
Sustaining excessive availability and fast incident response for Amazon EMR clusters is vital in information analytics environments. On this publish, we present you construct an automatic observability system that mixes Amazon Managed Grafana with Amazon Bedrock to detect and remediate EMR cluster points. We show combine real-time monitoring with AI-powered remediation ideas, combining Amazon Managed Grafana for visualization, Amazon Bedrock for clever response suggestions, and AWS Programs Supervisor for automated remediation actions on Amazon Net Providers (AWS).
Resolution overview
This resolution helps you enhance EMR cluster observability by way of a complete four-layer structure—comprising monitoring, notification, remediation, and information administration—to supply the next options:
- Actual-time monitoring of EMR clusters utilizing Amazon Managed Service for Prometheus and Amazon Managed Grafana
- Automated first-aid remediation by way of Programs Supervisor
- AI-powered incident response ideas utilizing Amazon Bedrock
- Integration with the AWS Premium Help information base
- Historic incident information archival and evaluation
The implementation of this structure delivers the next key profit:
- Decreased Imply time to decision (MTTR)
- Proactive incident prevention
- Automated first-response actions
- Information base enrichment by way of machine studying
The next diagram illustrates the answer structure.
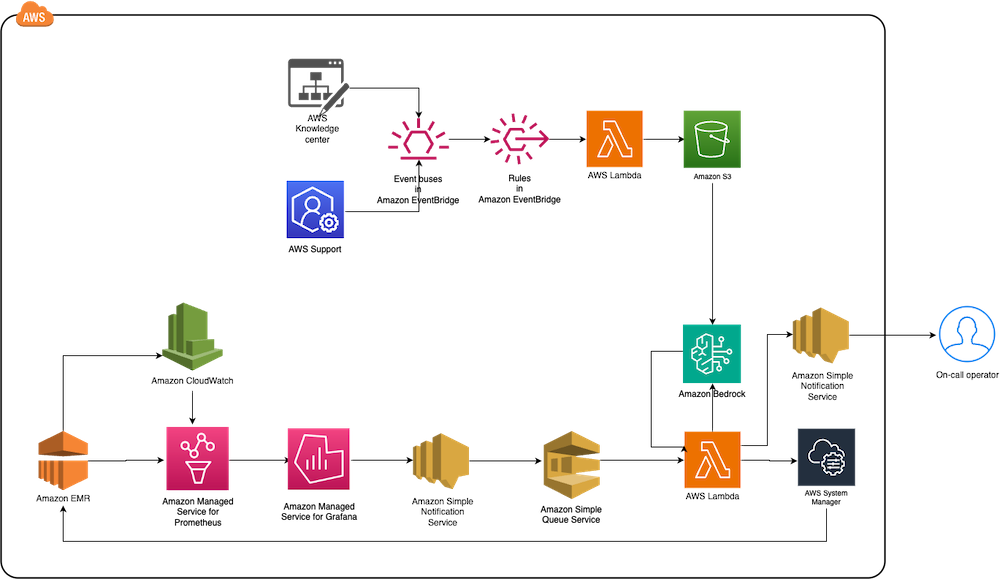
The structure contains the next core elements:
- Monitoring layer – The monitoring layer makes use of Amazon Managed Service for Prometheus and Amazon CloudWatch to seize real-time metrics from EMR clusters. Amazon Managed Grafana serves because the visualization layer, providing complete dashboards for Apache YARN, HDFS, Apache HBase, and Apache Hudi efficiency monitoring. Superior alerting mechanisms set off notifications primarily based on predefined question outcomes.
- Notification layer – To offer well timed and dependable alert supply, the notification layer makes use of Amazon Easy Notification Service (Amazon SNS) for distribution and Amazon Easy Queue Service (Amazon SQS) for message queuing. This structure prevents message delays and supplies a strong set off mechanism for AWS Lambda capabilities.
- Remediation layer – The remediation layer allows computerized challenge decision by way of:
- Lambda capabilities for orchestration
- Programs Supervisor for script execution
- Amazon Bedrock (amazon.nova-lite-v1:0) for producing clever response suggestions
- Information administration layer – To take care of an up-to-date information base, the answer:
We offer an AWS CloudFormation template to deploy the answer assets.
Conditions
Earlier than beginning this walkthrough, ensure you have entry to the next AWS assets and configurations:
- An AWS account
- Entry to the US East (N. Virginia) AWS Area
- Add entry to Amazon Bedrock basis fashions (amazon.nova-lite-v1:0)
- Amazon EMR model 6.15.0 (used on this demo)
- Archived technical or troubleshooting articles
- AWS IAM Identification Middle enabled with no less than one function that may change into a Grafana administrator
- (Non-compulsory) AWS Premium Help with a enterprise assist plan or greater for enhanced troubleshooting capabilities
All through this walkthrough, we offer detailed directions to arrange and configure these conditions if you happen to haven’t already carried out so.
Configure assets utilizing AWS CloudFormation
Full the next steps to configure your assets:
- Launch the CloudFormation stack:
![]()
- Present
emrobservabilitybecause the stack title. - Choose a digital non-public cloud (VPC) and assign a public subnet.
- For EMRClusterName, enter a reputation to your cluster (default:
emrObservability). - Enter an present Amazon S3 location because the Apache HBase root listing location (for instance,
s3://mybucket/my/hbase/rootdir/). - For MasterInstanceType and CoreInstanceType, enter your occasion sorts (default: m5.xlarge for each).
- For CoreInstanceCount, enter your occasion rely (default: 2).
- For SSHIPRange, use CheckIp and enter your IP (for instance, 10.1.10/32).
- Select the discharge label (default: 6.15.0).
- For KeyName, enter a key title to SSH to Amazon Elastic Compute Cloud (Amazon EC2) situations.
- For LatestAmiId, enter your AMI (default:
/aws/service/ami-amazon-linux-latest/amzn2-ami-hvm-x86_64-gp2). - For KBS3Bucket, enter a reputation to your S3 bucket (for instance,
mykbbucket). - For SubscriptionEndpoint, enter an e-mail deal with to obtain notifications and responses (for instance,
[email protected]).
