
This weblog submit is co-written with Raj Samineni from ATPCO.
Launched at AWS re:Invent 2024, the following technology of Amazon SageMaker is expediting innovation for organizations akin to ATPCO via a unified knowledge administration and tooling expertise for analytics and AI use instances. This complete service supplies each technical and enterprise customers with Amazon SageMaker Unified Studio, a single knowledge and AI growth atmosphere to find the info and put it to work utilizing acquainted AWS instruments. SageMaker Unified Studio provides a single ruled atmosphere to finish end-to-end growth workflows, together with knowledge evaluation, knowledge processing, mannequin coaching, generative AI utility constructing, and extra. It simplifies the creation of analytics and AI functions, fast-tracking the journey from uncooked knowledge to actionable insights via its built-in knowledge and tooling atmosphere.
ATPCO is the spine of recent airline retailing, serving to airways and third-party channels ship the precise provides to prospects on the proper time. ATPCO’s imaginative and prescient is to be the platform driving innovation in airline retailing whereas remaining a trusted companion to the airline ecosystem. ATPCO goals to help data-driven decision-making by making high-quality knowledge discoverable by each enterprise unit, with the suitable governance on who can entry what, and required tooling to help their wants. ATPCO addressed knowledge governance challenges utilizing Amazon DataZone. SageMaker Unified Studio, constructed on the identical structure as Amazon DataZone, provides further capabilities, so customers can full varied duties akin to constructing knowledge pipelines utilizing AWS Glue and Amazon EMR, or conducting analyses utilizing Amazon Athena and Amazon Redshift question editor throughout numerous datasets, all inside a single, unified atmosphere.
On this submit, we stroll you thru the challenges ATPCO addresses for his or her enterprise utilizing SageMaker Unified Studio. We begin with the admin movement, a one-time setup course of that lays the muse for non-admin customers in preparation for a company-wide rollout. When onboarding customers from completely different enterprise models to SageMaker Unified Studio, it’s essential to verify they’ve fast entry to their knowledge sources akin to Amazon Easy Storage Service (Amazon S3), AWS Glue Information Catalog, and Redshift tables in addition to instruments like Amazon EMR, AWS Glue, and Amazon Redshift that they already use. This helps customers change into productive swiftly and use the complete potential of SageMaker Unified Studio. Subsequent, we stroll you thru the developer movement, detailing how non-admin customers can use SageMaker Unified Studio to entry their knowledge and act on it utilizing their selection of instruments.
“SageMaker Unified Studio has remodeled how our groups entry and collaborate on knowledge. It’s the primary time enterprise and technical customers can work collectively in a single, intuitive atmosphere—no extra software switching or fragmented workflows.”
–Rajesh Samineni, Director of Information Engineering at ATPCO
ATPCO’s challenges
The implementation of SageMaker Unified Studio at ATPCO has been instrumental in addressing a number of essential challenges and unlocking new use instances throughout varied enterprise models throughout the group. By constructing on the basis laid by Amazon DataZone, ATPCO helps customers self-serve insights and fostering a tradition of shared understanding and reusability of knowledge property, resulting in extra knowledgeable decision-making and a sturdy knowledge tradition.
SageMaker Unified Studio helped tackle the next challenges:
- Information silos and discoverability – Analysts typically struggled to find the precise knowledge sources, confirm knowledge freshness, and preserve constant definitions throughout completely different departments. By providing a single entry level for looking and subscribing to curated datasets, SageMaker Unified Studio minimizes these obstacles. Built-in instruments for knowledge exploration, querying, and visualization, together with contextual metadata and lineage, builds belief within the knowledge, making it simple for customers to seek out and use the knowledge they want.
- Handbook knowledge dealing with – Groups relied closely on handbook exports and customized studies to collect insights, resulting in inefficiencies and delays in decision-making. SageMaker Unified Studio helps customers throughout departments, together with product, gross sales, operations, and analytics, self-serve insights with out handbook intervention. This accelerates the decision-making course of and helps groups deal with strategic initiatives reasonably than knowledge assortment.
Answer overview
The next diagram illustrates ATPCO’s structure for SageMaker Unified Studio.
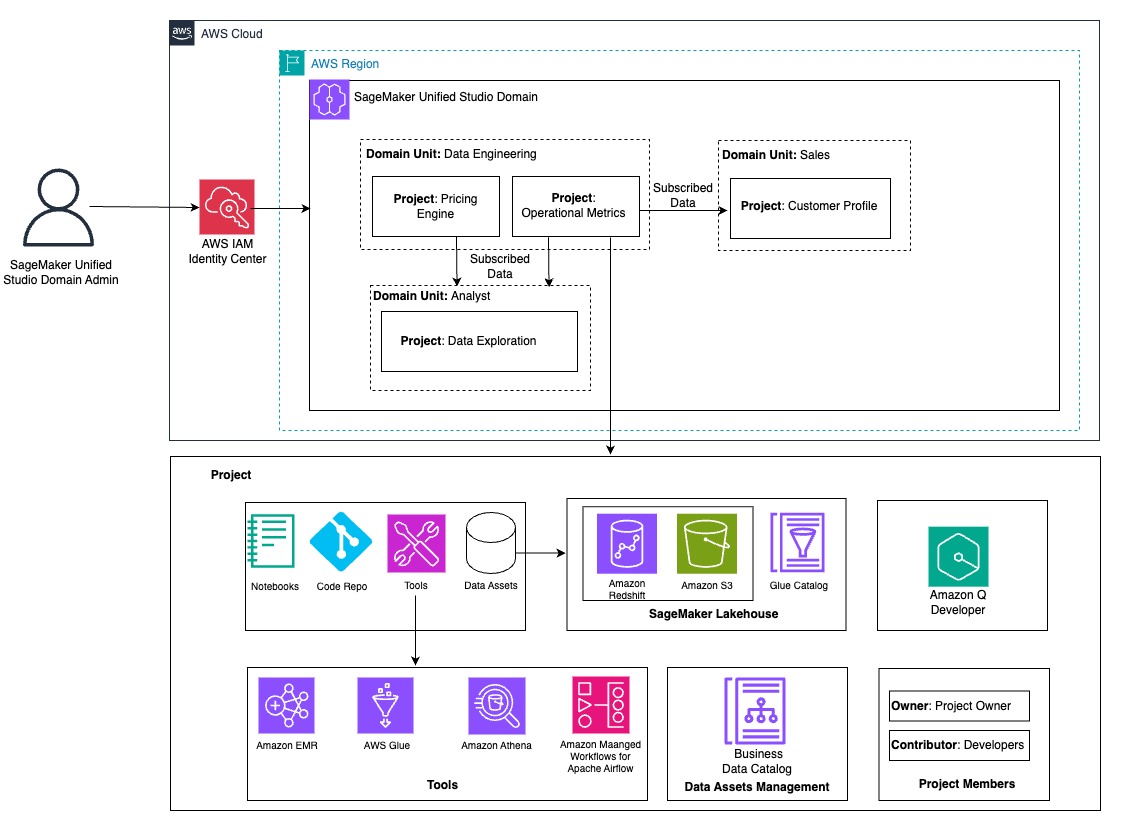
The next sections stroll you thru the steps that ATPCO went via to organize the SageMaker Unified Studio atmosphere to be used by completely different personas in engineering and enterprise models.
