
Differential privateness (DP) stands because the gold normal for safeguarding consumer info in large-scale machine studying and information analytics. A crucial job inside DP is partition choice—the method of safely extracting the biggest potential set of distinctive objects from huge user-contributed datasets (equivalent to queries or doc tokens), whereas sustaining strict privateness ensures. A staff of researchers from MIT and Google AI Analysis current novel algorithms for differentially personal partition choice, which is an method to maximise the variety of distinctive objects chosen from a union of units of knowledge, whereas strictly preserving user-level differential privateness
The Partition Choice Drawback in Differential Privateness
At its core, partition choice asks: How can we reveal as many distinct objects as potential from a dataset, with out risking any particular person’s privateness? Objects solely identified to a single consumer should stay secret; solely these with enough “crowdsourced” assist might be safely disclosed. This downside underpins crucial functions equivalent to:
- Non-public vocabulary and n-gram extraction for NLP duties.
- Categorical information evaluation and histogram computation.
- Privateness-preserving studying of embeddings over user-provided objects.
- Anonymizing statistical queries (e.g., to engines like google or databases).
Customary Approaches and Limits
Historically, the go-to resolution (deployed in libraries like PyDP and Google’s differential privateness toolkit) entails three steps:
- Weighting: Every merchandise receives a “rating”, often its frequency throughout customers, with each consumer’s contribution strictly capped.
- Noise Addition: To cover exact consumer exercise, random noise (often Gaussian) is added to every merchandise’s weight.
- Thresholding: Solely objects whose noisy rating passes a set threshold—calculated from privateness parameters (ε, δ)—are launched.
This technique is easy and extremely parallelizable, permitting it to scale to gigantic datasets utilizing techniques like MapReduce, Hadoop, or Spark. Nonetheless, it suffers from elementary inefficiency: common objects accumulate extra weight that doesn’t additional help privateness, whereas less-common however probably helpful objects usually miss out as a result of the surplus weight isn’t redirected to assist them cross the brink.
Adaptive Weighting and the MaxAdaptiveDegree (MAD) Algorithm
Google’s analysis introduces the primary adaptive, parallelizable partition choice algorithm—MaxAdaptiveDegree (MAD)—and a multi-round extension MAD2R, designed for really huge datasets (a whole lot of billions of entries).
Key Technical Contributions
- Adaptive Reweighting: MAD identifies objects with weight far above the privateness threshold, reroutes the surplus weight to spice up lesser-represented objects. This “adaptive weighting” will increase the likelihood that rare-but-shareable objects are revealed, thus maximizing output utility.
- Strict Privateness Ensures: The rerouting mechanism maintains the very same sensitivity and noise necessities as basic uniform weighting, making certain user-level (ε, δ)-differential privateness underneath the central DP mannequin.
- Scalability: MAD and MAD2R require solely linear work in dataset dimension and a relentless variety of parallel rounds, making them appropriate with huge distributed information processing techniques. They needn’t match all information in-memory and assist environment friendly multi-machine execution.
- Multi-Spherical Enchancment (MAD2R): By splitting privateness finances between rounds and utilizing noisy weights from the primary spherical to bias the second, MAD2R additional boosts efficiency, permitting much more distinctive objects to be safely extracted—particularly in long-tailed distributions typical of real-world information.
How MAD Works—Algorithmic Particulars
- Preliminary Uniform Weighting: Every consumer shares their objects with a uniform preliminary rating, making certain sensitivity bounds.
- Extra Weight Truncation and Rerouting: Objects above an “adaptive threshold” have their extra weight trimmed and rerouted proportionally again to contributing customers, who then redistribute this to their different objects.
- Remaining Weight Adjustment: Further uniform weight is added to make up for small preliminary allocation errors.
- Noise Addition and Output: Gaussian noise is added; objects above the noisy threshold are output.
In MAD2R, the first-round outputs and noisy weights are used to refine which objects must be targeted on within the second spherical, with weight biases making certain no privateness loss and additional maximizing output utility.