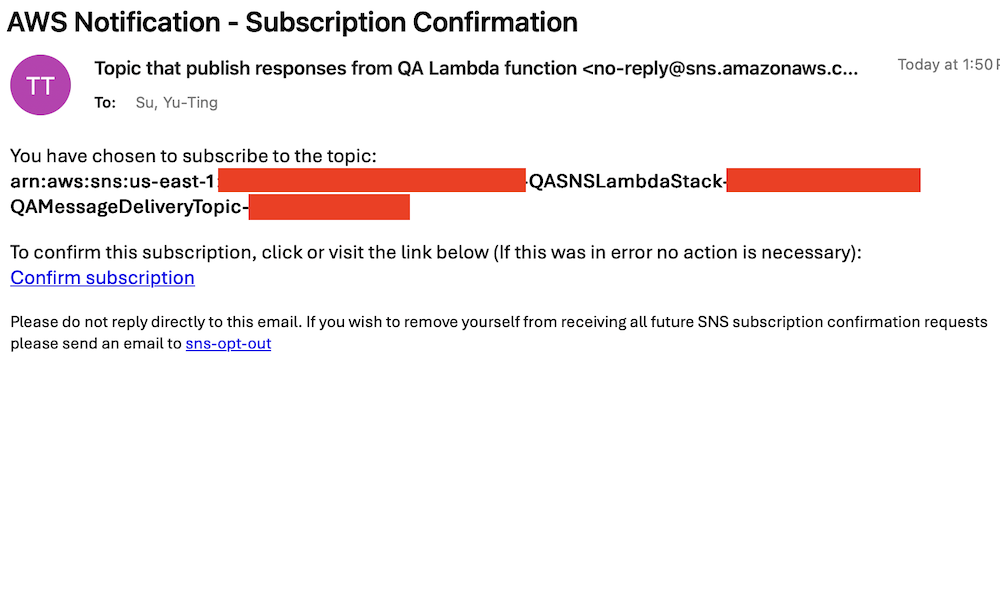
Settle for subscription affirmation
Settle for the subscription affirmation despatched to the e-mail deal with you specified within the CloudFormation stack parameters. The next screenshot reveals an instance of the e-mail you obtain.
Put together the information base
Full the next steps to populate the S3 bucket with archived technical articles and circumstances:
- On the Lambda console, select Capabilities within the navigation pane.
- Select the perform
CustomFunctionCopyKCArticlesToS3Bucket.
- Manually invoke the perform by selecting Check on the Check tab.
- Confirm profitable execution by checking the CloudWatch logs.
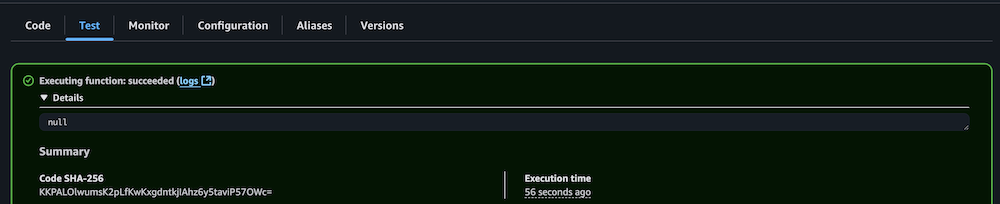
- Repeat the method for the Lambda perform
CustomFunctionCopyCasesToS3Bucket.

- Affirm the S3 bucket has been populated with archived technical articles and circumstances.
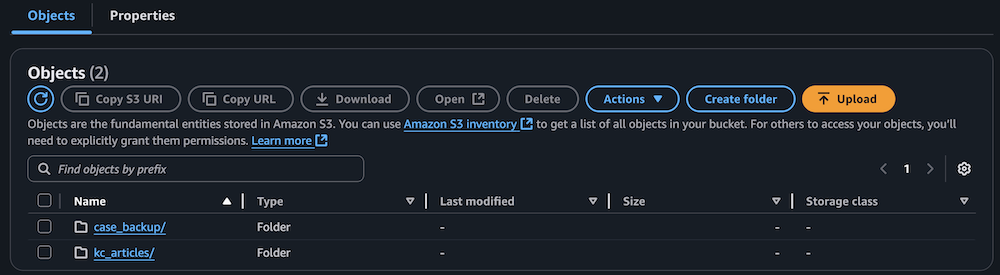
Sync information to the Amazon Bedrock information base
Full the next steps to sync the information to your information base:
- On the Lambda console, select Capabilities within the navigation pane.
- Select the perform
KBDataSourceSync.
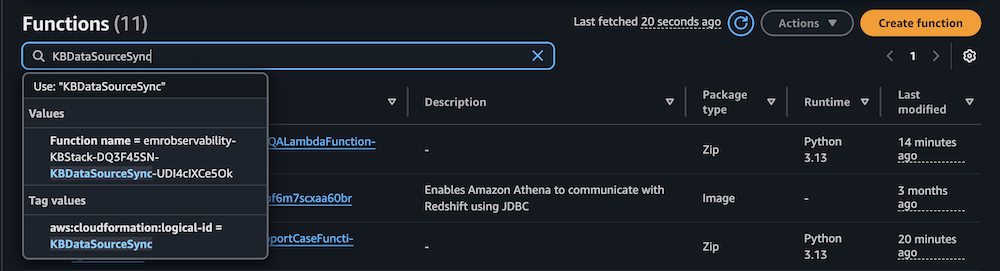
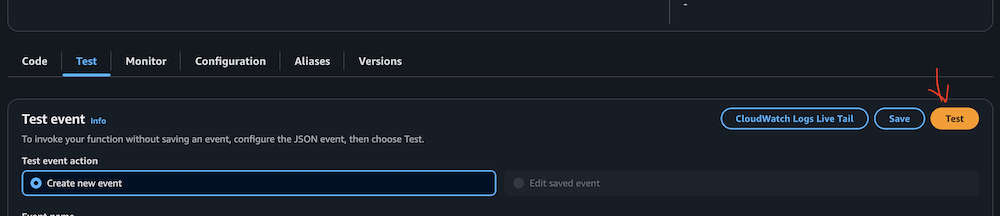
- Manually invoke the perform by selecting Check on the Check tab.
This activity would possibly take 10–quarter-hour to finish.
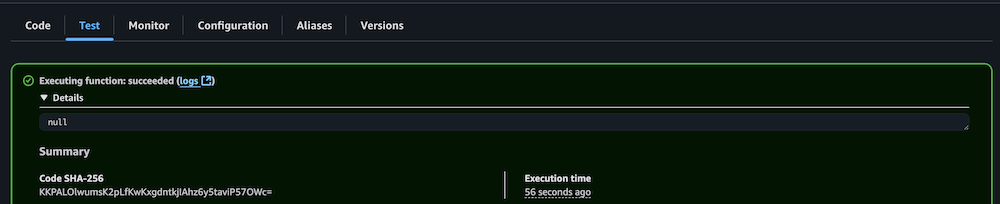
- Confirm profitable execution by checking the CloudWatch logs.
Configure your Amazon Managed Grafana workspace
Full the next steps to configure your Amazon Managed Grafana workspace:
- On the Amazon Managed Grafana console, select Workspaces within the navigation pane.
