

Robotic greedy is a cornerstone process for automation and manipulation, important in domains spanning from industrial choosing to service and humanoid robotics. Regardless of many years of analysis, reaching strong, general-purpose 6-degree-of-freedom (6-DOF) greedy stays a difficult open downside. Lately, NVIDIA unveiled GraspGen, a novel diffusion-based grasp technology framework that guarantees to deliver state-of-the-art (SOTA) efficiency with unprecedented flexibility, scalability, and real-world reliability.
The Greedy Problem and Motivation
Correct and dependable grasp technology in 3D area—the place grasp poses should be expressed when it comes to place and orientation—requires algorithms that may generalize throughout unknown objects, various gripper varieties, and difficult environmental situations together with partial observations and litter. Classical model-based grasp planners rely closely on exact object pose estimation or multi-view scans, making them impractical for in-the-wild settings. Information-driven studying approaches present promise, however present strategies are inclined to wrestle with generalization and scalability, particularly when shifting to new grippers or real-world cluttered environments.

One other limitation of many current greedy programs is their dependency on giant quantities of pricey real-world information assortment or domain-specific tuning. Accumulating and annotating actual grasp datasets is dear and doesn’t simply switch between gripper varieties or scene complexities.
Key Concept: Massive-Scale Simulation and Diffusion Mannequin Generative Greedy
NVIDIA’s GraspGen pivots away from costly real-world information assortment in the direction of leveraging large-scale artificial information technology in simulation—notably using the huge range of object meshes from the Objaverse dataset (over 8,000 objects) and simulated gripper interactions (over 53 million grasps generated).
GraspGen formulates grasp technology as a denoising diffusion probabilistic mannequin (DDPM) working on the SE(3) pose area (comprising 3D rotations and translations). Diffusion fashions, well-established in picture technology, iteratively refine random noise samples in the direction of lifelike grasp poses conditioned on an object-centric level cloud illustration. This generative modeling method naturally captures the multi-modal distribution of legitimate grasps on complicated objects, enabling spatial range important for dealing with litter and process constraints.
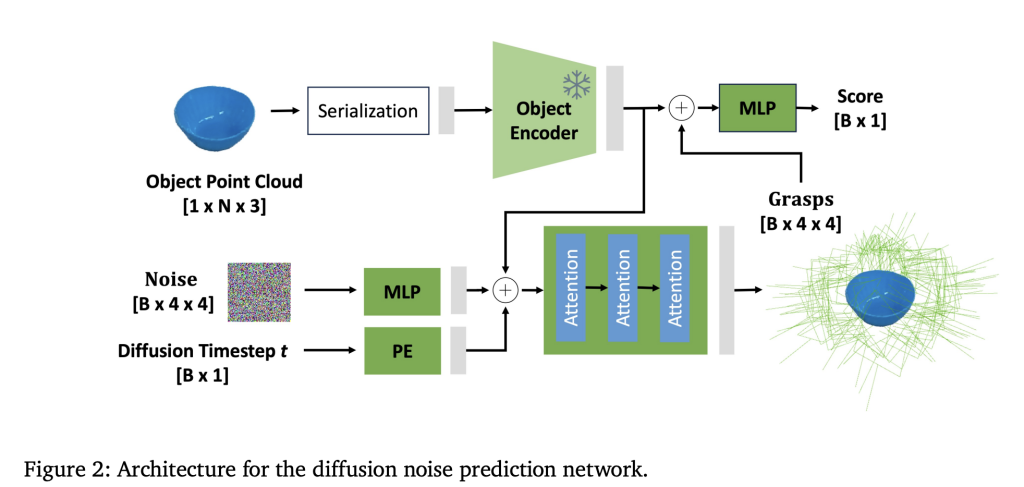
Architecting GraspGen: Diffusion Transformer and On-Generator Coaching
- Diffusion Transformer Encoder: GraspGen employs a novel structure combining a robust PointTransformerV3 (PTv3) spine to encode uncooked, unstructured 3D level cloud inputs into latent representations, adopted by iterative diffusion steps that predict noise residuals within the grasp pose area. This differs from prior works that depend on PointNet++ or contact-based grasp representations, delivering improved grasp high quality and computational effectivity.
- On-Generator Coaching of Discriminator: GraspGen innovates on the grasp scorer or discriminator coaching paradigm. As a substitute of coaching on static offline datasets of profitable/failed grasps, the discriminator learns on “on-generator” samples—grasp poses produced by the diffusion generative mannequin throughout coaching. These on-generator grasps expose the discriminator to typical errors or mannequin biases, akin to grasps barely in collision or outliers removed from object surfaces, enabling it to raised determine and filter false positives throughout inference.
- Environment friendly Weight Sharing: The discriminator reuses the frozen object encoder from the diffusion generator, requiring solely a light-weight multilayer perceptron (MLP) educated from scratch for grasp success classification. This results in a 21x discount in reminiscence consumption in comparison with prior discriminator architectures.
- Translation Normalization & Rotation Representations: To optimize community efficiency, the interpretation elements of grasps are normalized primarily based on dataset statistics, and rotations encoded by way of Lie algebra or 6D representations, making certain secure and correct pose prediction.
Multi-Embodiment Greedy and Environmental Flexibility
GraspGen is demonstrated throughout three gripper varieties:
- Parallel-jaw grippers (Franka Panda, Robotiq-2F-140)
- Suction grippers (modeled analytically)
- Multi-fingered grippers (deliberate future extensions)
Crucially, the framework generalizes to:
- Partial vs. Full Level Clouds: It performs robustly on each single viewpoint observations with occlusions in addition to fused multi-view level clouds.
- Single Objects and Cluttered Scenes: Analysis on FetchBench, a difficult cluttered greedy benchmark, confirmed GraspGen reaching prime process and grasp success charges.
- Sim-to-Actual Switch: Skilled purely in simulation, GraspGen exhibited sturdy zero-shot switch to actual robotic platforms underneath noisy visible inputs, aided by augmentations simulating segmentation and sensor noise.
Benchmarking and Efficiency
- FetchBench Benchmark: In simulation evaluations overlaying 100 various cluttered scenes and over 6,000 grasp makes an attempt, GraspGen outperformed state-of-the-art baselines like Contact-GraspNet and M2T2 by huge margins (process success enchancment of almost 17% over Contact-GraspNet). Even an oracle planner with ground-truth grasp poses struggled to push process success past 49%, highlighting the problem.
- Precision-Protection Beneficial properties: On normal benchmarks (ACRONYM dataset), GraspGen considerably improved grasp success precision and spatial protection in comparison with prior diffusion and contact-point fashions, demonstrating greater range and high quality of grasp proposals.
- Actual Robotic Experiments: Utilizing a UR10 robotic with RealSense depth sensing, GraspGen achieved 81.3% total grasp success in numerous real-world settings (together with litter, baskets, cabinets), exceeding M2T2 by 28%. It generated centered grasp poses solely on course objects, avoiding spurious grasps seen in scene-centric fashions.