Conditions
When you’re new to SageMaker Unified Studio, you must first change into accustomed to ideas akin to domains, area models, initiatives, venture profiles, blueprints, lakehouses, and catalogs earlier than persevering with with this submit. For an organization-wide rollout of SageMaker Unified Studio, it’s necessary to grasp the muse setup required as an admin consumer. For extra details about the position of a SageMaker Unified Studio admin consumer and steps required to arrange a SageMaker Unified Studio area,confer with Foundational blocks of Amazon SageMaker Unified Studio: An admin’s information to implement unified entry to all of your knowledge, analytics, andAI. As an admin consumer, begin with area models and initiatives primarily based on the necessity of various enterprise models for the info and tooling.
Create area models and arrange initiatives with required instruments
As an admin or root area proprietor, you start with the design of area models and initiatives to arrange completely different groups and customers to their respective area models. When non-admin customers log in to the SageMaker Unified Studio portal, they need to have seamless entry to mandatory AWS sources. These sources embrace the required instruments and knowledge sources to carry out their job. Offering customers entry to those sources is essential for the profitable adoption and utilization of SageMaker Unified Studio in your group. ATPCO created separate area models for engineering groups and non-engineering enterprise models, as proven within the previous structure diagram. It solely reveals few examples. In actuality, they’ve extra area models to fulfill their enterprise wants, which we talk about within the following sections.
Information engineering area
This area unit has the Operational Metrics venture, managed by the info engineering workforce, which helps a key spine of visibility throughout the group: understanding how ATPCO’s merchandise carry out in actual time. Information engineers carry collectively indicators from infrastructure, utility logs, API monitoring, and inner programs to construct aggregated, curated datasets that observe latency, availability, adoption, and reliability. These operational metrics are revealed utilizing SageMaker Unified Studio for consumption by different domains. Moderately than fielding one-off requests or sustaining bespoke dashboards for various stakeholders, the engineering workforce now:
- Builds reusable knowledge property that may be subscribed to 1 time and reused by many
- Creates unified views of system well being which might be mechanically up to date and versioned
- Helps different groups akin to Product, Gross sales, and analysts with fast entry to efficiency indicators in a format aligned with their wants
SageMaker Unified Studio turns into the middle for operational intelligence, lowering duplication and ensuring knowledge engineers can deal with scale and automation reasonably than ticket-based help.
Analyst area
The Information Exploration venture on this area unit serves your complete ATPCO neighborhood. Its objective is to make out there datasets no matter their proudly owning area simply discoverable and prepared for evaluation. Beforehand, analysts struggled with finding the precise knowledge supply, verifying its freshness, or aligning on constant definitions. With SageMaker Unified Studio, these obstacles are eliminated. The venture supplies:
- A single entry level the place customers can search and subscribe to curated datasets
- Built-in instruments for exploration, question, and visualization
- Contextual metadata and lineage to construct belief within the knowledge
Customers in product, technique, operations, or analytics can self-serve insights with out ready on handbook exports or customized studies.
Gross sales area
The Buyer Profile venture on this area unit helps the Gross sales workforce perceive which prospects are actively partaking with ATPCO’s merchandise, how they’re utilizing them, and the place there is likely to be alternatives to strengthen relationships. By utilizing SageMaker Unified Studio, Gross sales workforce members can entry the next:
- Buyer knowledge sourced from CRM programs, together with interplay historical past, product adoption, and help engagement
- Operational metrics from the Information Engineering workforce, revealing which options are getting used, how typically, and whether or not the client is experiencing reliability points
With this mixed perception, the Gross sales workforce can accomplish the next:
- Establish high-value accounts for follow-up primarily based on latest utilization
- Detect drop-off in engagement or technical points earlier than a buyer raises a priority
- Tailor outreach and proposals utilizing goal knowledge, not assumptions
All of this occurs inside SageMaker Unified Studio, lowering the time spent on handbook knowledge gathering and enabling extra strategic, proactive buyer engagement.
Onboard knowledge sources to area models and initiatives
Now that area models and initiatives are created for various enterprise models, the following step is to onboard present Amazon S3 knowledge sources, Information Catalog tables, and database tables out there in Amazon Redshift. After logging in, customers have entry to the required knowledge and instruments. This required the ATPCO workforce to construct the stock to see which workforce has entry to what knowledge sources and what degree of permissions are wanted. For instance, the Information Engineering workforce wants entry to uncooked, processed and curated S3 buckets for constructing knowledge processing jobs. They need to additionally learn and write to the Information Catalog, and put together and write curated and aggregated knowledge to the Redshift tables. The next sections information you thru configuring these varied knowledge sources inside SageMaker Unified Studio, ensuring customers can entry the info sources to proceed their work in SageMaker Unified Studio.
Configure present Amazon S3 knowledge sources into SageMaker Unified Studio
To make use of an present S3 bucket in SageMaker Unified Studio, configure an S3 bucket coverage that enables the suitable actions for the venture AWS Identification and Entry Administration (IAM) position.