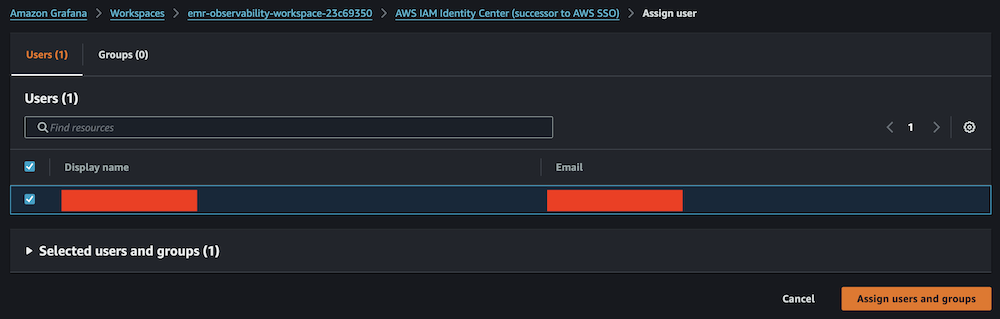
- Open your workspace.
- Select Assign new person or group.

- Choose your IAM Identification Middle function and select Assign customers and teams.
- On the Admin dropdown menu, select Make admin.

- Allow Grafana alerting, then select Save modifications.

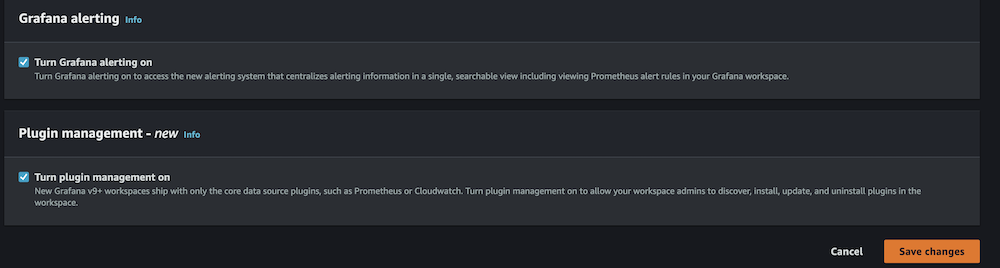
- Wait 10 minutes for the workspace to change into energetic.
- When it’s energetic, sign up to the Grafana workspace. (For extra info, consult with Connect with your workspace.)
Configure information sources
Add and configure the next information sources:
- For Service, select CloudWatch, then choose your Area and add CloudWatch as a knowledge supply.

- Select Amazon Managed Service for Prometheus as a second information supply and choose your Area.

- Validate CloudWatch connectivity:
- Run take a look at queries (for instance, Namespace:
AWS/EC2, Metric title:CPUUtilization, Statistic:Most).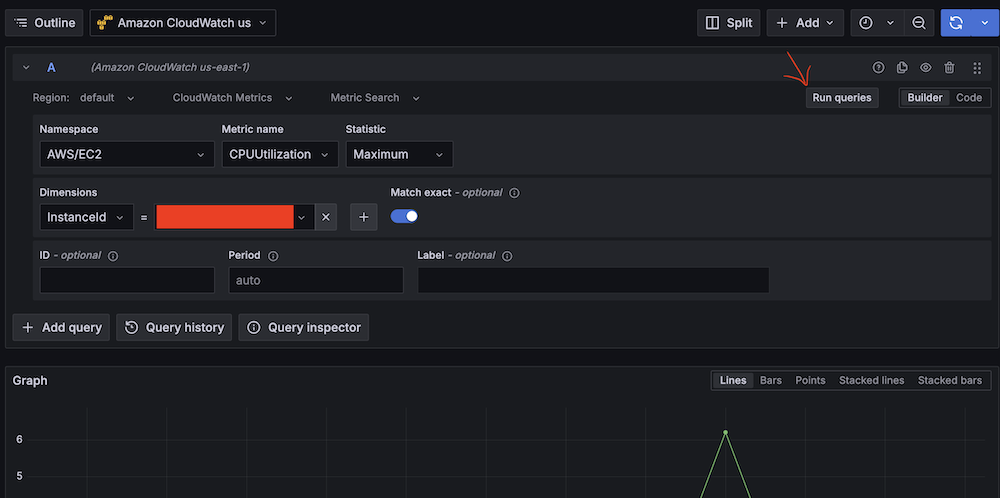
- Confirm CloudWatch metric retrieval.
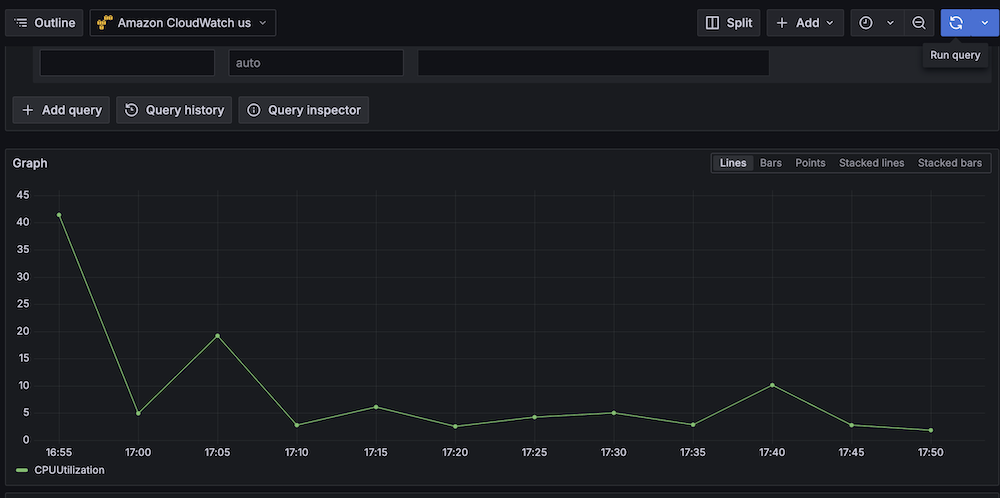
- Run take a look at queries (for instance, Namespace:
- Validate Amazon Managed Service for Prometheus connectivity:
- Run take a look at queries (for instance, Metric:
hadoop_hbase_numregionservers, Label filters:cluster_id =).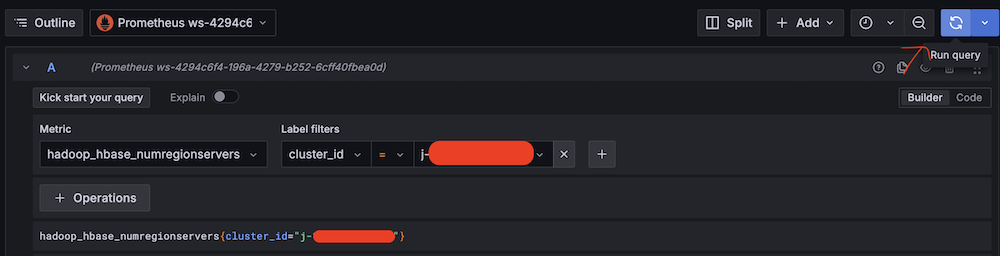
- Confirm Prometheus metric retrieval.
