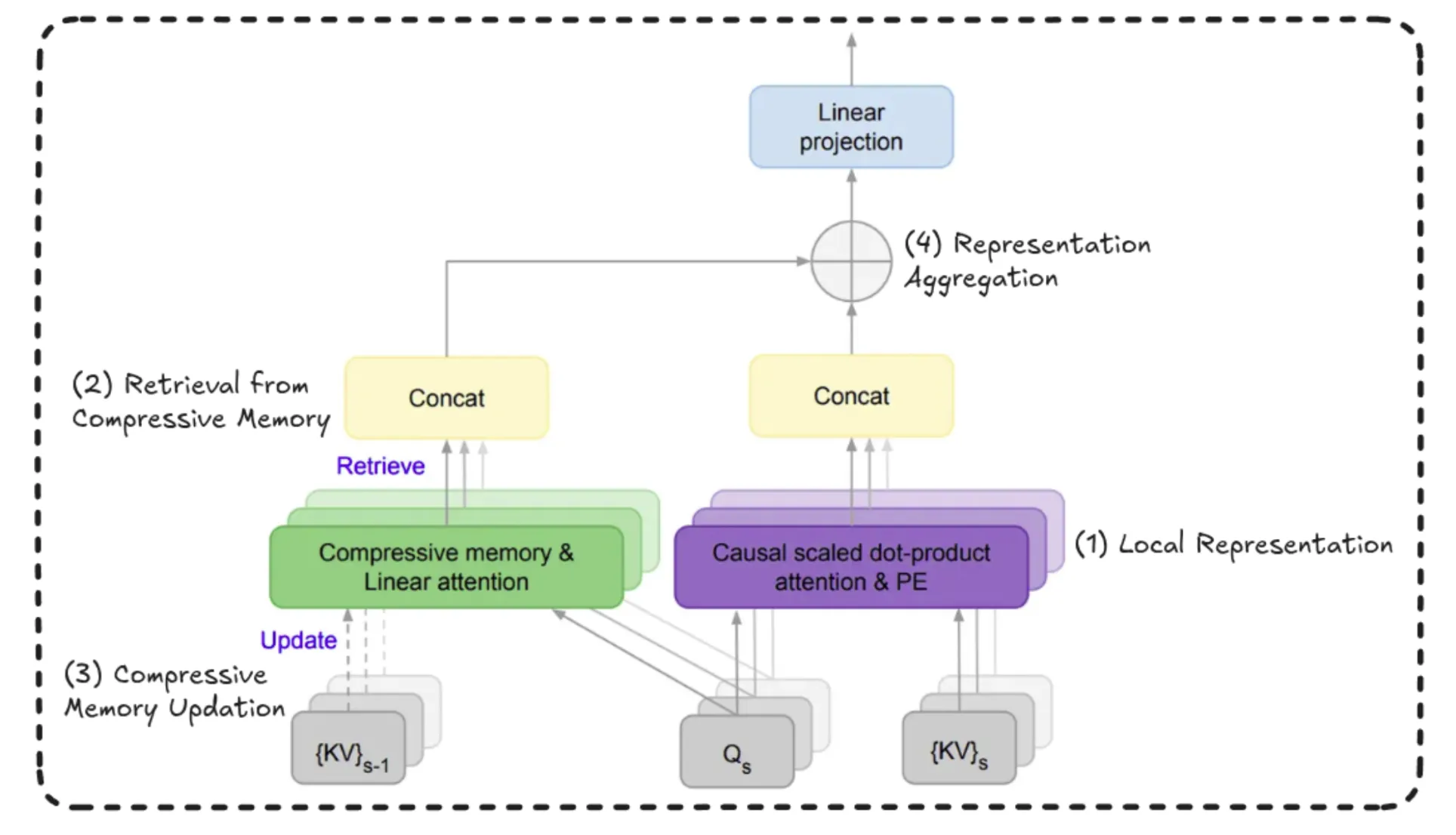
Full Workflow
Throughout the bigger context of understanding the way forward for LLMs, let’s first go over the entire workflow from the beginning, we could?
