
AppZen is a number one supplier of AI-driven finance automation options. The corporate’s core providing facilities round an revolutionary AI platform designed for contemporary finance groups, that includes expense administration, fraud detection, and autonomous accounts payable options. AppZen’s know-how stack makes use of pc imaginative and prescient, deep studying, and pure language processing (NLP) to automate monetary processes and guarantee compliance. With this complete resolution method, AppZen has a well-established enterprise buyer base that features one-third of the Fortune 500 corporations.
AppZen hosts all its workloads and utility infrastructure on Amazon Internet Companies (AWS), repeatedly modernizing its know-how stack to successfully operationalize and host its functions. Centralized logging, a essential element of this infrastructure, is important for monitoring and managing operations throughout AppZen’s various workloads. As the corporate skilled fast development, the legacy logging resolution struggled to maintain tempo with increasing wants. Consequently, modernizing this method turned one in all AppZen’s high priorities, prompting a complete overhaul to reinforce operational effectivity and scalability.
On this weblog we present, how AppZen modernizes its central log analytics resolution from Elasticsearch to Amazon OpenSearch Serverless offering an optimized structure to fulfill above talked about necessities.
Challenges with the legacy logging resolution
With a rising variety of enterprise functions and workloads, AppZen had an growing want for complete operational analytics utilizing log knowledge throughout its multi-account group in AWS Organizations. AppZen’s legacy logging resolution created a number of key challenges. It lacked the flexibleness and scalability to effectively index and make the logs accessible for real-time evaluation, which was essential for monitoring anomalies, optimizing workloads, and guaranteeing environment friendly operations.
The legacy logging resolution consisted of a 70-node Elasticsearch cluster (with 30 sizzling nodes and 40 heat nodes), it struggled to maintain up with the rising quantity of log knowledge as AppZen’s buyer base expanded and new mission-critical workloads had been added. This led to efficiency points and elevated operational complexity. Sustaining and managing the self-hosted Elasticsearch cluster required frequent software program updates and infrastructure patching, leading to system downtime, knowledge loss, and added operational overhead for the AppZen CloudOps workforce.
Migrating the information to a patched node cluster took 7 days, far exceeding business normal and AppZen’s operational necessities. This prolonged downtime launched knowledge integrity threat and instantly impacted the operational availability of the centralized logging system essential for groups to troubleshoot throughout essential workloads. The system additionally suffered frequent knowledge loss that impacted real-time metrics monitoring, dashboarding, and alerting as a result of its utility log-collecting agent Fluent Bit lacked important options similar to backoff and retry.
AppZen has an NGINX proxy occasion controlling approved consumer entry to knowledge hosted on Elasticsearch. Upgrades and patching of the occasion launched frequent system downtimes. All consumer requests are routed by way of this proxy layer, the place the consumer’s permission boundary is evaluated. This had an added operations overhead for directors to handle customers and group mapping on the proxy layer.
Resolution overview
AppZen re-platformed its central log analytics resolution with Amazon OpenSearch Serverless and Amazon OpenSearch Ingestion. Amazon OpenSearch Serverless permits you to run OpenSearch within the AWS Cloud, so you possibly can run massive workloads with out configuring, managing, and scaling OpenSearch clusters. You’ll be able to ingest, analyze, and visualize your time-series knowledge with out infrastructure provisioning. OpenSearch Ingestion is a completely managed knowledge collector that simplifies knowledge processing with built-in capabilities to filter, rework, and enrich your logs earlier than evaluation.
This new serverless structure, proven within the following structure diagram, is cost-optimized, safe, high-performing, and designed to scale effectively for future enterprise wants. It serves the next use circumstances:
- Centrally monitor enterprise operations and knowledge evaluation for deep insights
- Utility monitoring and infrastructure troubleshooting
Collectively, OpenSearch Ingestion and OpenSearch Serverless present a serverless infrastructure able to operating massive workloads with out configuring, managing, and scaling the cluster. It offers knowledge resilience with persistent buffers that may assist the present 2 TB per day pipeline knowledge ingestion requirement. IAM Id Heart assist for OpenSearch Serverless helped handle customers and their entry centrally eliminating a necessity for NGINX proxy layer.
