
In enterprise intelligence and analytics, the preliminary supply of knowledge isn’t ultimate for decision-making. The supervisor or analyst receives an extended listing of transactions that may simply confuse anybody and be cumbersome to interpret. The ultimate output of an extended listing of transactions, usually, is summarized to convey traits/ patterns/ efficiency indicators. That is the place pivot tables are important, made potential by SQL PIVOT Operator or conditional aggregation with CASE expressions. Right here, we will discover each
With a pivot operation, we’re turning rows into columns (the efficiency indicators), whereas concurrently aggregating the knowledge. In easy phrases, as an alternative of hundreds of data of gross sales over time, the pivot desk can present complete gross sales per geography for every of the merchandise. It thus makes the information simpler to interpret. The SQL Server PIVOT operator was first launched in SQL Server 2005 and permits for pivoting of rows to columns simply.
Previous to the existence of the PIVOT operator, developer reliance on grouping of columns and aggregation of a number of CASE statements in a SELECT clause to simply remodel rows to columns was widespread. The older strategies have been practical, however they have been very wordy, and don’t are typically legacy-friendly as they’re much tougher to interpret and preserve. The PIVOT operator offers a clear syntax to summarize information into efficiency indicators and retain significant names for the efficiency indicators. It lets you do the summarization immediately in SQL slightly than exporting it and performing calculations and transformations in Excel or different enterprise intelligence options.
Additionally learn: Create Pivot Desk Utilizing Pandas in Python
SQL PIVOT Operator: What it Does
The PIVOT operator takes the distinctive values from a supply column and turns them into a number of new columns as headers within the question output, whereas making use of an mixture operate to the values from one other column, grouping by a number of non-pivoted columns.
PIVOT makes it simpler to vary the construction of datasets as a way to use them for evaluation. Somewhat than writing a fancy logic to get the information reformatted, the PIVOT operator permits SQL Server to handle the pivoting internally. What’s extra, it principally achieves higher efficiency than a consumer software.
The PIVOT operator shines most after we need to design cross-tabulation experiences shortly. PIVOT helps analysts visualize and see their aggregated element values by classes, reminiscent of month-to-month complete, product gross sales, or efficiency metrics associated to a division, very concisely, and in a extra readable format.
SQL PIVOT Operator: Syntax and Construction
The PIVOT operator is specified within the FROM clause of a question, normally as a subquery. The subquery known as the supply question and should return three issues: a non-pivoted column (or columns), a pivot column, and a price column.
Right here’s the final syntax for a PIVOT question:
SELECT , [pivoted_column_1], [pivoted_column_2], ...
FROM (
SELECT , ,
FROM
) AS SourceQuery
PIVOT (
()
FOR IN ([pivoted_column_1], [pivoted_column_2], ...)
) AS PivotTableAlias; Now, let’s perceive what these key phrases imply:
- The non-pivoted columns are the information that can stay as rows within the outcome. These are the grouping keys to the pivot operation. For instance, inside a gross sales dataset, this might be a Area column.
- The pivot column is the column whose distinctive values will now turn into the brand new columns in your outcome set. For instance, in case you are pivoting by product sort, the product names every turn into a column in your output.
- The worth column comprises the numeric or measurable information you need to mixture. You’ll specify any mixture operate on this column as you usually would (i.e. SUM, AVG, COUNT, MIN, or MAX).
- The combination operate is used to mix the column values at each intersection of a non-pivoted and a pivoted column. For instance, SUM(SalesAmount) represents complete gross sales for every pivoted column for every grouping key column.
- The IN listing within the PIVOT clause specifies precisely which of the pivot column values ought to turn into columns within the output. These values are hard-coded; in case your information adjustments and has new product sorts that aren’t referenced right here, you’ll need to vary your question.
- Lastly, each the supply subquery and the ultimate outcomes of the PIVOT require aliases. Within the absence of aliases, SQL Server will throw a syntax error.
SQL PIVOT Operator: Step-by-Step Instance
Allow us to work by means of an instance utilizing a easy dataset.