In Infini Consideration, we divide the enter sequence into a number of chunks or segments. For instance, if the section dimension is 100 tokens, we course of these first 100 tokens as one section utilizing normal consideration mechanisms. After computing the key-value pairs (consideration outputs) for this section, we retailer these representations in what’s known as a compressive reminiscence.
This reminiscence acts as a bridge between segments. For every layer and every consideration head, the mannequin takes what it has realized from the present section and provides it to this reminiscence. Then, when the following section is processed, it may possibly entry this reminiscence, serving to it retain data from earlier segments.
In brief, native representations are nonetheless computed utilizing normal consideration, however Infini Consideration enhances this by passing realized data ahead by means of a shared reminiscence construction.
This fashion of storing key worth computations like queries into key transpose form of computations into reminiscence for the previous time steps, and in some way be capable of use it for future steps.
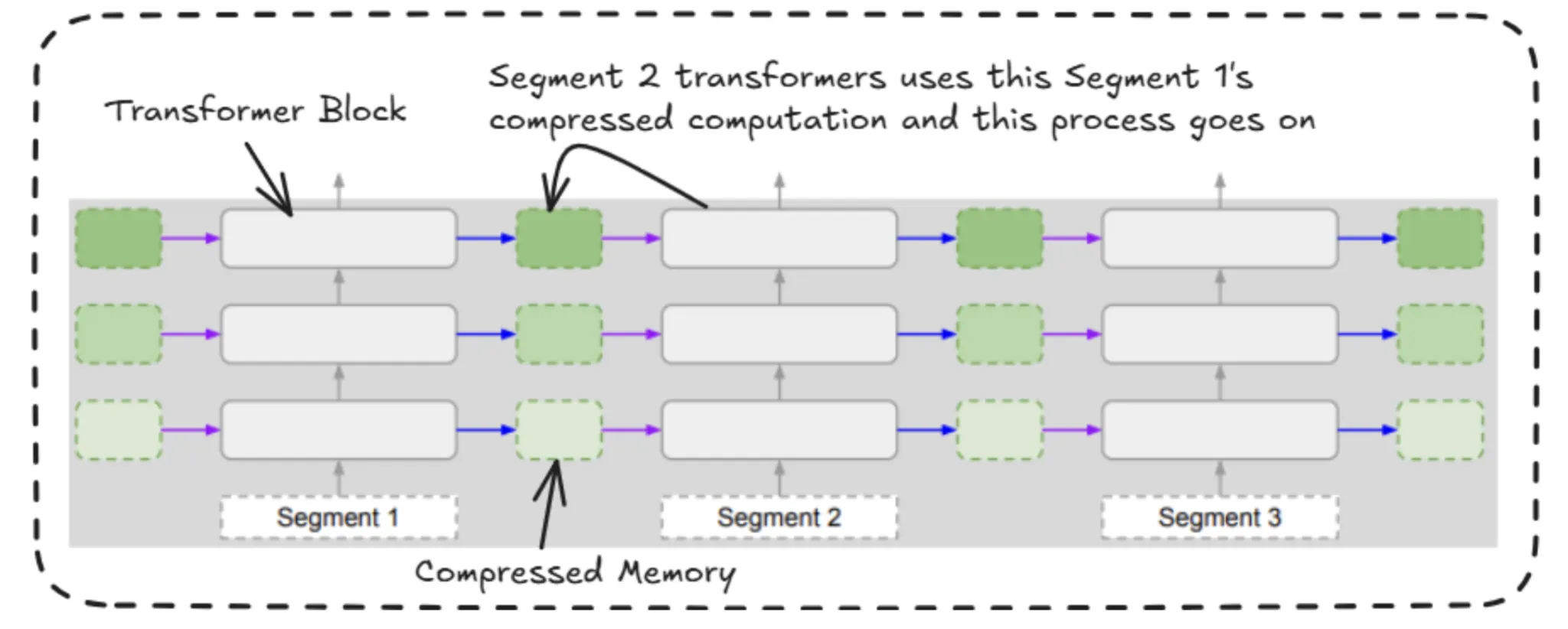
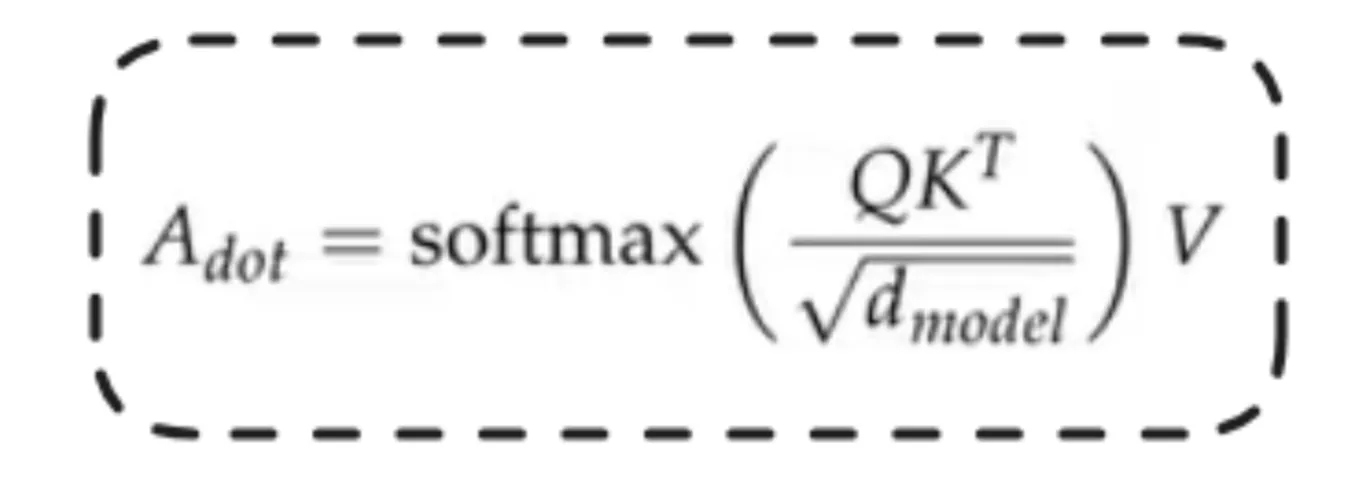
Now, we’ll see how this compressed reminiscence is reused by the upcoming segments’ transformer blocks. So right here we can be utilising the gating mechanism, which appears similar to the logic utilized in LSTM’s gating mechanism.
Gating Mechanism
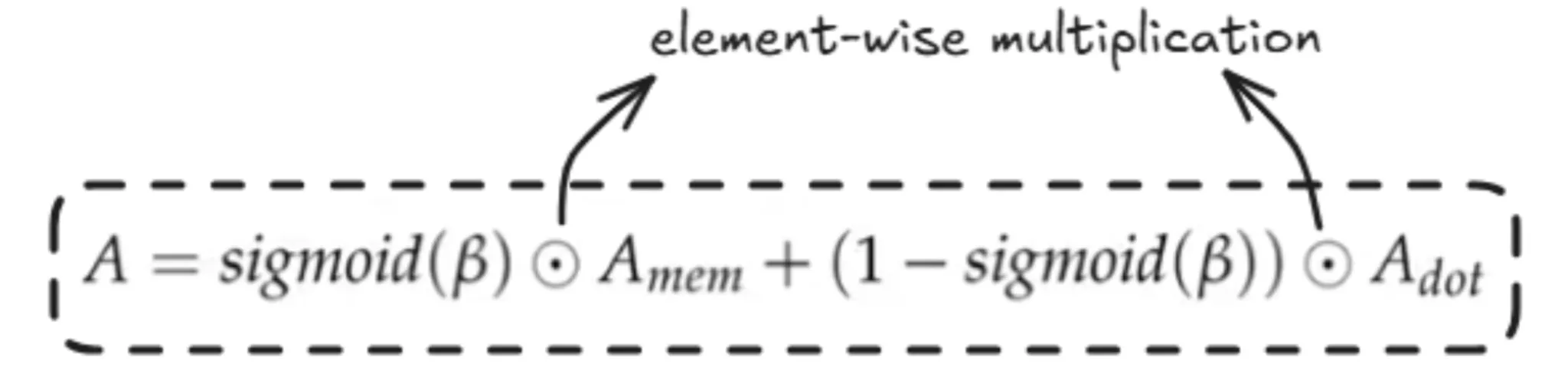
Right here, we simply don’t take the Q, Ok, V for present section and basically add positional embeddings(RoPE) after which compute the self consideration as finished above but additionally make use of knowledge which now we have from earlier segments within the type of compressed reminiscence by retrieving the information through the use of the the present Q (question) used to retrieve the knowledge from the earlier segments and the the present section data is merged to get the general consideration worth.