The structure diagram additionally exhibits how separate ingestion pipelines had been deployed. This configuration choice improves deployment flexibility primarily based on the workload’s throughput and latency necessities. On this structure, Circulate-1 is a push-based knowledge supply (similar to HTTP and OTel logs) the place the workload’s Fluent Bit DaemonSet is configured to ingest log messages into the OpenSearch Ingestion pipeline. These messages are retained within the pipeline’s persistent buffer to supply knowledge sturdiness. After processing the message, it’s inserted into OpenSearch Serverless.
And Circulate-2 is a pull-based knowledge supply similar to Amazon Easy Storage Service (Amazon S3) for OpenSearch Ingestion the place the workload’s Fluent Bit DaemonSets are configured to sync knowledge to an S3 bucket. Utilizing S3 Occasion Notifications, the brand new log data creation notifications are despatched to Amazon Easy Queue Service (Amazon SQS). OpenSearch Ingestion consumes this notification and processes the document to insert into OpenSearch Serverless, delegating the information sturdiness to the information supply. For each Circulate-1 and Circulate-2, the OpenSearch Ingestion pipelines are configured with a dead-letter queue to document failed ingestion messages to the S3 supply, making them accessible for additional evaluation.
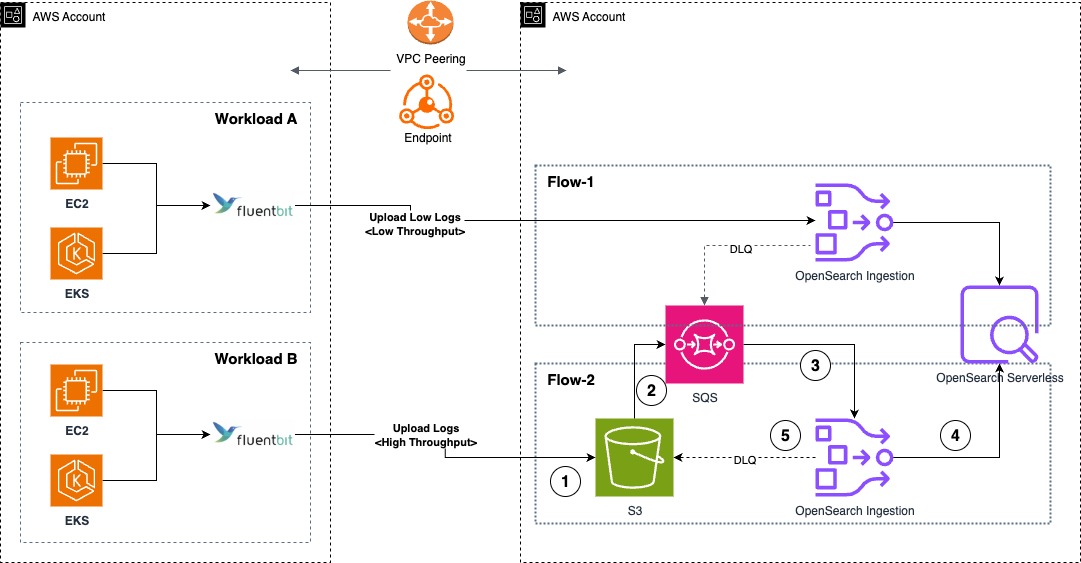
For service log analytics, AppZen adopted a pull-based method as proven within the following determine, the place all service logs revealed to Amazon CloudWatch are migrated an S3 bucket for additional processing. An AWS Lambda processor is triggered when each new message is ingested to the S3 bucket, and the processed message is then uploaded to the S3 bucket for OpenSearch ingestion. The next diagram exhibits the OpenSearch Serverless structure for the service log analytics pipeline.