Dataset Launch and Open Supply
NVIDIA launched the GraspGen dataset publicly to foster group progress. It consists of roughly 53 million simulated grasps throughout 8,515 object meshes licensed underneath permissive Inventive Commons insurance policies. The dataset was generated utilizing NVIDIA Isaac Sim with detailed physics-based grasp success labeling, together with shaking exams for stability.
Alongside the dataset, the GraspGen codebase and pretrained fashions can be found underneath open-source licenses at https://github.com/NVlabs/GraspGen, with extra venture materials at https://graspgen.github.io/.
Conclusion
GraspGen represents a significant advance in 6-DOF robotic greedy, introducing a diffusion-based generative framework that outperforms prior strategies whereas scaling throughout a number of grippers, scene complexities, and observability situations. Its novel on-generator coaching recipe for grasp scoring decisively improves filtering of mannequin errors, resulting in dramatic features in grasp success and task-level efficiency each in simulation and on actual robots.
By publicly releasing each code and an enormous artificial grasp dataset, NVIDIA empowers the robotics group to additional develop and apply these improvements. The GraspGen framework consolidates simulation, studying, and modular robotics elements right into a turnkey answer, advancing the imaginative and prescient of dependable, real-world robotic greedy as a broadly relevant foundational constructing block in general-purpose robotic manipulation.
Try the Paper, Mission and GitHub Web page. All credit score for this analysis goes to the researchers of this venture. SUBSCRIBE NOW to our AI E-newsletter

Michal Sutter is an information science skilled with a Grasp of Science in Information Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and information engineering, Michal excels at remodeling complicated datasets into actionable insights.

{kind=link}