β right here known as the gating scalar. It helps within the gated merging of the eye from present and former segments. It’s a realized parameter.
Now, we will perceive how this reminiscence is obtained.
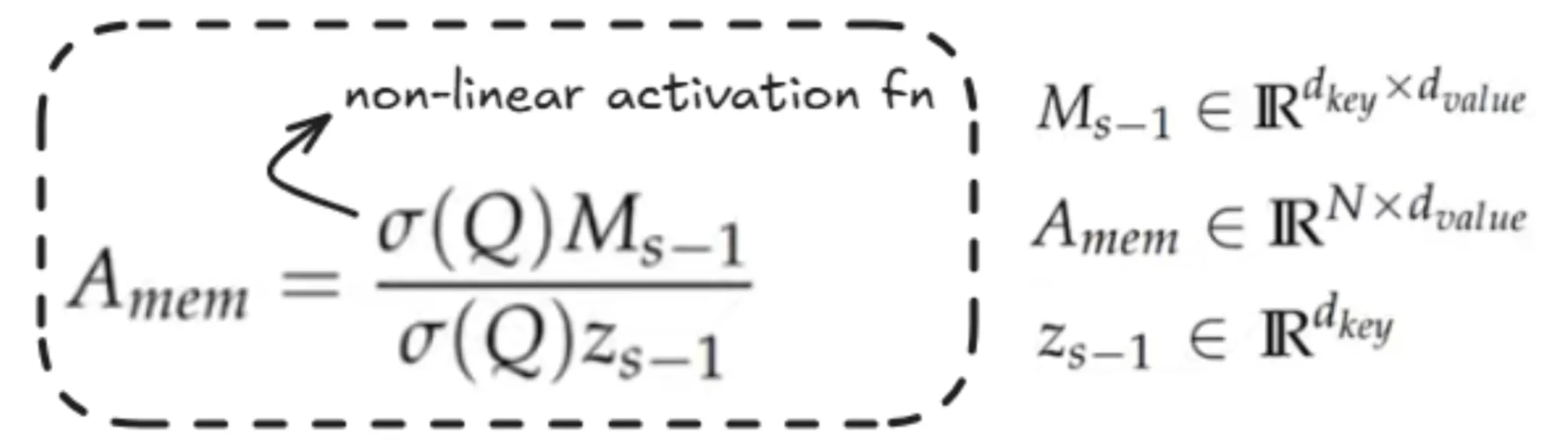
The data now we have computed is saved on this matrix M, the place within the numerator we utilise the Reminiscence matrix of the earlier section. We take the present section and apply an activation operate, which right here makes use of ELU.
Z right here is the sum over all of the keys. It doesn’t matter a lot; it’s principally used on this formulation for normalisation functions.