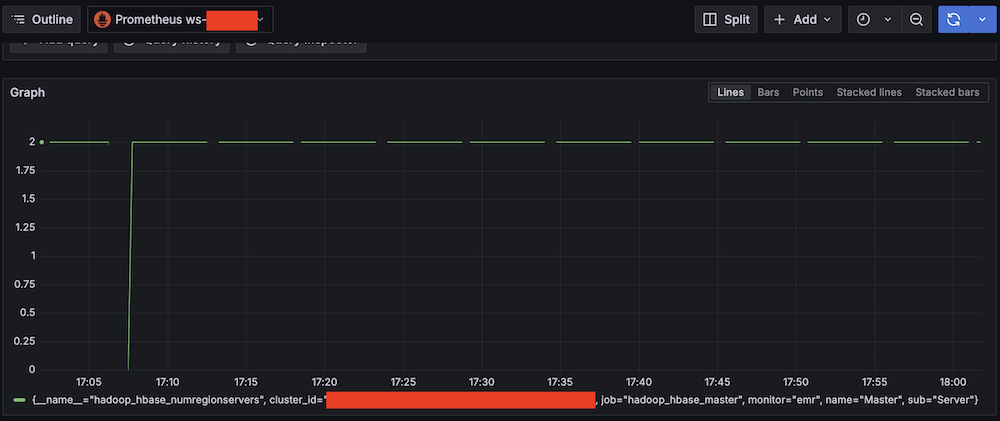
- Run take a look at queries (for instance, Metric:
Affirm SNS notification channels
Full the next steps to substantiate your SNS notification is ready up:
- On the Amazon SNS console, select Matters within the navigation pane.
- Find and notice the ARNs for
-LambdaFunctionTopicand-QALambdaFunctionTopic.


- Select Contact factors below Alerting.
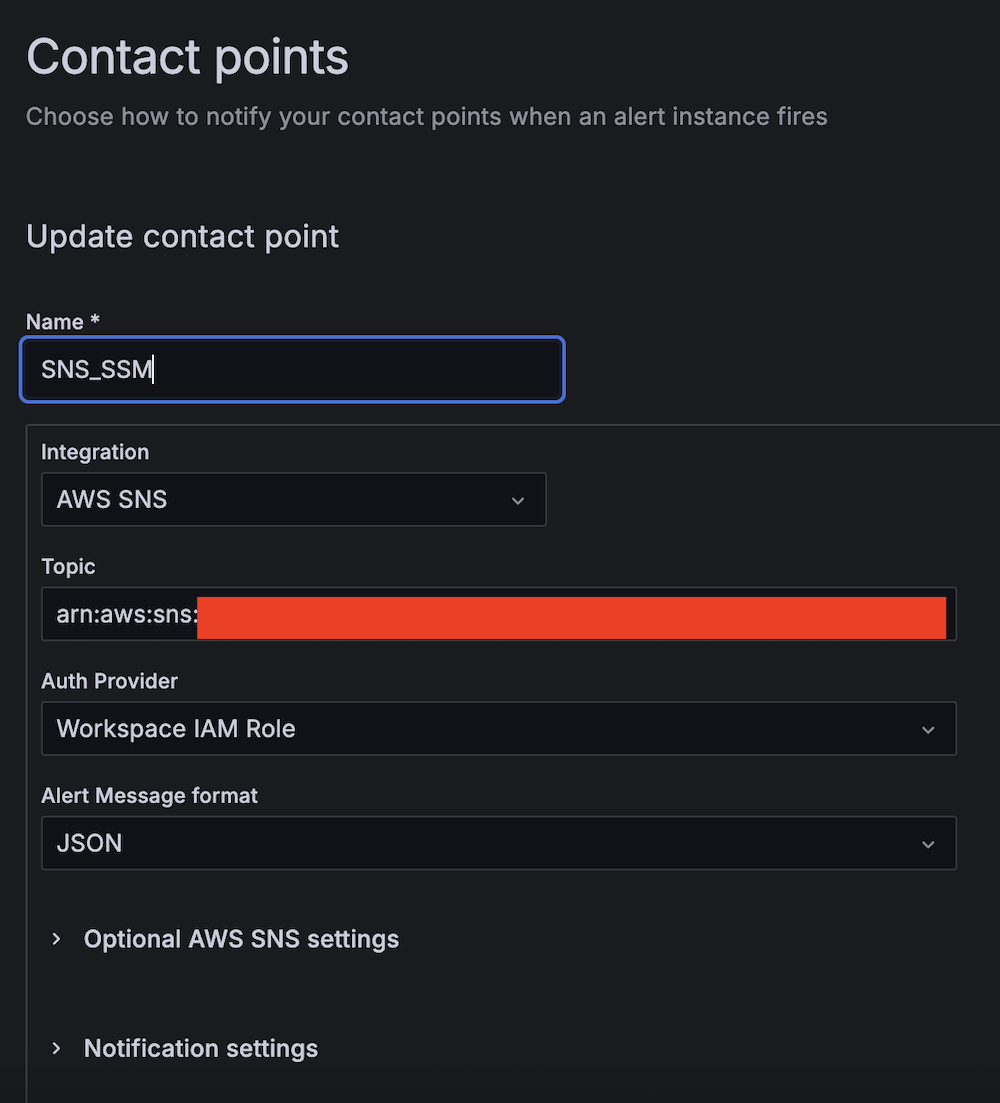
- Create the primary contact level:
- For Identify, enter SNS_SSM.
- For Integration, select AWS SNS.
- For Subject, enter the ARN for LambdaFunctionTopic.
- For Auth Supplier, select Workspace IAM function.
- For Alert Message format, select JSON.