The Information Engineering workforce that owns the info processing pipeline should grant entry to uncooked, processed, and curated S3 buckets to the info engineering venture position. To be taught extra about utilizing present S3 buckets, confer with Entry your present knowledge and sources via Amazon SageMaker Unified Studio, Half 2: Amazon S3, Amazon RDS, Amazon DynamoDB, and Amazon EMR.
Configure an present Information Catalog into SageMaker Unified Studio
The subsequent technology of SageMaker is constructed on a lakehouse structure, which streamlines cataloging and managing permissions on knowledge from a number of sources. Constructed on the Information Catalog and AWS Lake Formation, it organizes knowledge via catalogs that may be accessed via an open, Apache Iceberg REST API to assist implement safe entry to knowledge with constant, fine-grained entry controls. SageMaker Lakehouse organizes knowledge entry via two kinds of catalogs: federated catalogs andmanaged catalogs (proven within the following determine). A catalog is a logical container that organizes objects from a knowledge retailer, akin to schemas, tables, views, or materialized views from Amazon Redshift. The next diagram illustrates this structure.
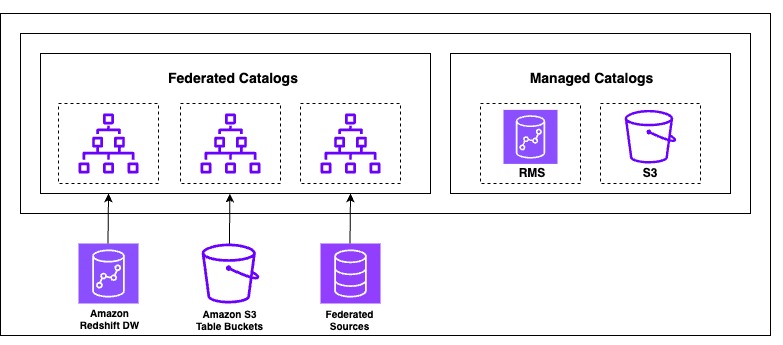
ATPCO constructed a knowledge lake on Amazon S3 utilizing the Information Catalog and applied knowledge governance and fine-grained entry management utilizing Lake Formation. When developer customers log in to SageMaker Unified Studio, they want entry to the Information Catalog tables owned by their respective workforce. Current Information Catalog databases are made out there in SageMaker Lakehouse as a federated catalog as a result of they’re created outdoors of SageMaker Lakehouse and never managed by it.
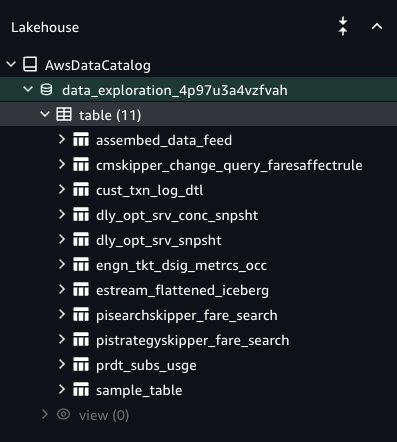
To entry an present Information Catalog, you will need to present express permissions to SageMaker Unified Studio to have the ability to entry the Information Catalog databases and tables. For extra particulars, see Configure Lake Formation permissions for Amazon SageMaker Unified Studio. To onboard Information Catalog tables to SageMaker Lakehouse in SageMaker Unified Studio, the Lake Formation admin should grant entry to particular Information Catalog database tables to the SageMaker Unified Studio venture position. For extra particulars, confer with Entry your present knowledge and sources via Amazon SageMaker Unified Studio, Half 1: AWS Glue Information Catalog and Amazon Redshift. The Lake Formation permission mannequin is the prerequisite to grant entry to SageMaker Unified Studio. If Lake Formation just isn’t the permission mannequin for the Information Catalog, then you will need to register the S3 path and delegate the permission mannequin to Lake Formation earlier than it may be granted to the SageMaker Unified Studio venture position. After you full these steps, customers of the venture can entry the Information Catalog database and are granted tables beneath the AwsDataCatalog namespace, and your tables shall be seen within the Information Explorer (see the next screenshot). Your knowledge is now prepared for tagging, looking, enrichment, and knowledge evaluation.
Configure Redshift knowledge into SageMaker Unified Studio
ATPCO depends on Amazon Redshift as their enterprise knowledge warehouse and shops their aggregated knowledge for insights and dashboarding. Customers can mix the info from Amazon Redshift and SageMaker Lakehouse for unified knowledge evaluation in SageMaker Unified Studio with out leaving SageMaker Unified Studio. For extra details about the right way to add present Redshift knowledge sources, confer with Entry your present knowledge and sources via Amazon SageMaker Unified Studio, Half 1: AWS Glue Information Catalog and Amazon Redshift.
After it’s linked, the Amazon Redshift compute engine turns into seen within the Information Explorer of your venture. Mission customers can carry out the next actions:
- Write and run SQL queries immediately in opposition to Amazon Redshift
- Discover Redshift schemas and tables
- Use Redshift tables to outline SageMaker Unified Studio knowledge sources
- Mix Redshift knowledge with metadata tagging, glossary linking, and publishing
This doesn’t require copying or duplicating knowledge. You’re utilizing the info precisely the place it lives in your Redshift cluster whereas benefiting from the collaborative options of SageMaker Unified Studio. Including compute makes the info throughout the warehouse out there to question contained in the SageMaker Unified Studio question editor.