Supply Information
Allow us to think about the next ProductSales desk:
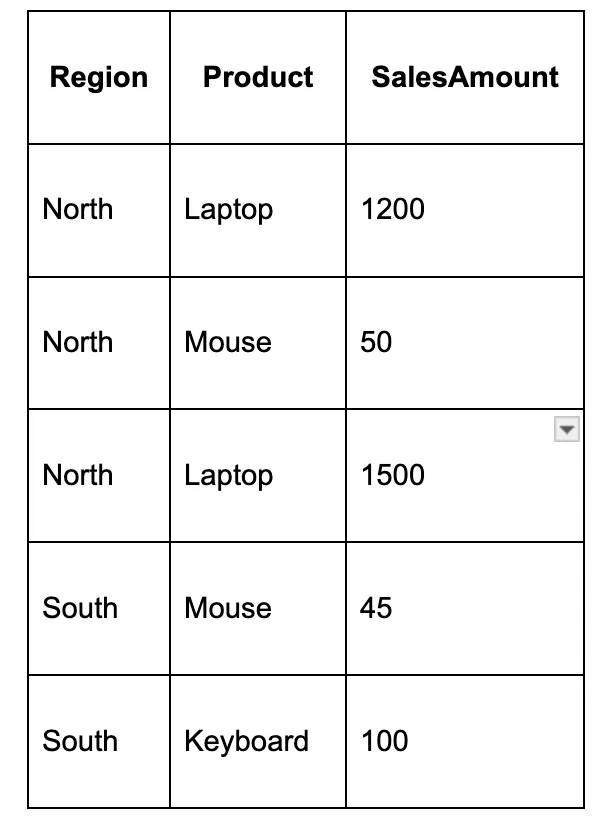
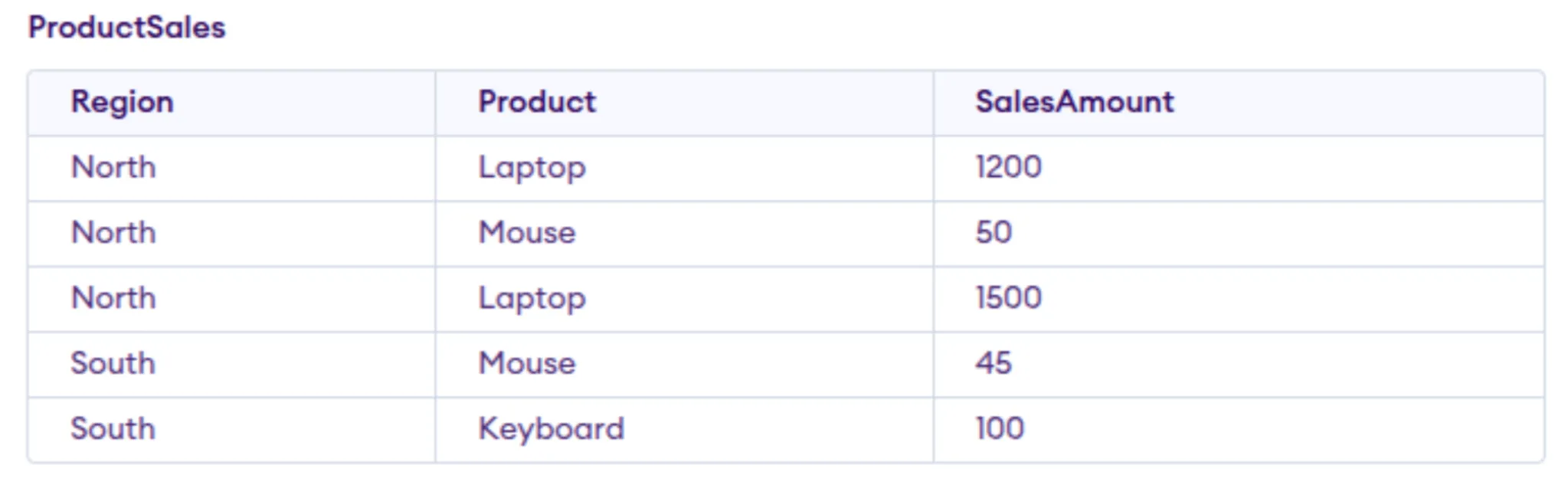
We need to produce a report that exhibits complete gross sales per area, with every product being its personal column.