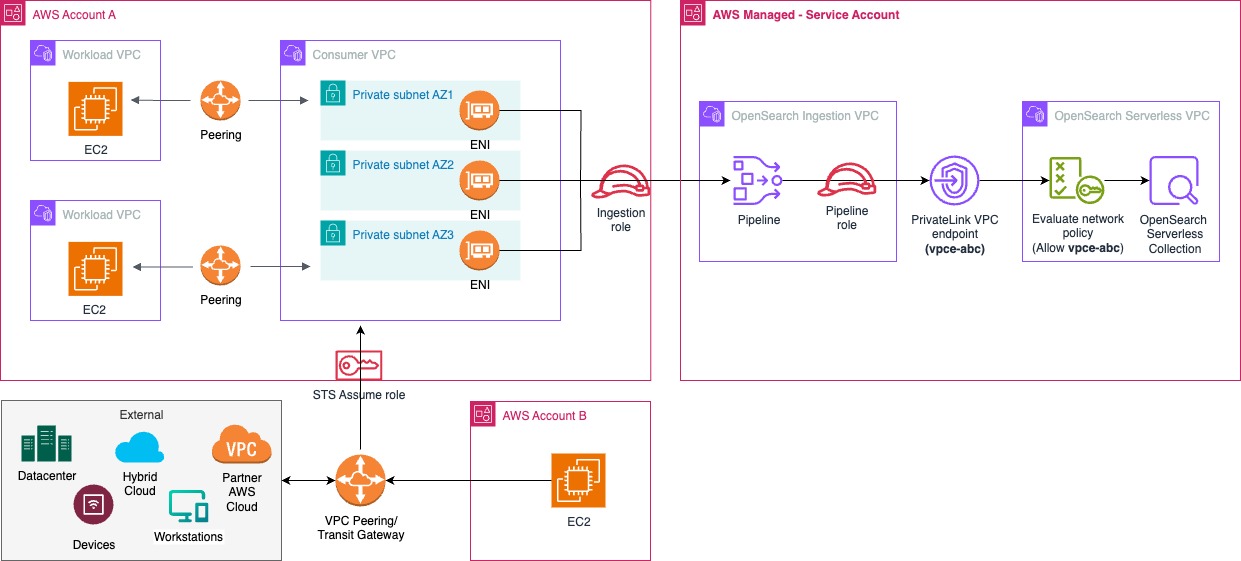
Workloads and infrastructure unfold throughout a number of AWS accounts can securely ship logs to the central log analytics platform over a personal community utilizing digital personal cloud (VPC) peering and AWS PrivateLink endpoints, as proven within the following determine. Each OpenSearch Ingestion and OpenSearch Serverless are provisioned in the identical account and Area, with cross-account ingestion enabled for workloads in different member accounts of the AWS Organizations account.
Migration method
The migration to OpenSearch Serverless and OpenSearch Ingestion concerned efficiency analysis and fine-tuning the configuration of the logging stack, adopted by migration of manufacturing site visitors to new platform. Step one was to configure and benchmark the infrastructure for cost-optimized efficiency.
Parallel ingestion to benchmark OCU capability necessities
OpenSearch Ingestion scales elastically to fulfill throughput necessities throughout workload spikes. Enabling persistent buffering on ingestion pipelines with push-based knowledge sources offered knowledge sturdiness and reliability. Knowledge ingestion pipelines are ingesting at a price of two TB per day. Resulting from AppZen’s 90-day knowledge retention requirement round its ingested knowledge, at any time, there’s roughly 200 TB of listed historic knowledge saved within the OpenSearch Serverless cluster. To guage efficiency and prices earlier than deploying to manufacturing, knowledge sources had been configured to ingest knowledge in parallel into the brand new OpenSearch Serverless surroundings together with an current setup already operating in manufacturing with Elasticsearch.
To realize parallel ingestion, AppZen put in one other Fluent Bit DaemonSet configured to ingest into the brand new pipeline. This was for 2 causes: 1) To keep away from interruption attributable to adjustments to current ingestion stream and a couple of) New workflows are rather more easy when the information preprocessing step is offloaded to OpenSearch Ingestion, eliminating the necessity for customized lua script use in Fluent Bit.