Now, let’s perceive how reminiscence is up to date to compressed reminiscence
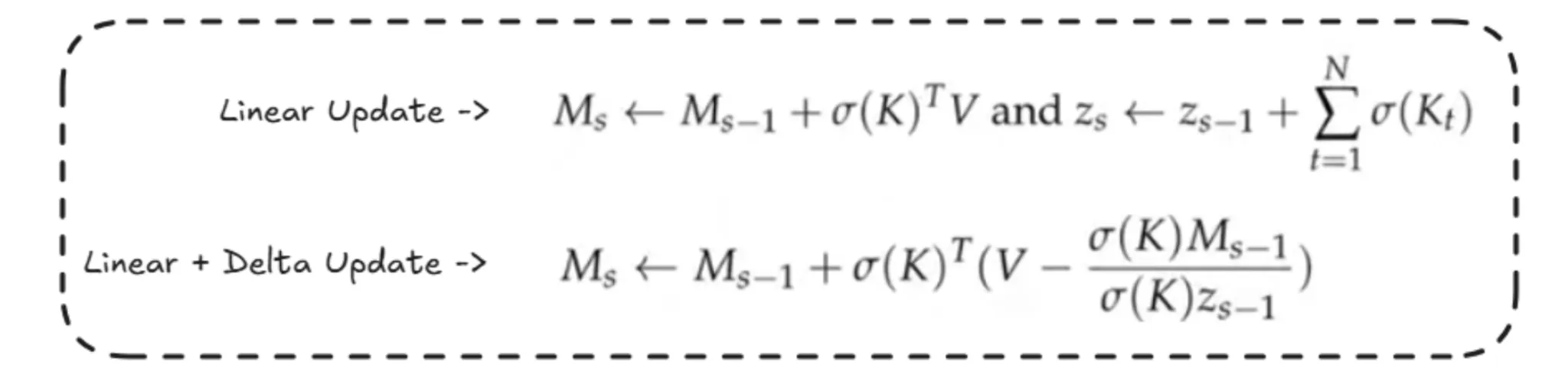
Reminiscence Replace
For the updation of reminiscence, there are 2 strategies:
- Linear Replace is easy, which sums the earlier section reminiscence with the computation of the present section.
- In Linear + Delta updation, the computation of Z is much like that within the above technique, however right here the reminiscence updation is barely completely different. Right here, we subtract the contributions of some a part of the reminiscence. Mainly, some consideration computations have been finished from earlier segments, so we simply replace solely the brand new data, and the earlier data is as it’s. This helps in eradicating the duplicates and makes the reminiscence much less cluttered.
As for the retrieval half, we can be utilizing the present segments Q (question) to retrieve the required reminiscence fragments from the compressed reminiscence and which is handed into the gating mechanism as defined above.
That is how the general circulation of Infini Consideration works internally.
Let’s simply look into some metrics on how efficient Infini Consideration is in comparison with different research like Transformer XL, Reformer-based transformers, and many others…

Right here, the decrease the rating, the higher the efficiency the mannequin exhibits.
One other efficient check was finished in regards to the retrieval job by experimenting with a zero-shot based mostly passkey retrieval job the place a numeric-based passkey is hidden with an enormous context of textual data, and the transformer fashions have been tasked to extract and retrieve these passkeys

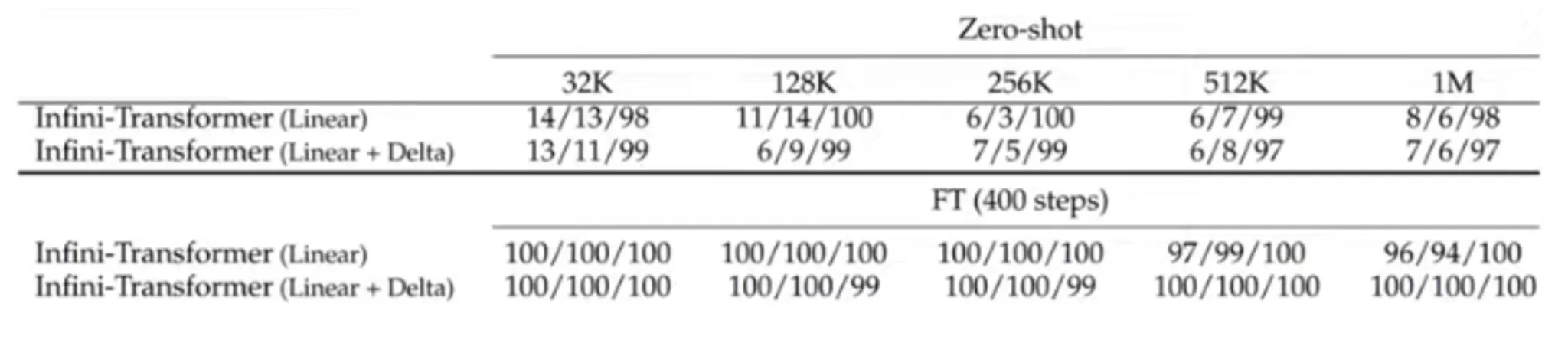
Right here, we will see that Infini Transformer, which is finetuned as much as 400 steps, may be very efficient at such retrieval duties, particularly after we use the Linear + Delta reminiscence updation logic as defined above.