Step 1: Arrange the Subquery
The subquery should return the non-pivoted, pivot, and worth columns:
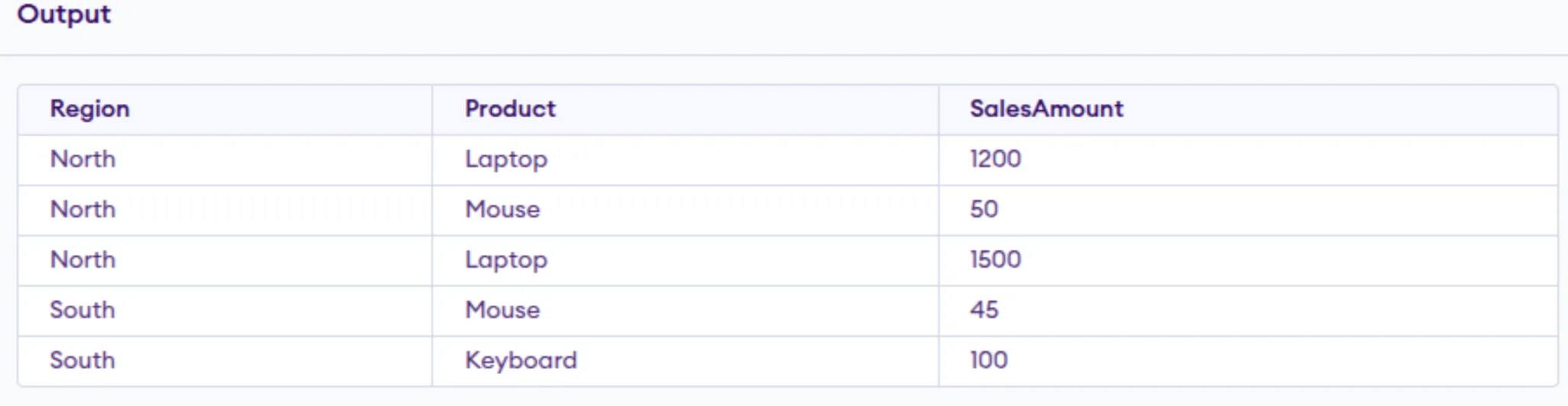
SELECT Area, Product, SalesAmount
FROM ProductSales;In our case, Area is the non-pivoted column, Product is the pivot column, and SalesAmount is the worth column.
Output:
Step 2: Use PIVOT
We’ll pivot on Product and mixture the gross sales by summing them:
SELECT Area, [Laptop], [Mouse], [Keyboard]
FROM (
SELECT Area, Product, SalesAmount
FROM ProductSales
) AS SourceData
PIVOT (
SUM(SalesAmount)
FOR Product IN ([Laptop], [Mouse], [Keyboard])
) AS PivotTable;Step 3: Look at the Outcomes
The result of the question is:

The North complete for Laptop computer is 2700 as a result of it calculates the sum of 1200 plus 1500. NULL values symbolize that there isn’t a matching information.
Step 4: Changing NULLs
To show NULL to 0, use ISNULL or COALESCE:
SELECT Area,
ISNULL([Laptop], 0) AS Laptop computer,
ISNULL([Mouse], 0) AS Mouse,
ISNULL([Keyboard], 0) AS Keyboard
FROM (
SELECT Area, Product, SalesAmount
FROM ProductSales
) AS SourceData
PIVOT (
SUM(SalesAmount)
FOR Product IN ([Laptop], [Mouse], [Keyboard])
) AS PivotTable;
SQL PIVOT Operator: Efficiency Issues
The efficiency of the PIVOT question has loads to do with the bottom supply subquery efficiency. Filtering within the subquery will restrict the quantity of knowledge it’s a must to pivot, and can make it simpler on the database. Indexes on included pivot and non-pivot columns can enhance efficiency on bigger datasets.
A wider pivoted output means the pivot column has essentially the most totally different values. It results in extra reminiscence getting used and decrease efficiency. So, take into consideration the dimensions of your pivoted output and think about additional summarizing it if needed.
SQL PIVOT Operator: Limitations
Let’s see a number of the limitations of PIVOT tables:
- Requirement for a static column listing:
You’re required to explicitly outline all pivoted column values within the IN clause for the primary run of your pivot question. In case your information comprises new values later, new pivot output values won’t seem till the question is up to date manually. - Single mixture operate allowed for every pivot:
The PIVOT question operator permits just one aggregation for every pivot worth desk. So if you wish to calculate a number of aggregation features (e.g., SUM and COUNT), you could both do them in separate pivots or use conditional aggregation. - Poor portability:
PIVOT is restricted to SQL Server. Consequently, your implementation in numerous databases will probably require adjustments. Your queries won’t run in different databases with out these adjustments. - Efficiency hit for extensive pivots:
Once you pivot columns with numerous distinctive values, reminiscence issues are potential, resulting in diminished/capped efficiency. - Advanced dynamic pivots:
Dynamic pivoting requires constructing the PIVOT column values dynamically as a part of a dynamic SQL string. When you construct, you’ll be able to execute it utilizing sp_executesql. Though dynamic pivoting is interesting as a result of it permits extra flexibility in creating pivot values, it provides complexity and threat when needing to construct dynamic SQL. You need to at all times use parameterized queries when constructing dynamic SQL to keep away from SQL injection.