Pipeline configuration
The manufacturing pipeline configuration was applied with totally different methods primarily based on knowledge supply varieties. Push-based knowledge sources had been configured with persistent buffer enabled for knowledge sturdiness and a minimal of three OpenSearch Compute Models (OCUs) to supply excessive availability throughout three Availability Zones. In distinction, pull-based knowledge sources, which used Amazon S3 as their supply, didn’t require persistent buffering as a result of inherent sturdiness options of Amazon S3. Each pipeline varieties had been initially configured with a minimal of three OCUs and a most of fifty OCUs to determine baseline efficiency metrics. This setup meant the workforce may monitor and analyze precise workload patterns, and due to this fact fine-tune employee configurations for optimum OCU utilization. By way of steady monitoring and adjustment, the pipeline configurations had been modified and optimized to effectively deal with each each day common hundreds and peak site visitors intervals, offering cost-effective and dependable knowledge processing operations.
For AppZen’s throughput requirement, within the pull-based method, they recognized six Amazon S3 staff within the OpenSearch Ingestion pipelines optimally processing 1 OCU at 80% effectivity. Following the greatest practices suggestion, at this system.cpu.utilization.worth metrics threshold, the pipeline was configured to auto scale. With every employee able to processing 10 messages, AppZen recognized cost-optimized configuration of fifty OCUs as most OCU configuration for its pipelines that’s able to processing as much as 3,000 messages in parallel. This pipeline configuration proven under helps its peak throughput necessities
Indexing technique
When working with search engine, understanding index and shard administration is essential. Indexes and their corresponding shards eat reminiscence and CPU assets to keep up metadata. A key problem emerges when having quite a few small shards in a system as a result of it results in increased useful resource consumption and operational overhead. Within the conventional method, you usually create indices on the microservice stage for every surroundings (prod, qa, and dev). For instance, indices could be named like prod-k1-service or prod-k2-service, the place k1 and k2 symbolize totally different microservices. With lots of of providers and each day index rotation, this method ends in hundreds of indices, making administration advanced and useful resource intensive. When implementing OpenSearch Serverless, you must undertake a consolidated indexing technique that strikes away from microservice-level index creation. Moderately than creating particular person indices like prod-k1-service and prod-k2-service for every microservice and surroundings, you must consolidate the information into broader environment-based indices similar to prod-service, which incorporates all service knowledge for the manufacturing surroundings. This consolidation is important as a result of OpenSearch Serverless scales primarily based on assets and has particular limitations on the variety of shards per OCU. Which means having a better variety of small shards will result in increased OCU consumption.
Nonetheless, though this consolidated method can considerably cut back operational prices and simplify administration by way of built-in knowledge lifecycle insurance policies, it presents a notable problem for multi-tenant eventualities. Organizations with strict safety necessities, the place totally different groups want entry to particular indices solely, would possibly discover this consolidated method difficult to implement. For such circumstances, a extra granular indices method could be mandatory to keep up correct entry management, though it can lead to increased useful resource consumption.
By rigorously evaluating your safety necessities and entry management wants, you possibly can select between a consolidated method for optimized useful resource utilization or a extra granular method that higher helps fine-grained entry management. Each approaches are supported in OpenSearch Serverless, so you possibly can stability useful resource optimization with safety necessities primarily based in your particular use case.
Price optimization
OpenSearch Ingestion allocates some OCUs from configured pipeline capability for persistent buffering, which offers knowledge sturdiness. Whereas monitoring, AppZen noticed increased OCU utilization for this persistent buffer when processing high-throughput workloads. To optimize this capability configuration, AppZen determined to categorise its workloads into push-based and pull-based classes relying on their throughput and latency necessities. Attaining this created new parallel pipelines to function these flows in parallel, as proven within the structure diagram earlier within the put up. Fluent Bit agent collector configurations had been accordingly modified primarily based on the workload classification.