- Create the second contact level:
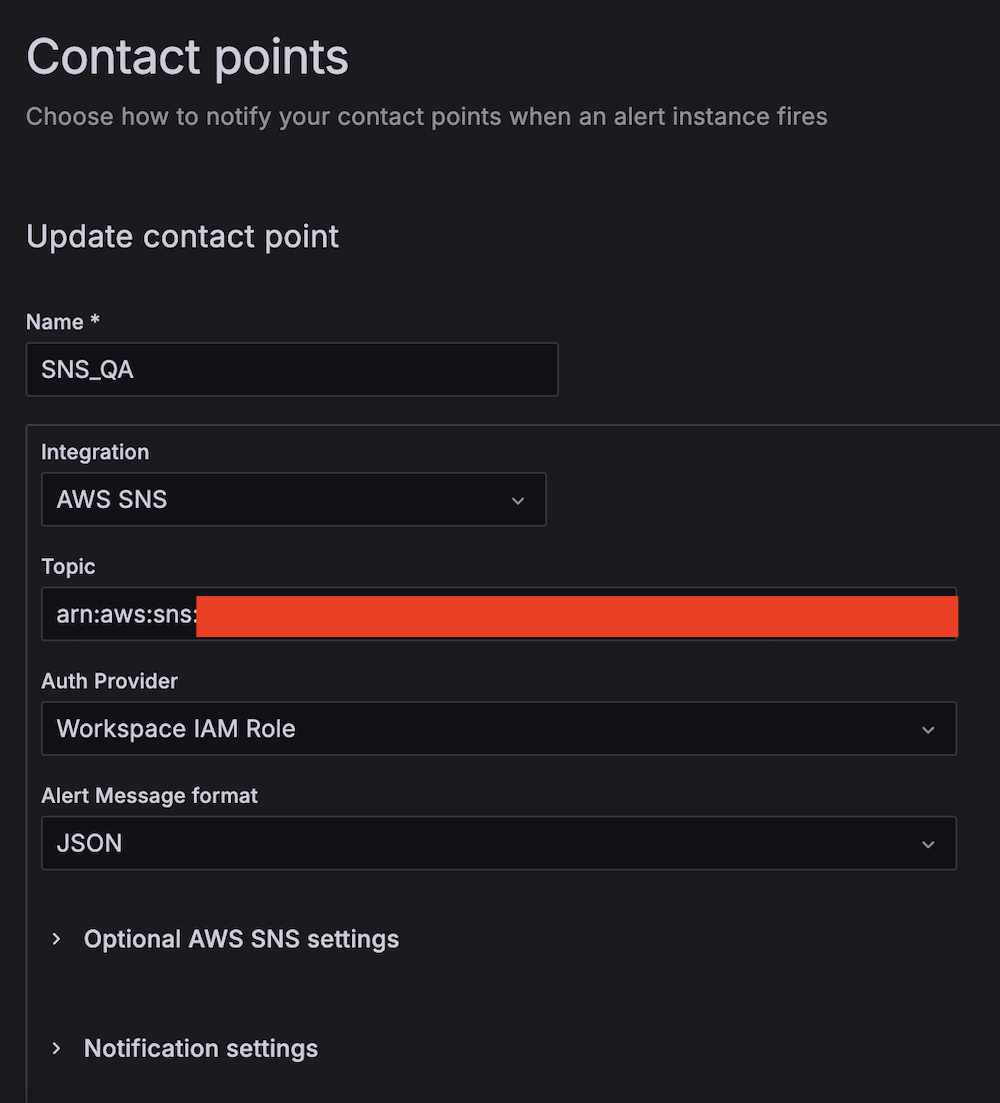
- For Identify, enter SNS_QA.
- For Integration, select AWS SNS.
- For Subject, enter the ARN for QALambdaFunctionTopic.
- For Auth Supplier, select Workspace IAM function.
- For Alert Message format, select JSON.
Create alert guidelines
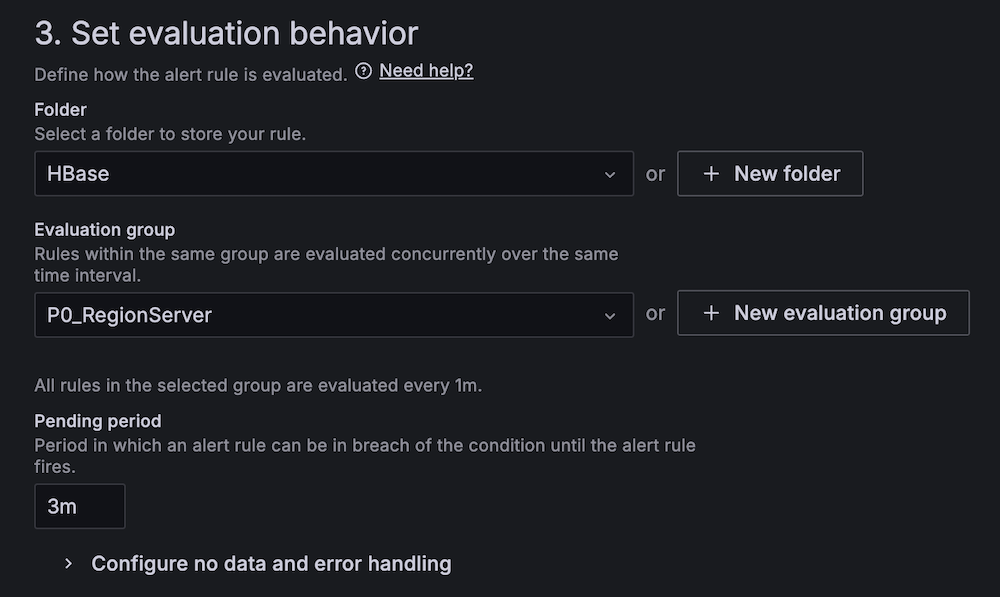
Full the next steps to arrange two vital alert guidelines:
- Select Alert guidelines below Alerting.
- Arrange alerting if the Apache HBase area server standing is irregular:
- For Alert title, enter HBase area server down.
- For Knowledge supply, select Amazon Managed Service for Prometheus.