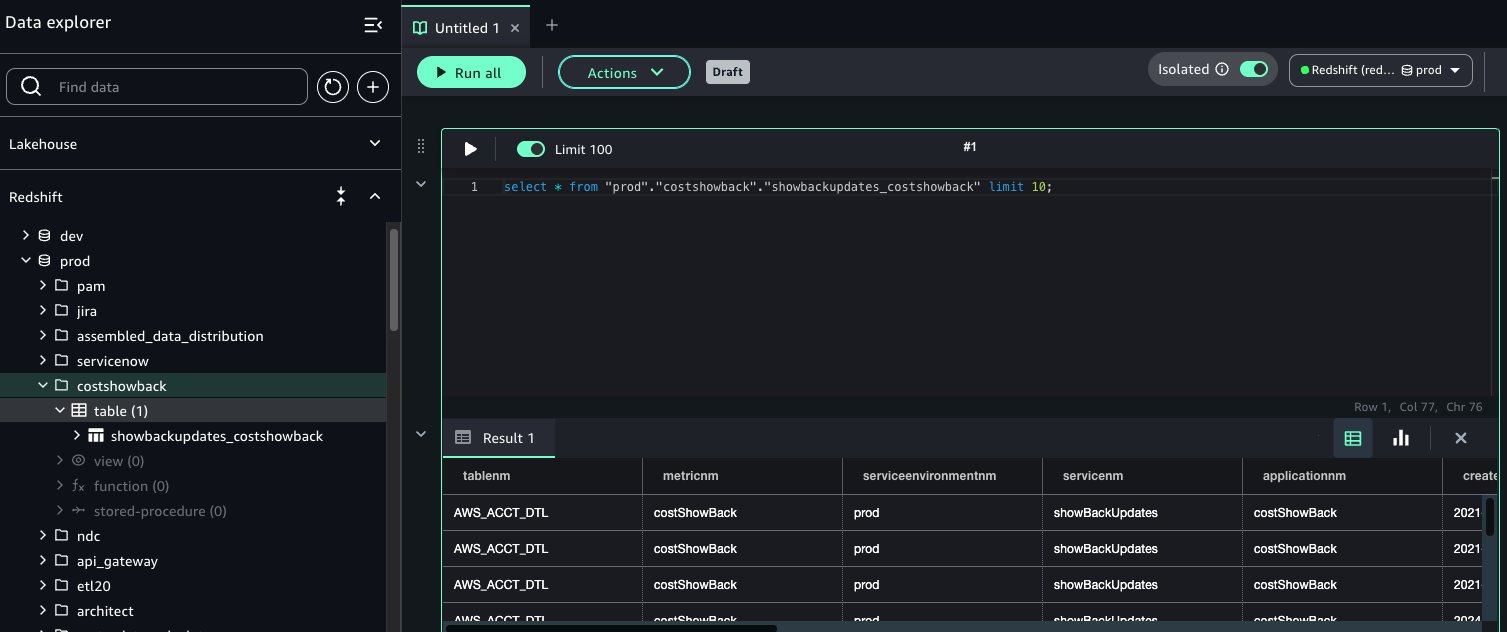
Onboard customers to their respective area models and initiatives
Now that as an admin you’ve got created the environments for various enterprise models, the next move is so as to add area proprietor customers to the respective area models. First, you will need to add area and venture house owners’ customers for them to get entry to the SageMaker Unified Studio area portal.
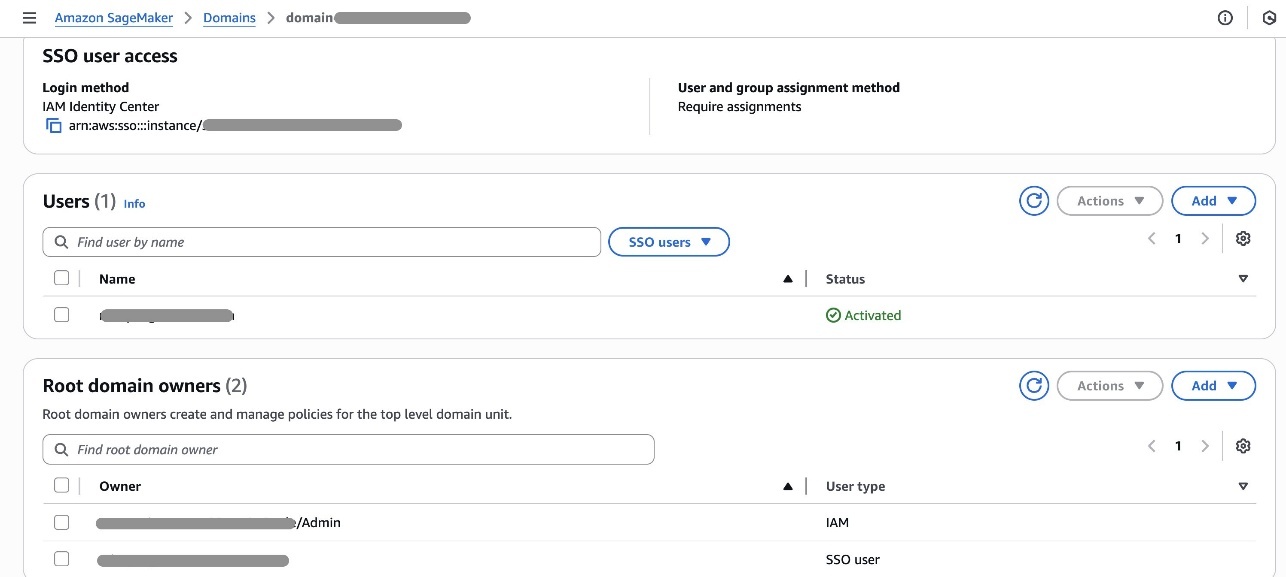
Area models make it attainable to arrange your property and different area entities beneath particular enterprise models and groups. Area unit house owners can create insurance policies akin to membership, area, and venture creation.