Relying on the associated fee and efficiency necessities for the workload, AppZen adopted the suitable ingestion stream. For low latency and low-throughput workload necessities, AppZen selected the push-based method. For top-throughput workload necessities, AppZen adopted the pull-based method, which helped decrease the persistent buffer OCU utilization by counting on sturdiness to the information supply. Within the pull-based method, AppZen additional optimized on the storage value by configuring the pipeline to robotically delete the processed knowledge from the S3 bucket after profitable ingestion
Monitoring and dashboard
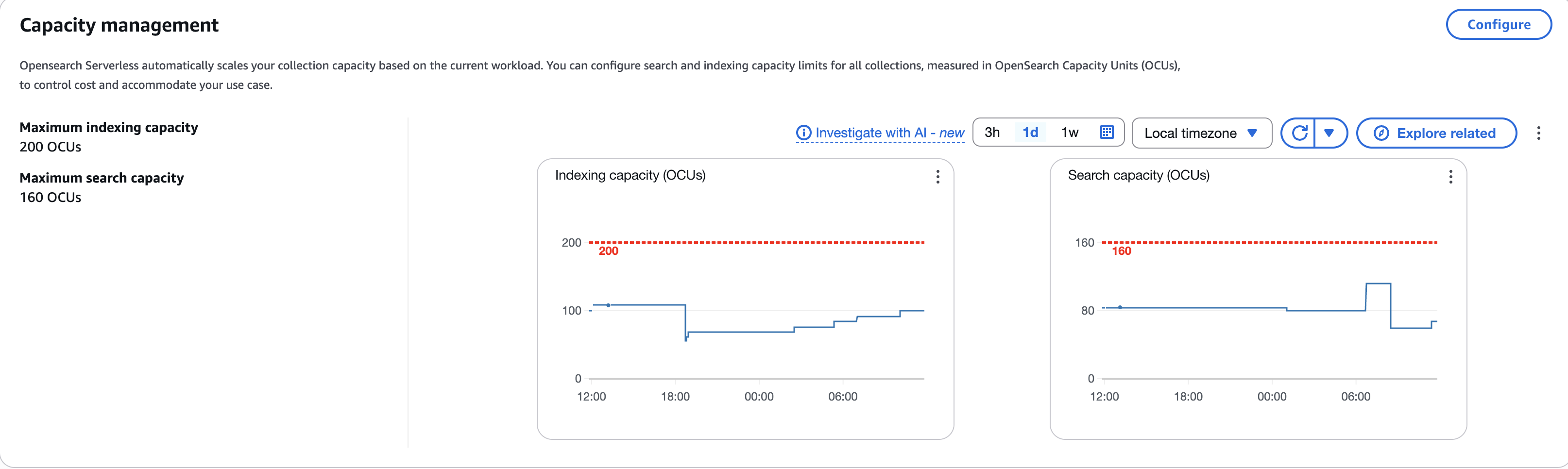
One of many key design ideas for operational excellence within the cloud is to implement observability for actionable insights. This helps achieve a complete understanding of the workloads to assist enhance efficiency, reliability, and the associated fee concerned. Each OpenSearch Serverless and OpenSearch Ingestion publish all metrics and logs knowledge to Amazon CloudWatch. After figuring out key operational OpenSearch Serverless metrics and OpenSearch Service pipeline metrics, AppZen arrange CloudWatch alarms to ship a notification when sure outlined thresholds are met. The next screenshot exhibits the variety of OCUs used to index and search assortment knowledge.