- For Metric, select
hadoop_hbase_numregionservers.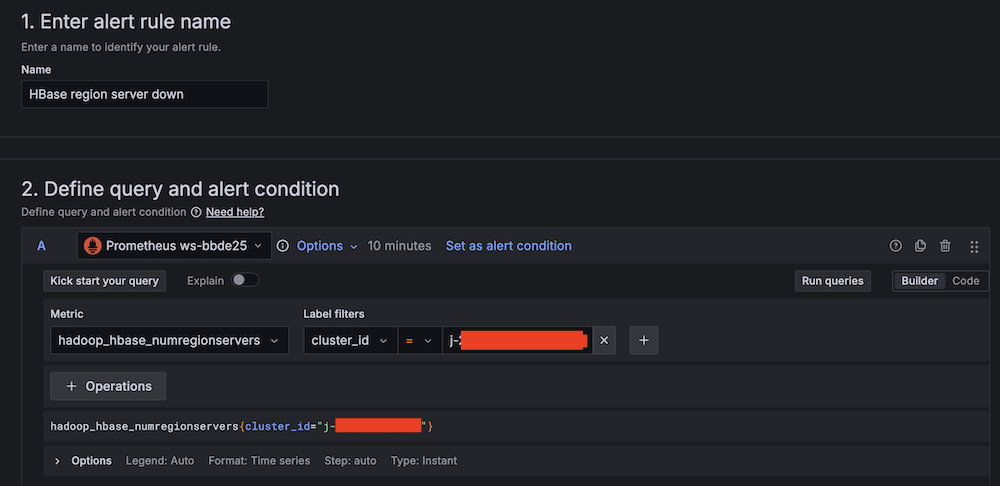
- For Threshold, configure to alert if the area server rely is lower than 2 for 3 minutes.
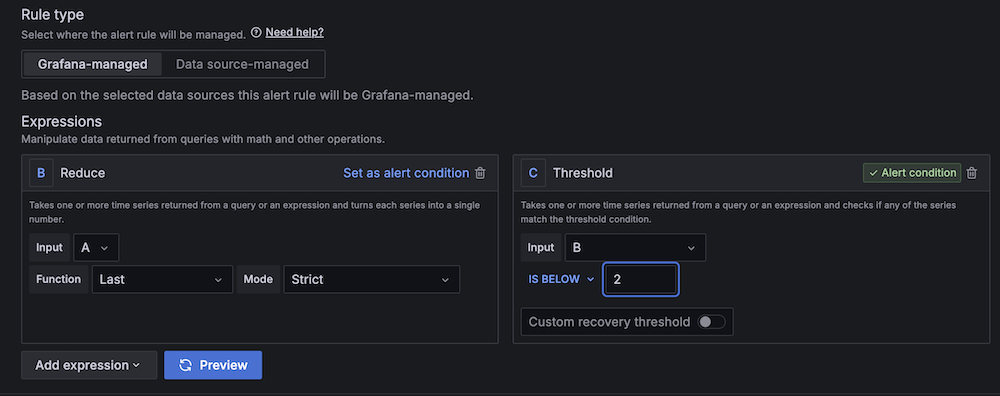
- For Analysis interval, set to 1 minute.
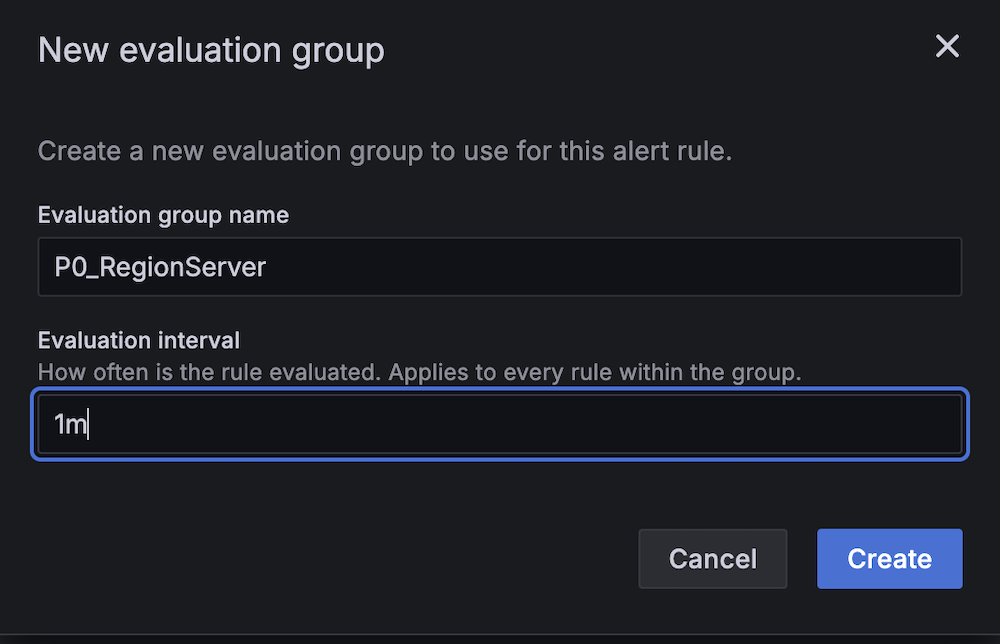
- For Contact level, select
SNS_SSM.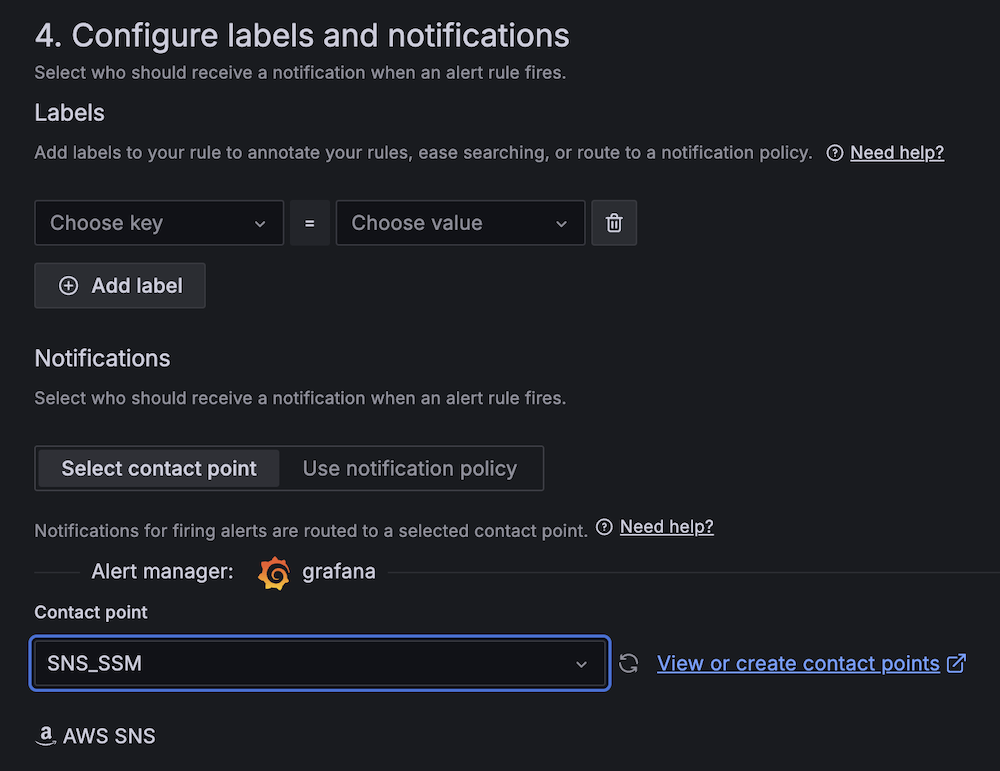
- Create a second alert for if Amazon EC2 CPU utilization is irregular:
- For Alert title, enter EC2 CPU utilization too excessive.