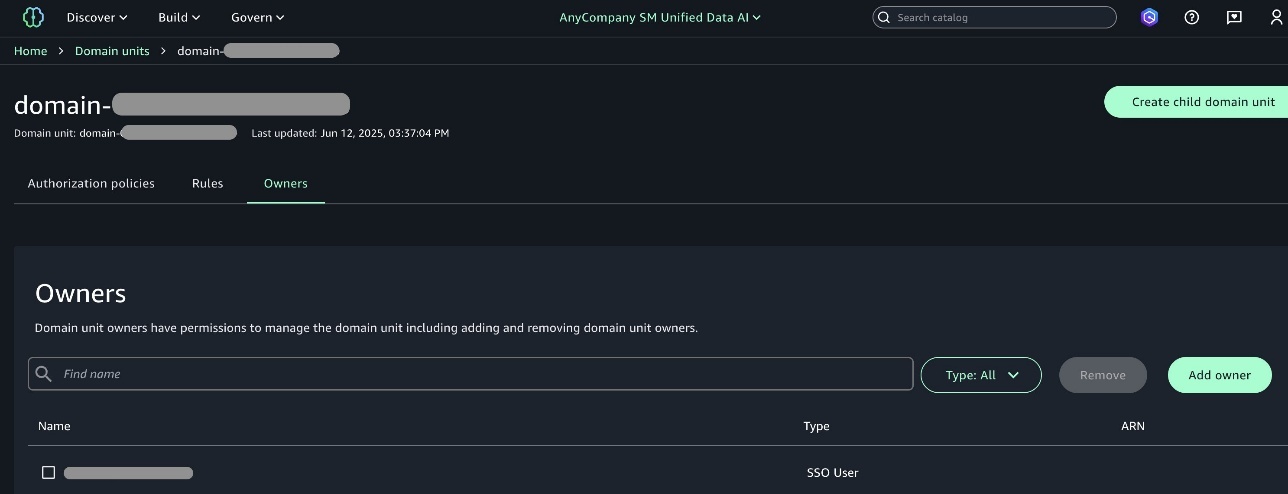
Area unit house owners can add one of many members as proprietor of the venture in order that when the proprietor consumer logs in, they’ll add different customers of their workforce as an proprietor or contributor to the venture. This helps different customers get entry to the initiatives after they login to SageMaker Unified Studio.
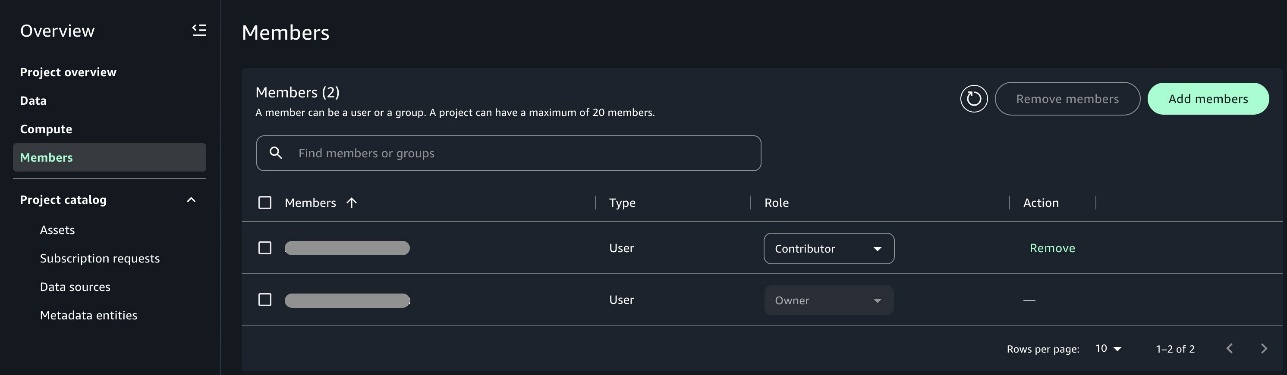
Use the SageMaker Unified Studio atmosphere
After the admin completes the required setup for various enterprise models and onboardsproject members, customers can log in to the portal and begin utilizing the preconfigured SageMaker Unified Studio atmosphere. Customers have entry to respective knowledge sources and instruments as proven within the following developer movement diagram.
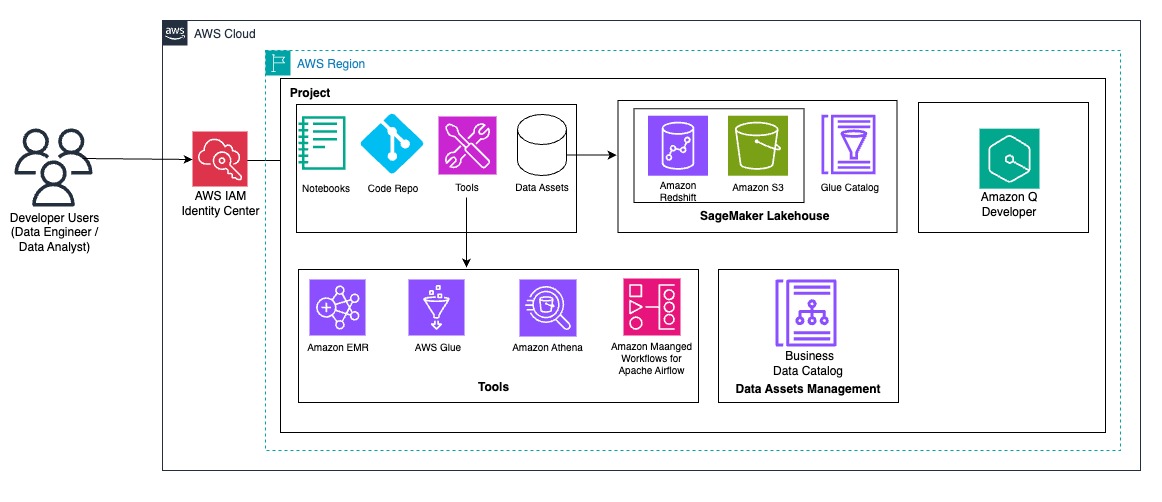
At ATPCO, builders should typically mix knowledge from varied sources to carry out extract, rework, and cargo (ETL) processes effectively. On this part, we reveal how builders can profit from the SageMaker unified lakehouse atmosphere by seamlessly integrating knowledge from each Amazon Redshift and the Information Catalog. Utilizing PySpark inside SageMaker Unified Studio notebooks, we learn transactional knowledge from Amazon Redshift and enrich it with metadata saved in AWS Glue backed S3 tables akin to warehouse or product attributes. This built-in view helps advanced transformations and aggregations throughout disparate sources with no need to maneuver or duplicate knowledge. By utilizing native connectors and Spark’s distributed processing, customers can be a part of, filter, and analyze multi-source datasets effectively and write the outcomes again to Amazon Redshift for downstream analytics or dashboarding, all inside a single, interactive lakehouse interface.