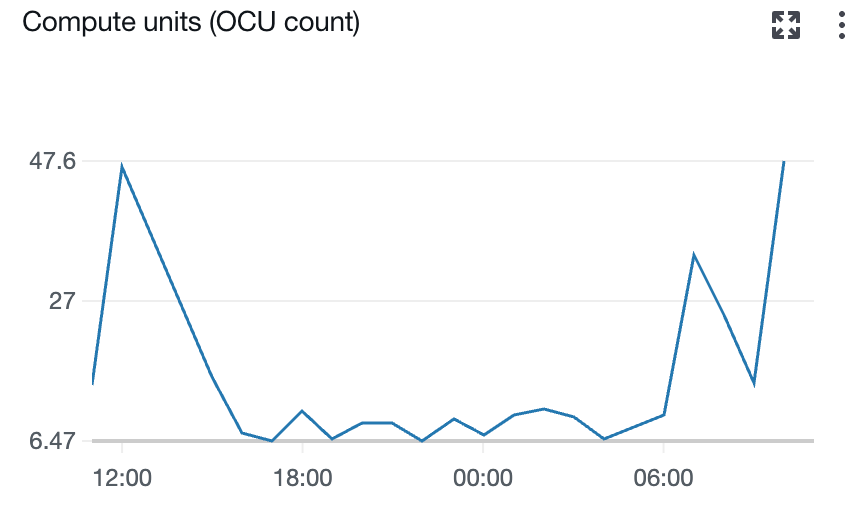
The next screenshot exhibits the variety of Ingestion OCUs in use by the pipeline.
The next screenshot exhibits the proportion of obtainable CPU utilization for OCU.
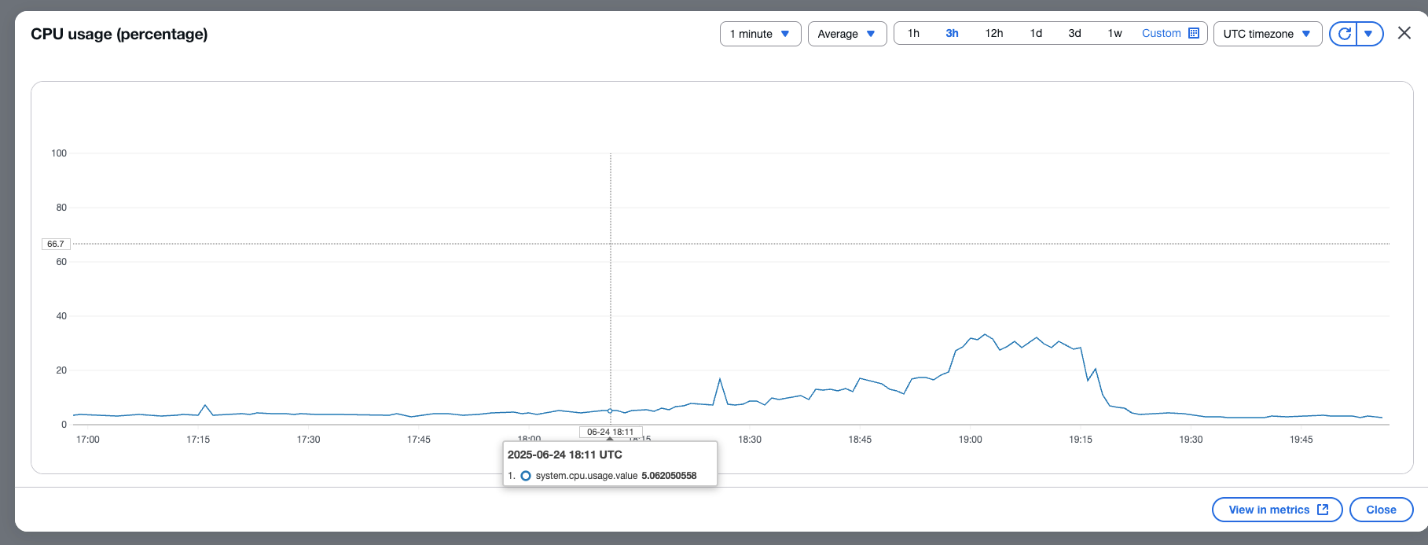
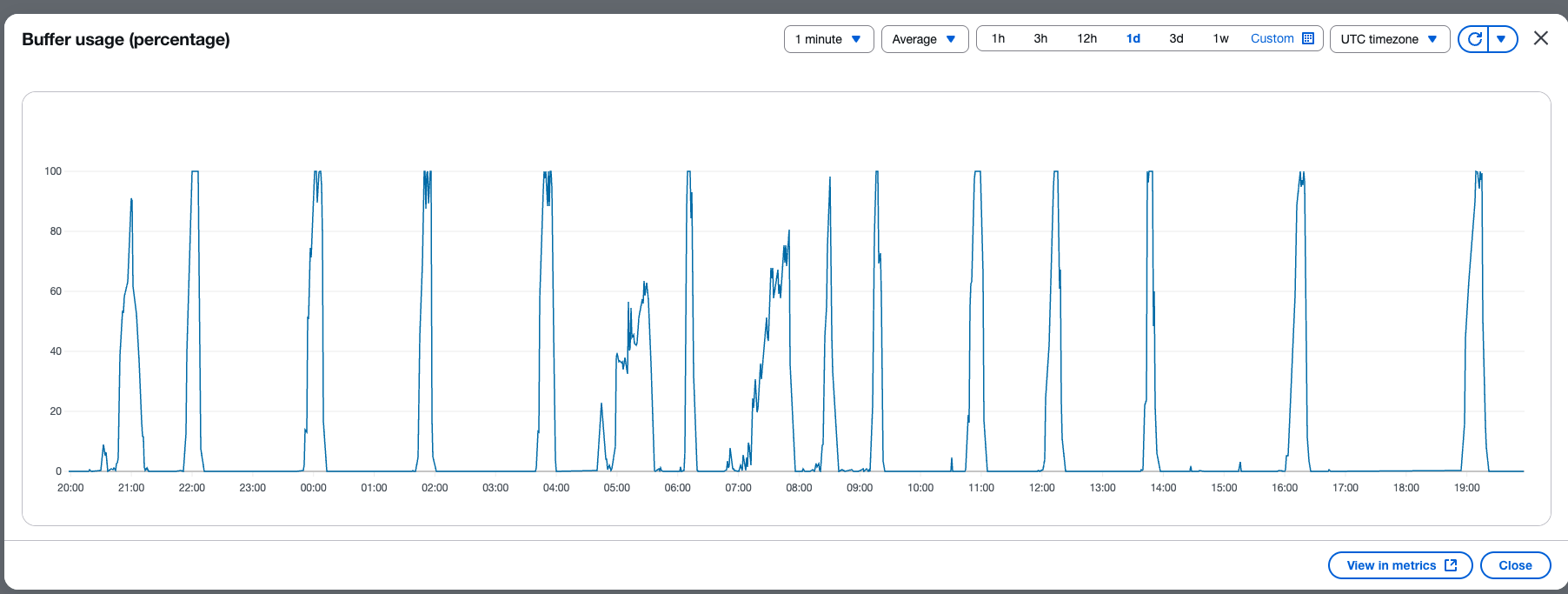
The next screenshot exhibits the p.c utilization of buffer primarily based on the variety of data within the buffer.
Conclusion
AppZen efficiently modernized their logging infrastructure by migrating to a serverless structure utilizing Amazon OpenSearch Serverless and OpenSearch Ingestion. By adopting this new serverless resolution, AppZen eradicated an operations overhead that concerned 7 days of information migration effort throughout every quarterly improve and patching cycle of Kubernetes cluster internet hosting Elasticsearch nodes. Additionally, with the serverless method, AppZen was in a position to keep away from index mapping conflicts through the use of index templates and a brand new indexing technique. This helped the workforce save a mean 5.2 hours per week of operational effort and as an alternative use the time to give attention to different precedence enterprise challenges. AppZen achieved a greater safety posture by way of centralized entry controls with OpenSearch Serverless, eliminating the overhead of managing a reproduction set of consumer permissions on the proxy layer. The brand new resolution helped AppZen deal with rising knowledge quantity and construct real-time operational analytics whereas optimizing value, bettering scalability and resiliency. AppZen optimized prices and efficiency by classifying workloads into push-based and pull-based flows, so they might select the suitable ingestion method primarily based on latency and throughput necessities.