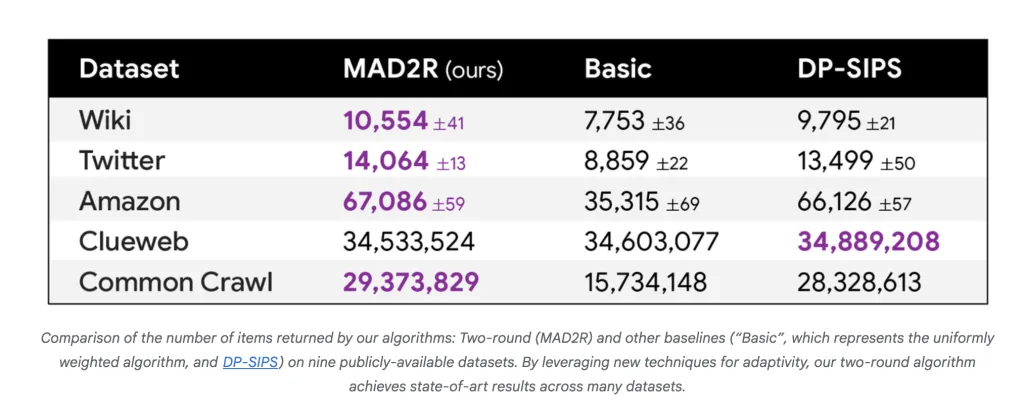
Experimental Outcomes: State-of-the-Artwork Efficiency
In depth experiments throughout 9 datasets (from Reddit, IMDb, Wikipedia, Twitter, Amazon, all the best way to Widespread Crawl with almost a trillion entries) present:
- MAD2R outperforms all parallel baselines (Primary, DP-SIPS) on seven out of 9 datasets when it comes to variety of objects output at fastened privateness parameters.
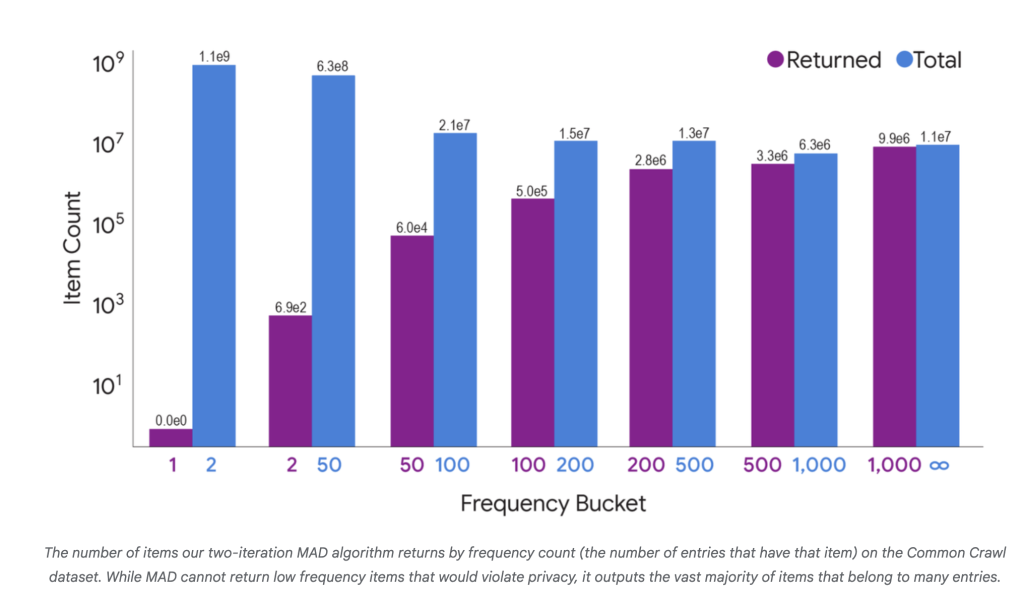
- On the Widespread Crawl dataset, MAD2R extracted 16.6 million out of 1.8 billion distinctive objects (0.9%), however lined 99.9% of customers and 97% of all user-item pairs within the information—demonstrating exceptional sensible utility whereas holding the road on privateness.
- For smaller datasets, MAD approaches the efficiency of sequential, non-scalable algorithms, and for large datasets, it clearly wins in each pace and utility.
Concrete Instance: Utility Hole
Contemplate a situation with a “heavy” merchandise (very generally shared) and lots of “mild” objects (shared by few customers). Primary DP choice overweights the heavy merchandise with out lifting the sunshine objects sufficient to move the brink. MAD strategically reallocates, growing the output likelihood of the sunshine objects and leading to as much as 10% extra distinctive objects found in comparison with the usual method.
Abstract
With adaptive weighting and parallel design, the analysis staff brings DP partition choice to new heights in scalability and utility. These advances guarantee researchers and engineers could make fuller use of personal information, extracting extra sign with out compromising particular person consumer privateness.
Try the Weblog and Technical paper right here. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

{kind=link}