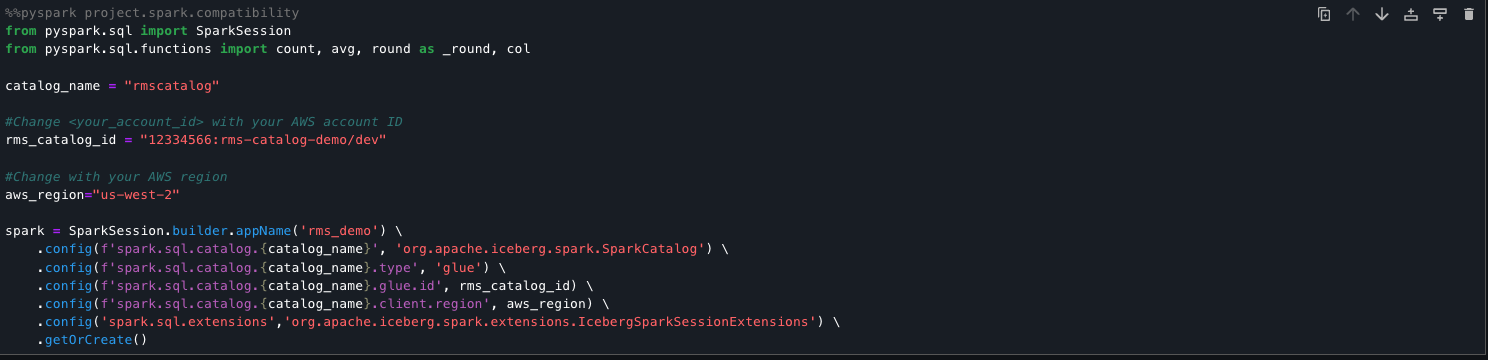
The next code snippet units up a Spark session to immediately question Amazon Redshift managed storage tables utilizing the lakehouse structure. It registers an AWS Glue backed Iceberg catalog (rmscatalog) that factors to a particular Redshift lakehouse catalog and database, permitting Spark to learn from and write to Redshift Iceberg tables. By enabling Iceberg extensions and linking the catalog to AWS Glue and Lake Formation, this setup supplies seamless, scalable entry to Amazon Redshift managed knowledge utilizing normal Spark SQL.
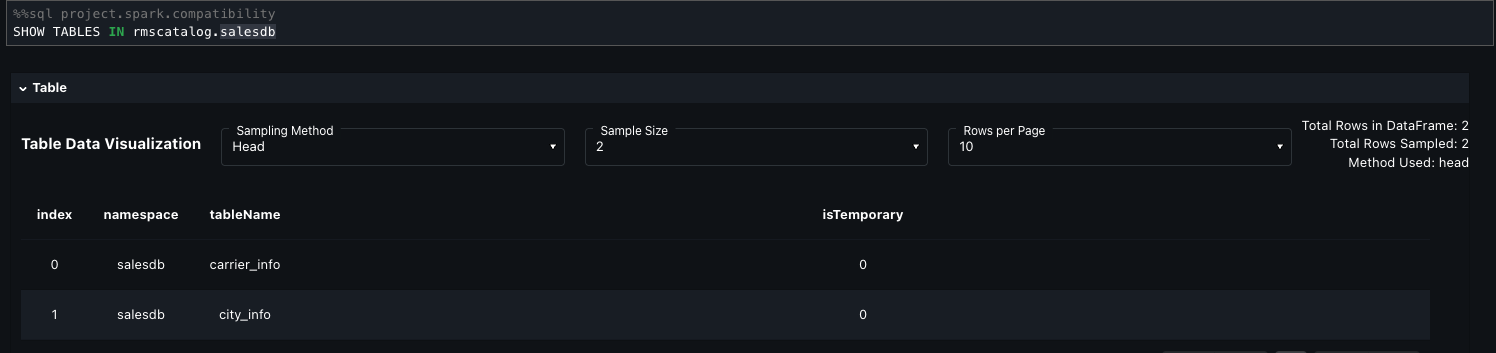
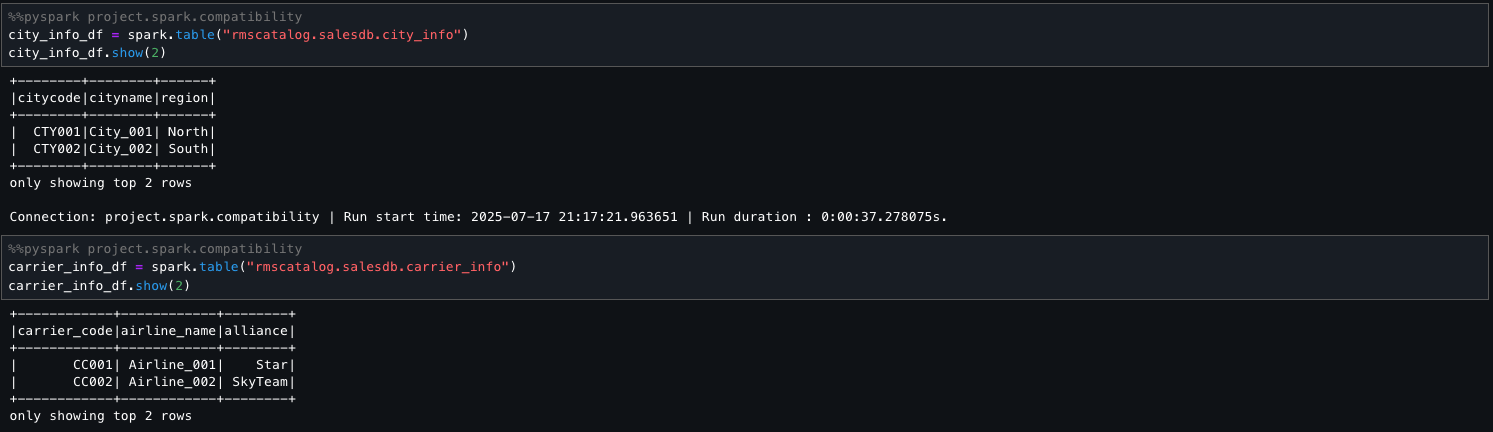
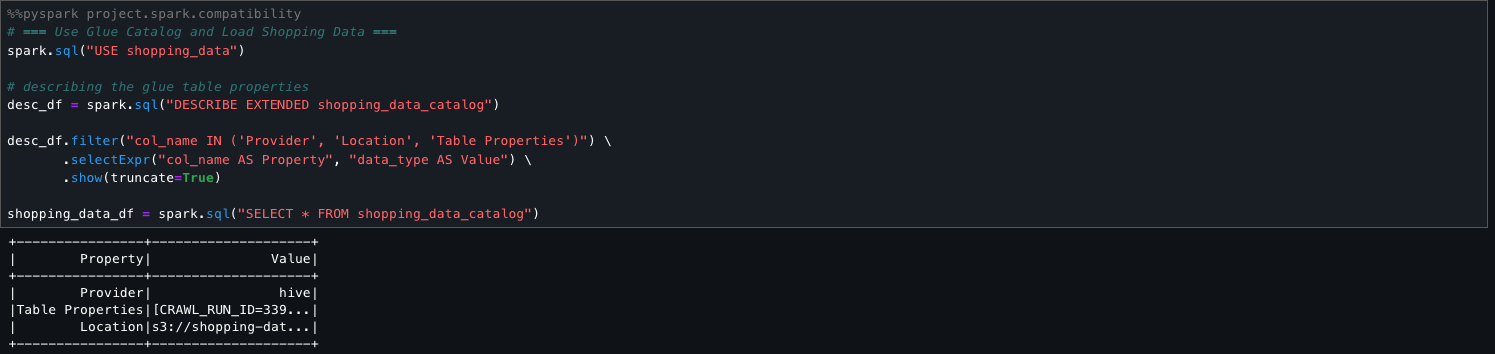
The next step units the energetic AWS Glue database to shopping_data and retrieves metadata for the shopping_data_catalog desk utilizing DESCRIBE EXTENDED. It filters for key properties like Supplier, Location, and Desk Properties to grasp the desk’s storage and configuration. Lastly, it hundreds your complete desk right into a Spark DataFrame (shopping_data_df) for downstream processing.
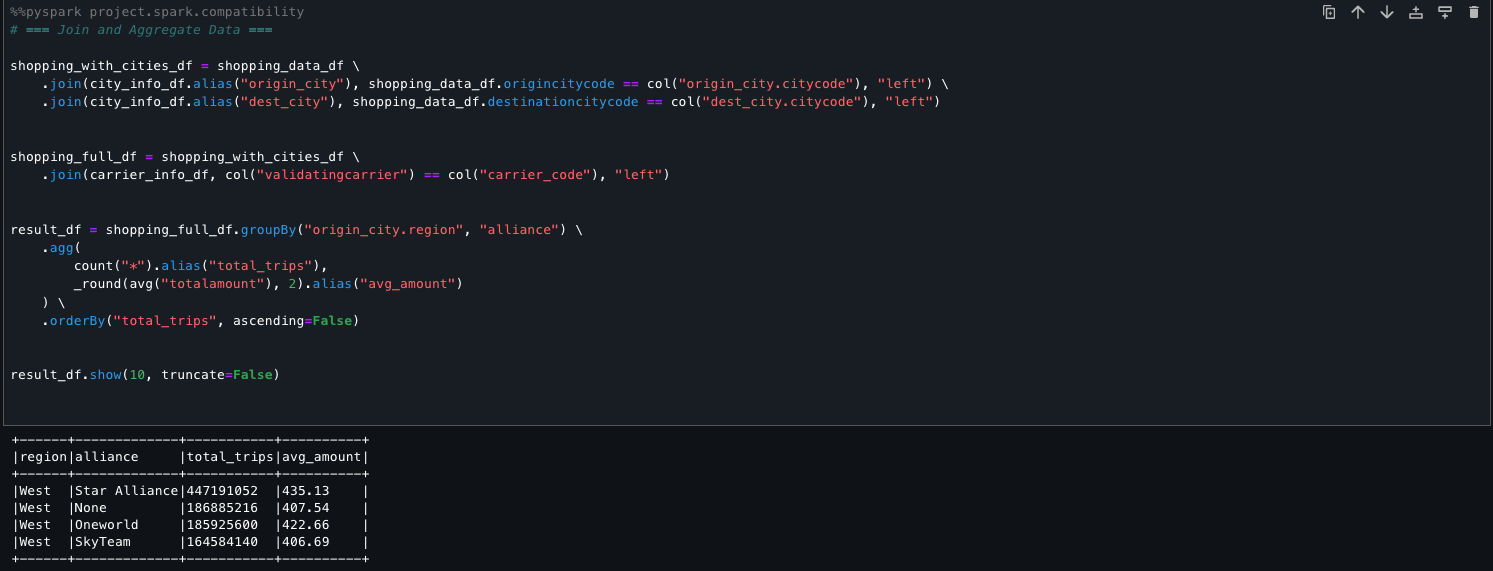