With this modernized logging resolution, AppZen is properly positioned to effectively monitor their enterprise operations, carry out in-depth knowledge evaluation, and successfully monitor and troubleshooting the applying as they proceed to develop. Wanting forward, AppZen plans to make use of OpenSearch Serverless as a vector database, incorporating Amazon S3 Vectors, generative AI, and basis fashions (FMs) to reinforce operational duties utilizing pure language processing.
To implement an identical logging resolution to your group, start by exploring AWS documentation on migrating to Amazon OpenSearch Serverless and organising OpenSearch Serverless. For steerage on creating ingestion pipelines, seek advice from the AWS information on OpenSearch Ingestion to start modernizing your logging infrastructure.
Concerning the authors
 Prashanth Dudipala is a DevOps Architect at AppZen, the place he helps construct scalable, safe, and automatic cloud platforms on AWS. He’s obsessed with simplifying advanced programs, enabling groups to maneuver quicker, and sharing sensible insights with the cloud group.
Prashanth Dudipala is a DevOps Architect at AppZen, the place he helps construct scalable, safe, and automatic cloud platforms on AWS. He’s obsessed with simplifying advanced programs, enabling groups to maneuver quicker, and sharing sensible insights with the cloud group.
 Madhuri Andhale is a DevOps Engineer at AppZen, targeted on constructing and optimizing cloud-native infrastructure. She is obsessed with managing environment friendly CI/CD pipelines, streamlining infrastructure and deployments, modernizing programs, and enabling growth groups to ship quicker and extra reliably. Exterior of labor, Madhuri enjoys exploring rising applied sciences, touring to new locations, experimenting with new recipes, and discovering artistic methods to resolve on a regular basis challenges.
Madhuri Andhale is a DevOps Engineer at AppZen, targeted on constructing and optimizing cloud-native infrastructure. She is obsessed with managing environment friendly CI/CD pipelines, streamlining infrastructure and deployments, modernizing programs, and enabling growth groups to ship quicker and extra reliably. Exterior of labor, Madhuri enjoys exploring rising applied sciences, touring to new locations, experimenting with new recipes, and discovering artistic methods to resolve on a regular basis challenges.
 Manoj Gupta is a Senior Options Architect at AWS, primarily based in San Francisco. With over 4 years of expertise at AWS, he works carefully with prospects like AppZen to construct optimized cloud architectures. His main focus areas are Knowledge, AI/ML, and Safety, serving to organizations modernize their know-how stacks. Exterior of labor, he enjoys outside actions and touring with household.
Manoj Gupta is a Senior Options Architect at AWS, primarily based in San Francisco. With over 4 years of expertise at AWS, he works carefully with prospects like AppZen to construct optimized cloud architectures. His main focus areas are Knowledge, AI/ML, and Safety, serving to organizations modernize their know-how stacks. Exterior of labor, he enjoys outside actions and touring with household.
 Prashant Agrawal is a Sr. Search Specialist Options Architect with Amazon OpenSearch Service. He works carefully with prospects to assist them migrate their workloads to the cloud and helps current prospects fine-tune their clusters to attain higher efficiency and save on value. Earlier than becoming a member of AWS, he helped numerous prospects use OpenSearch and Elasticsearch for his or her search and log analytics use circumstances. When not working, you’ll find him touring and exploring new locations. Briefly, he likes doing Eat → Journey → Repeat.
Prashant Agrawal is a Sr. Search Specialist Options Architect with Amazon OpenSearch Service. He works carefully with prospects to assist them migrate their workloads to the cloud and helps current prospects fine-tune their clusters to attain higher efficiency and save on value. Earlier than becoming a member of AWS, he helped numerous prospects use OpenSearch and Elasticsearch for his or her search and log analytics use circumstances. When not working, you’ll find him touring and exploring new locations. Briefly, he likes doing Eat → Journey → Repeat.

{kind=link}