Dynamic Pivoting
When conditions come up and also you have no idea the values of your pivot columns beforehand, dynamic SQL can be utilized. Dynamic SQL is beneficial as a result of you’ll be able to question the distinct values of your pivot columns, construct the distinct values right into a string to construct your PIVOT question, and run it utilizing sp_executesql.
Dynamic pivoting, whereas offering flexibility, provides complexity and threat. It is vitally necessary that when constructing any dynamic SQL queries, you utilize parameterized queries to safeguard towards SQL injection.
Various: Conditional Aggregation
One of many extra in style alternate options to PIVOT is conditional aggregation with CASE expressions. This methodology is runnable in all SQL dialects and permits for a number of mixture features with ease.
Under is identical instance above utilizing conditional aggregation:
SELECT
Area,
SUM(CASE WHEN Product="Laptop computer" THEN SalesAmount ELSE 0 END) AS Laptop computer,
SUM(CASE WHEN Product="Mouse" THEN SalesAmount ELSE 0 END) AS Mouse,
SUM(CASE WHEN Product="Keyboard" THEN SalesAmount ELSE 0 END) AS Keyboard
FROM ProductSales
GROUP BY Area;This produces the identical outcome because the PIVOT instance, however has extra verbosity. The profit is portability and simpler enforcement of dynamic column conditions.

PIVOT vs. CASE Aggregation
PIVOT is a bit cleaner for easy cross-tabulation, however is much less versatile whenever you need multiple mixture, or dynamic columns. CASE-based aggregation is rather more verbose, however is runnable on many alternative database platforms, and adapts extra simply to ever-changing information.
Conclusion
The SQL Server PIVOT operator is a robust instrument for summarizing and reshaping information. And it excels when the listing of pivoted values is fastened and clear, and concise syntax is most well-liked over verbose alternate options. Nevertheless, it’s static in nature, and a single mixture limitation means it isn’t at all times the only option.
By mastering each PIVOT and CASE-based aggregation, you’ll be able to select the correct strategy for every reporting state of affairs. Whether or not you’re utilizing it for constructing month-to-month gross sales experiences, analyzing survey outcomes, or monitoring stock ranges, these strategies will can help you carry out transformations immediately inside SQL, decreasing the necessity for exterior processing and producing outcomes which are each correct and simple to interpret.
Regularly Requested Questions
It takes one column’s distinctive values and converts them into a number of columns within the outcome set, utilizing an mixture operate on one other column. It’s used for abstract experiences or cross-tab type experiences inside SQL Server.
No. SQL Server solely helps one mixture with the PIVOT operator. For those who require a number of aggregates (SUM and COUNT), you’ll need to both do two pivots and be part of them on a typical column or use CASE expressions with a GROUP BY clause.
A syntax error is normally on account of one among three causes:
You’re working it on a database that isn’t SQL Server (MySQL, PostgreSQL, or SQLite received’t perceive).
You forgot to alias the sub-query or the ultimate pivot outcome.
You left your IN listing clean or formatted incorrectly.
Sure, you at all times want to supply a static IN listing in a PIVOT question. In case your information adjustments and your pivot column has new values, you’ll have to manually replace the listing or create the question dynamically.
You may wrap the pivoted columns in ISNULL() or COALESCE().
Instance:
ISNULL([ColumnName], 0) — replaces NULL with 0
COALESCE([ColumnName], ‘N/A’) — replaces NULL with textual content
Not with this syntax. PIVOT is a SQL Server-only characteristic. In different databases, you’ll need to make use of CASE expressions and GROUP BY to realize the identical outcome.
The PIVOT is simpler to learn for easy summaries, but it surely’s not essentially quicker. CASE expressions work in every single place, which is a bonus whenever you want multiple mixture.
Hello, I’m Janvi, a passionate information science fanatic at present working at Analytics Vidhya. My journey into the world of knowledge started with a deep curiosity about how we will extract significant insights from advanced datasets.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}