The next code reveals how one can seamlessly mix and mixture two disparate knowledge sources, Amazon Redshift and the Information Catalog, inside SageMaker Unified Studio. Utilizing PySpark, we carry out transformations and derive significant summaries throughout the unified view. This facilitates streamlined evaluation and reporting with out the necessity for advanced knowledge motion or duplication.
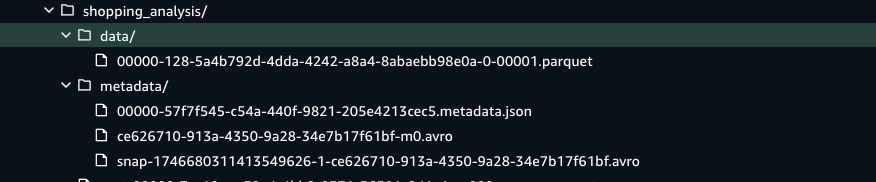
After the job runs, it writes the remodeled dataset immediately right into a Information Catalog desk that’s Iceberg-compatible. This integration makes certain the info is saved in Amazon S3 with ACID transaction help, and in addition registered and tracked within the Information Catalog for unified governance, schema discovery, and downstream question entry. The Iceberg desk format organizes the info into Parquet information beneath a knowledge/ listing and maintains wealthy versioned metadata in a metadata/ folder, supporting options like schema evolution, time journey, and partition pruning. This design facilitates scalable, dependable, and SQL-compatible analytics on fashionable knowledge lakes.