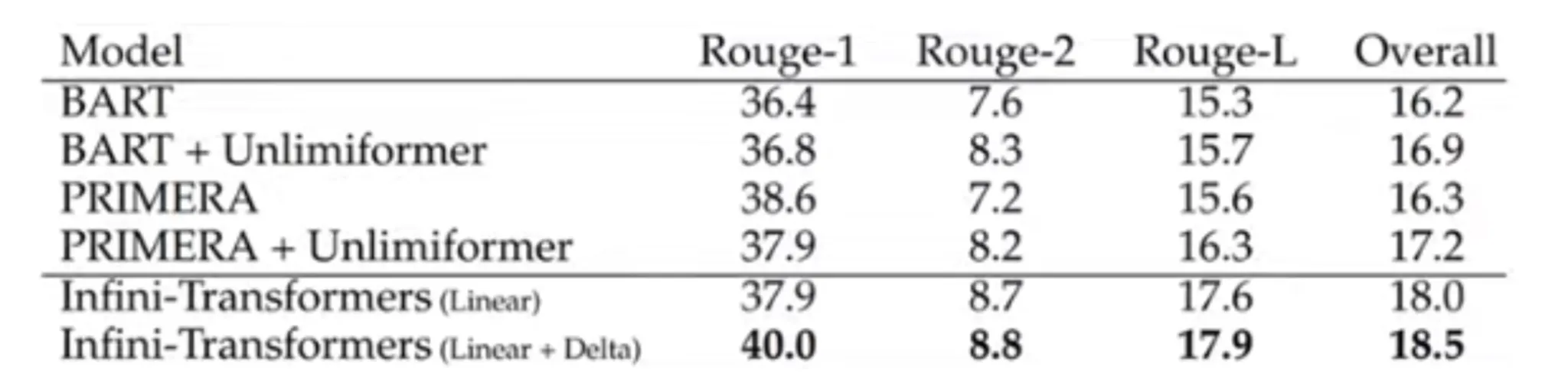
Infini Transformers carry out higher than a number of fashions like BART and PRIMERA in the case of summarisation, as showcased with the supplied ROUGE values within the above desk. This provides us a key perception into the way forward for LLMs.
Conclusion
On this article, we explored three key improvements – Swish activation features, RoPE embeddings, and Infini Consideration which might be actively shaping the following technology of huge language fashions or the way forward for LLMs generally. Every of those developments addresses vital limitations in earlier architectures, whether or not it’s bettering gradient circulation, enhancing positional understanding, or extending context size effectively.
As analysis on this subject continues to speed up, contributions from throughout the globe, fueled by a thriving open-source group, are permitting us to achieve deeper insights into the inner workings of state-of-the-art LLMs, evolving them to new heights sooner or later. These breakthroughs are usually not solely bettering mannequin efficiency but additionally redefining what’s potential in pure language understanding and technology.
The way forward for LLMs is being constructed on such foundational improvements, and staying up to date on them is essential to understanding the place AI is headed subsequent. You possibly can examine how fashionable LLMs perceive visible photographs right here.
GenAI Intern @ Analytics Vidhya | Ultimate 12 months @ VIT Chennai
Obsessed with AI and machine studying, I am wanting to dive into roles as an AI/ML Engineer or Information Scientist the place I could make an actual impression. With a knack for fast studying and a love for teamwork, I am excited to deliver revolutionary options and cutting-edge developments to the desk. My curiosity drives me to discover AI throughout varied fields and take the initiative to delve into information engineering, guaranteeing I keep forward and ship impactful tasks.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}