
Massive Language Fashions (LLMs) have revolutionized many areas of pure language processing, however they nonetheless face vital limitations when coping with up-to-date information, domain-specific info, or complicated multi-hop reasoning. Retrieval-Augmented Technology (RAG) approaches purpose to deal with these gaps by permitting language fashions to retrieve and combine info from exterior sources. Nonetheless, most current graph-based RAG methods are optimized for static corpora and wrestle with effectivity, accuracy, and scalability when the information is regularly rising—reminiscent of in information feeds, analysis repositories, or user-generated on-line content material.
Introducing EraRAG: Environment friendly Updates for Evolving Information
Recognizing these challenges, researchers from Huawei, The Hong Kong College of Science and Expertise, and WeBank have developed EraRAG, a novel retrieval-augmented technology framework purpose-built for dynamic, ever-expanding corpora. Reasonably than rebuilding your complete retrieval construction every time new knowledge arrives, EraRAG depends on localized, selective updates that contact solely these elements of the retrieval graph affected by the adjustments.
Core Options:
- Hyperplane-Based mostly Locality-Delicate Hashing (LSH):
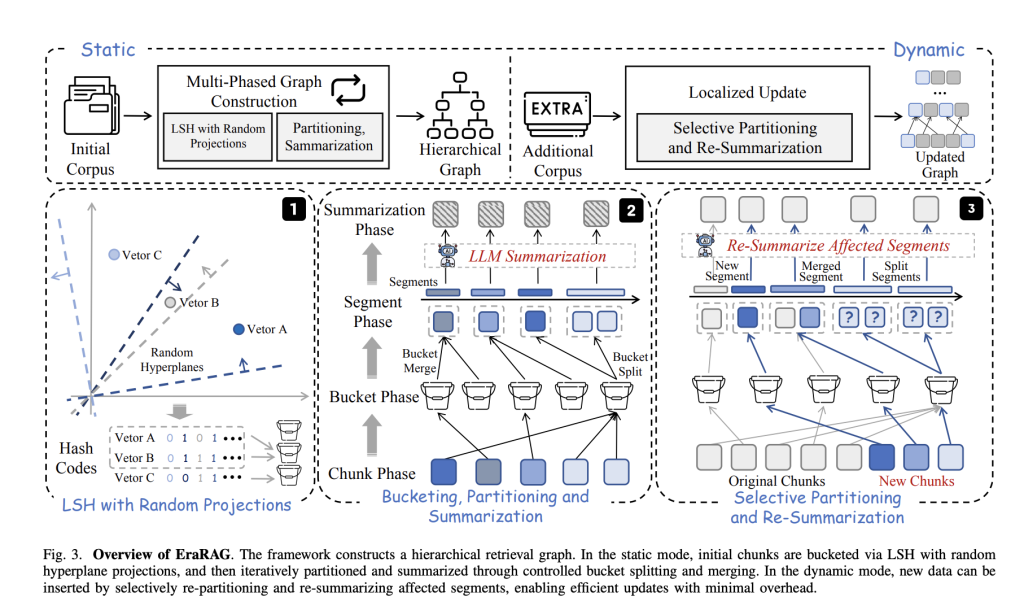
Each corpus is chunked into small textual content passages that are embedded as vectors. EraRAG then makes use of randomly sampled hyperplanes to mission these vectors into binary hash codes—a course of that teams semantically related chunks into the identical “bucket.” This LSH-based strategy maintains each semantic coherence and environment friendly grouping. - Hierarchical, Multi-Layered Graph Development:
The core retrieval construction in EraRAG is a multi-layered graph. At every layer, segments (or buckets) of comparable textual content are summarized utilizing a language mannequin. Segments which are too giant are cut up, whereas these too small are merged—guaranteeing each semantic consistency and balanced granularity. Summarized representations at greater layers allow environment friendly retrieval for each fine-grained and summary queries. - Incremental, Localized Updates:
When new knowledge arrives, its embedding is hashed utilizing the unique hyperplanes—guaranteeing consistency with the preliminary graph development. Solely the buckets/segments instantly impacted by new entries are up to date, merged, cut up, or re-summarized, whereas the remainder of the graph stays untouched. The replace propagates up the graph hierarchy, however all the time stays localized to the affected area, saving important computation and token prices. - Reproducibility and Determinism:
In contrast to normal LSH clustering, EraRAG preserves the set of hyperplanes used throughout preliminary hashing. This makes bucket project deterministic and reproducible, which is essential for constant, environment friendly updates over time.
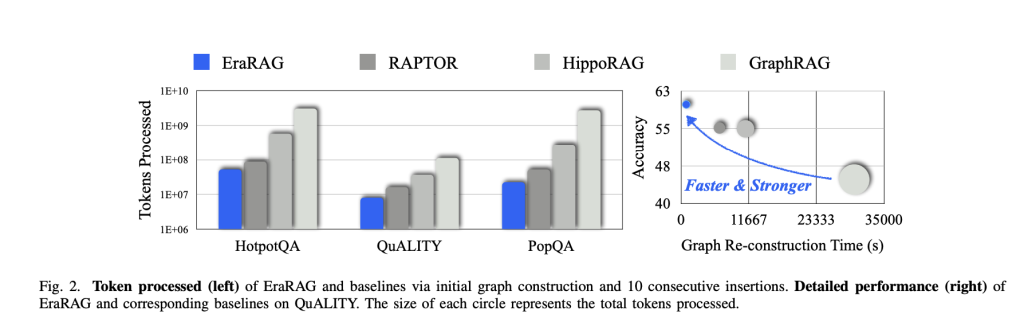
Efficiency and Influence
Complete experiments on a wide range of query answering benchmarks display that EraRAG:
- Reduces Replace Prices: Achieves as much as 95% discount in graph reconstruction time and token utilization in comparison with main graph-based RAG strategies (e.g., GraphRAG, RAPTOR, HippoRAG).
- Maintains Excessive Accuracy: EraRAG constantly outperforms different retrieval architectures in each accuracy and recall—throughout static, rising, and summary query answering duties—with minimal compromise in retrieval high quality or multi-hop reasoning capabilities.
- Helps Versatile Question Wants: The multi-layered graph design permits EraRAG to effectively retrieve fine-grained factual particulars or high-level semantic summaries, tailoring its retrieval sample to the character of every question.
Sensible Implications
EraRAG provides a scalable and sturdy retrieval framework superb for real-world settings the place knowledge is constantly added—reminiscent of dwell information, scholarly archives, or user-driven platforms. It strikes a steadiness between retrieval effectivity and flexibility, making LLM-backed functions extra factual, responsive, and reliable in fast-changing environments.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission | Meet the AI Dev Publication learn by 40k+ Devs and Researchers from NVIDIA, OpenAI, DeepMind, Meta, Microsoft, JP Morgan Chase, Amgen, Aflac, Wells Fargo and 100s extra [SUBSCRIBE NOW]
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.

{kind=link}