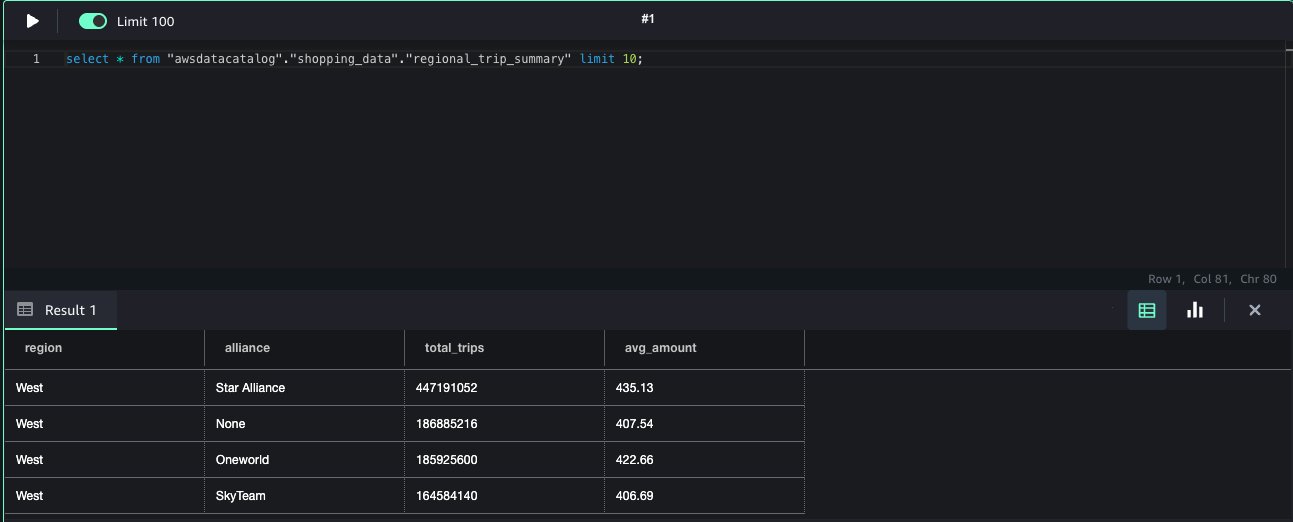
The desk turns into instantly out there for querying via the Athena question editor, offering interactive entry to recent, transactional knowledge with out further ingestion steps or handbook registration.This method streamlines the end-to-end knowledge movement, from processing in Spark to interactive querying in Athena throughout the fashionable SageMaker Lakehouse atmosphere.
Conclusion
This submit walked you thru the steps to organize a SageMaker Unified Studio atmosphere for a company-wide rollout, utilizing APTCO’s journey for example. We lined the area design and admin movement, which is a one-time setup to organize the SageMaker Unified Studio atmosphere for various groups within the group who requires completely different ranges of entry to the info and instruments. After the admin movement, we demonstrated the developer movement and the right way to use instruments like a Jupyter pocket book and SQL editor to make use of the info throughout completely different sources akin to Amazon S3, the Information Catalog, and Redshift property to carry out a unified evaluation.
Check out this answer and get began with SageMaker Unified Studio and modernize with the following technology of SageMaker. To be taught extra about SageMaker Unified Studio and the right way to get began, confer with the Amazon SageMaker Unified Studio Administrator Information, and the newest AWS Massive Information Weblog posts.
Concerning the authors
 Mitesh Patel is a Principal Options Architect at AWS. His ardour helps prospects harness the ability of Analytics, Machine Studying, AI & GenAI to drive enterprise progress. He engages with prospects to create modern options on AWS.
Mitesh Patel is a Principal Options Architect at AWS. His ardour helps prospects harness the ability of Analytics, Machine Studying, AI & GenAI to drive enterprise progress. He engages with prospects to create modern options on AWS.
 Nikki Rouda works in product advertising and marketing at AWS. He has a few years expertise throughout a variety of IT infrastructure, storage, networking, safety, IoT, analytics, and fashionable functions.
Nikki Rouda works in product advertising and marketing at AWS. He has a few years expertise throughout a variety of IT infrastructure, storage, networking, safety, IoT, analytics, and fashionable functions.
 Raj Samineni is the Director of Information Engineering at ATPCO, main the creation of superior cloud-based knowledge platforms. His work ensures strong, scalable options that help the airline business’s strategic transformational goals. By leveraging machine studying and AI, Raj drives innovation and knowledge tradition, positioning ATPCO on the forefront of technological development.
Raj Samineni is the Director of Information Engineering at ATPCO, main the creation of superior cloud-based knowledge platforms. His work ensures strong, scalable options that help the airline business’s strategic transformational goals. By leveraging machine studying and AI, Raj drives innovation and knowledge tradition, positioning ATPCO on the forefront of technological development.
 Saurabh Rawat is a Answer Architect at AWS with 13 years of expertise working with enterprise knowledge programs. He has designed and delivered large-scale, cloud-native options for purchasers throughout industries, with a deal with knowledge engineering, analytics, and well-architected architectures. Over his profession, he has helped organizations modernize their knowledge platforms, optimize for efficiency, and value, and undertake finest practices for scalability and safety. Outdoors of labor, he’s a passionate musician and enjoys enjoying together with his band.
Saurabh Rawat is a Answer Architect at AWS with 13 years of expertise working with enterprise knowledge programs. He has designed and delivered large-scale, cloud-native options for purchasers throughout industries, with a deal with knowledge engineering, analytics, and well-architected architectures. Over his profession, he has helped organizations modernize their knowledge platforms, optimize for efficiency, and value, and undertake finest practices for scalability and safety. Outdoors of labor, he’s a passionate musician and enjoys enjoying together with his band.

{kind=link}