- For Knowledge supply, select Amazon CloudWatch.
- For Namespace, select AWS/EC2.
- For Metric title, select CPUUtilization
- For Statistic, select Most.
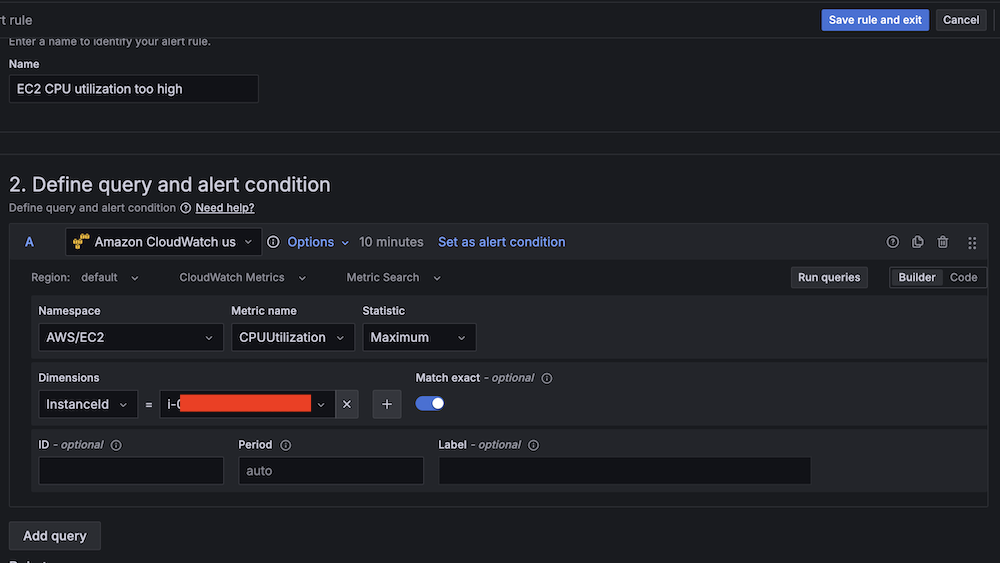
- For Threshold, configure to alert if CPU utilization is greater than 95% for 3 minutes.
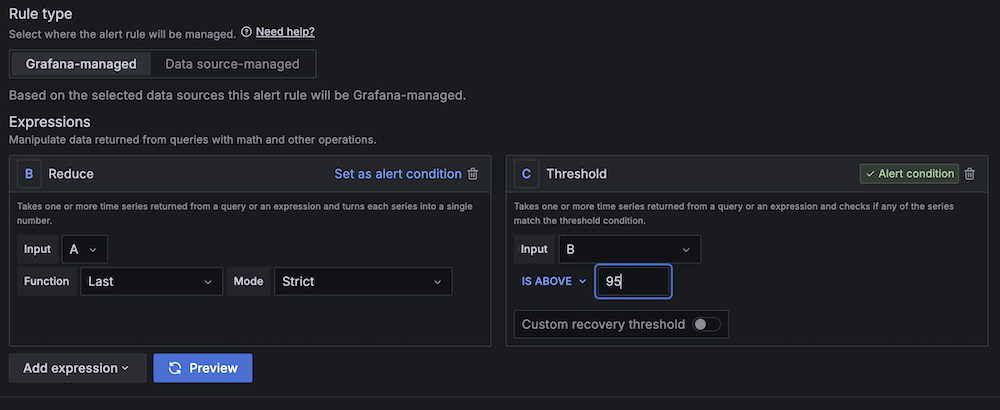
- For Analysis interval, configure to 1 minute.
- For Contact level, select
SNS_QA.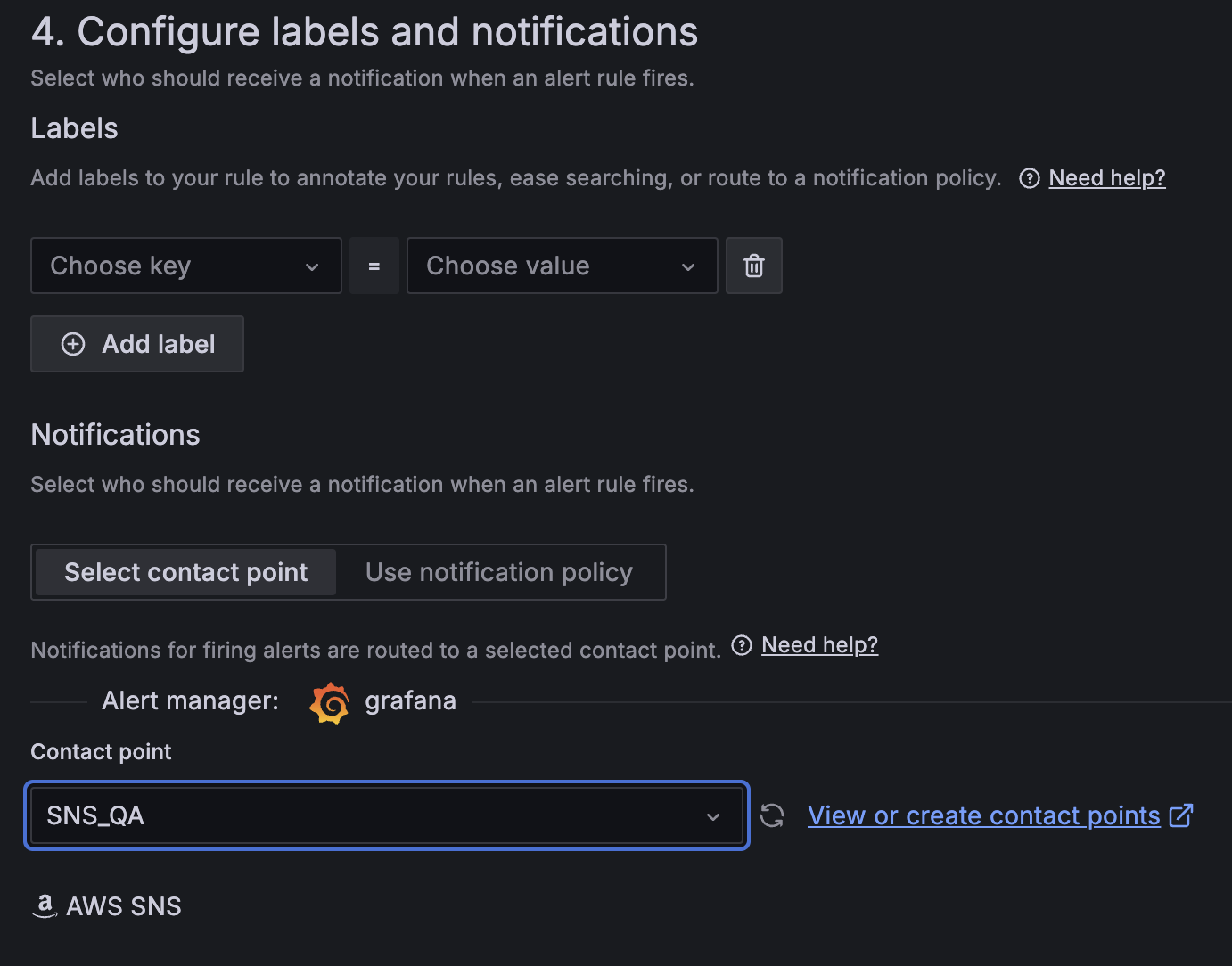
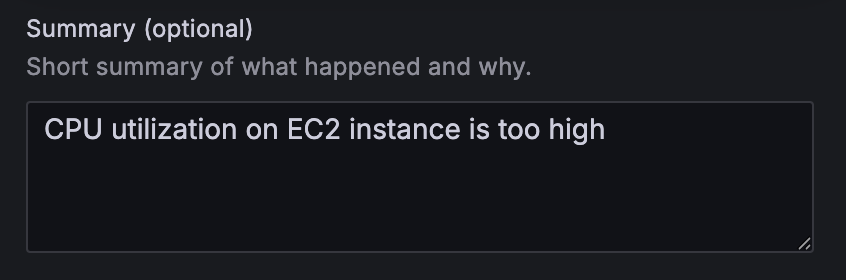
- On the alert rule creation web page, scroll to 5. Add annotations and for Abstract, add a transparent description of the alert, for instance, CPU utilization on EC2 occasion is simply too excessive.
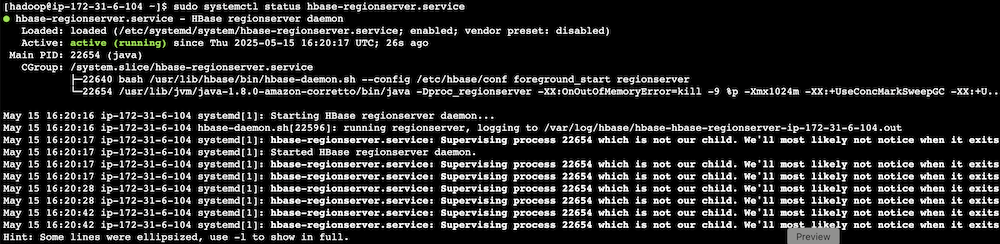
Apache HBase area server incident take a look at
To verify the system is working as anticipated, full the next Apache HBase area server incident take a look at:
- SSH into an EMR core occasion.
- Cease the Apache HBase area server utilizing systemctl:
- Confirm the service standing:
- Observe Amazon Managed Grafana alert development:
- Monitor alert standing modifications.


- Confirm SNS message era.
- Affirm SQS message queuing.
- Monitor the Lambda perform triggered for remediation.
- Monitor alert standing modifications.

CPU utilization stress take a look at
Full the next CPU utilization stress take a look at:
- SSH into the EMR major occasion.
- Set up stress testing instruments:
- Confirm the set up:
- Generate excessive CPU load utilizing the stress command and the next command construction:
For our Amazon EMR take a look at, use the next command:
-c 4 within the command creates 4 CPU-bound processes (one for every vCPU).The next are occasion kind vCPUs to your reference:
- m5.xlarge: 4 vCPUs
- m5.2xlarge: 8 vCPUs
- m5.4xlarge: 16 vCPUs
- Monitor system response:
- Observe Amazon Managed Grafana alert standing modifications.

- Confirm Amazon Bedrock advice era.
- Examine SNS e-mail notification supply.


- Observe Amazon Managed Grafana alert standing modifications.
Finest practices and concerns
Monitoring infrastructure requires exact alert prioritization and threshold configuration. Alert aggregation methods stop notification overload by consolidating occasion streams and decreasing redundant alerts. Operational groups should keep dashboards by way of constant updates and metric integration, offering real-time visibility into system efficiency and well being.
Safety implementations deal with least-privilege AWS Identification and Entry Administration (IAM) roles, limiting entry to vital assets and minimizing potential breach vectors. Knowledge safety methods contain encryption protocols for info at relaxation and in transit, utilizing AES-256 requirements. Automated safety audit processes scan automation scripts, figuring out potential vulnerabilities by way of code evaluation and runtime inspection.
Efficiency optimization in serverless architectures makes use of Lambda extensions to cache information base content material, decreasing latency and enhancing response instances. Retry mechanisms for API calls implement exponential backoff methods, mitigating transient community exceptions and enhancing system resilience. Execution time monitoring of Lambda capabilities allows detection of anomalies by way of statistical evaluation, offering insights into potential system-wide incidents or efficiency degradations.
Clear up
To keep away from incurring future costs, delete the assets by deleting the father or mother stack on the AWS CloudFormation console.
Conclusion
This resolution supplies a strong framework for automated EMR cluster monitoring and incident response. By combining real-time monitoring with AI-powered remediation ideas and automatic execution, organizations can considerably scale back MTTR for widespread Amazon EMR points whereas constructing a information base for future incident response.
Check out this resolution to your personal use case, and go away your suggestions within the feedback part.
Concerning the authors
 Yu-ting Su, Sr. Hadoop System Engineer, AWS Help Engineering. Yu-Ting is a Sr. Hadoop Programs Engineer at Amazon Net Providers (AWS). Her experience is in Amazon EMR and Amazon OpenSearch Service. She’s enthusiastic about distributing computation and serving to individuals to carry their concepts to life.
Yu-ting Su, Sr. Hadoop System Engineer, AWS Help Engineering. Yu-Ting is a Sr. Hadoop Programs Engineer at Amazon Net Providers (AWS). Her experience is in Amazon EMR and Amazon OpenSearch Service. She’s enthusiastic about distributing computation and serving to individuals to carry their concepts to life.

{kind=link}