
Information is a strong software that can be utilized to enhance many elements of our lives, together with our well being. With the proliferation of wearable health trackers, well being apps, and different monitoring units, it has change into simpler than ever to gather and analyze knowledge about our well being. By monitoring and analyzing this knowledge, we will acquire useful insights into our well being and wellness, enabling us to make extra knowledgeable choices about our existence and habits.
Well being units, which allow you to trace all of your well being metrics in a single place, make it simple to watch your progress and make knowledgeable choices about your well being. This weblog exhibits how you should utilize your system and its knowledge to offer much more actionable insights. The instance I am going to stroll by means of makes use of Apple Healthkit to carry out superior analytics and machine studying, and construct a dashboard with related KPIs and metrics. The objective is assist monitor my weekly and month-to-month efficiency throughout these metrics so I can monitor and obtain my well being targets. Impressed by the weblog put up “You Are What You Measure,” my intent is to measure my option to good well being! You may be a part of within the enjoyable too (Github repo right here).
The Basis of Our Information-driven Health Journey
With the explosion of knowledge volumes at our fingertips and the myriad of instruments to accumulate, rework analyze and visualize – it’s simple to be overwhelmed. The lakehouse structure simplifies knowledge use circumstances by offering all the obligatory capabilities out there underneath one platform. Along with unifying workflows and knowledge groups, the Databricks Lakehouse Platform – powered by Delta Lake –makes knowledge warehouse-level options (like ACID transactions, governance, and efficiency) out there on knowledge lake scale, flexibility, and value.
To energy our dashboard and analytics, we’ll be leveraging Apple HealthKit, which along with nice monitoring, offers knowledge sharing capabilities from third-party apps within the iOS ecosystem. However to take it a step additional, we’ll even be utilizing full extent of the lakehouse! It makes use of a mix of Apache Spark, Databricks SQL, and MLflow to extract additional insights, aggregations, and KPI monitoring to maintain me sincere all through 2023. We’ll stroll by means of methods to make the most of Delta Reside Tables to orchestrate streaming ETL course of, use a metadata pushed ETL framework for knowledge transformation, and expose a dashboard with related KPIs to make data-driven actions!
Within the subsequent sections of this blogpost, we’ll present methods to:
- Export your well being knowledge
- Make the most of Delta Reside Tables to orchestrate streaming ETL
- Use a metadata-driven ETL framework to categorise and carry out transformations of our knowledge
- Expose a dashboard with related KPIs
- Make data-driven actions!
Preparation
Step one is to make the info out there. There are a number of choices to export Apple Healthkit knowledge, together with constructing your personal integration with the accompanying APIs or third-party apps. The strategy we’ll take is documented on the official HealthKit web site by exporting immediately from the app. Observe these easy directions under to export your knowledge:
- Guarantee you will have related knowledge in Well being Utility (resembling steps and heartrate)
- Export well being knowledge and add to your cloud storage of selection (I take advantage of Google Drive)
- Confirm that export.zip file is out there in Google Drive
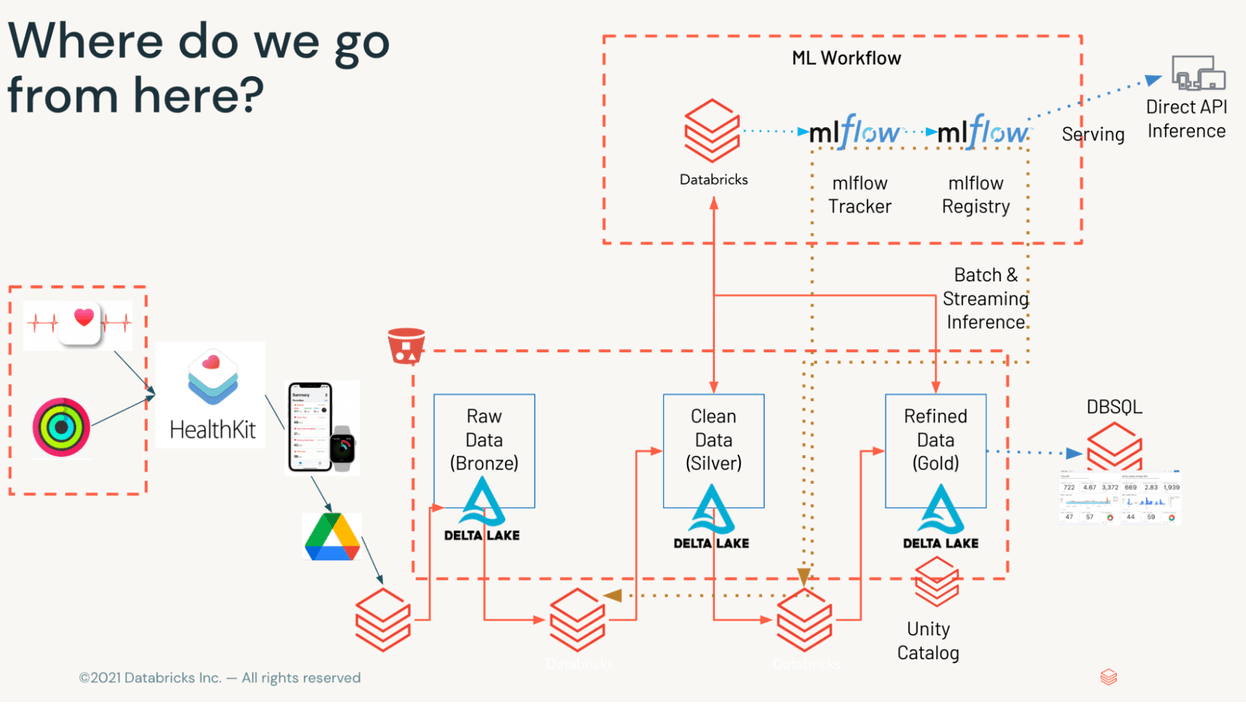
Excessive-Stage Structure
As proven in Determine 1, our knowledge will make a number of stops alongside the best way to visualization. As soon as knowledge is out there on object storage, we’ll course of it by means of the Medallion framework – taking uncooked XML (bronze), breaking out disparate datasets (silver), and aggregating related KPIs on minute, hourly, and each day foundation to current to the serving tier (gold).
Information Verification and Sharing
To make sure knowledge is out there, log into your goal Google Drive account (or wherever your export was uploaded to) and discover the filename export.zip. As soon as positioned, please guarantee file permissions replicate “anybody with the hyperlink,” and duplicate the hyperlink for later use.
Information Acquisition and Preparation
Now that our knowledge is out there, it is time to arrange our pocket book for knowledge entry, governance, and ingestion into Databricks. Step one is to put in and import obligatory libraries and setup variables we’ll be reusing to automate extractions and transformations in later steps.
For knowledge acquisition, we’ll be utilizing gDown, a neat little library that makes downloading information from Google Drive easy and environment friendly. At this level, all you need to do is copy your shared hyperlink from Google Drive, a vacation spot folder, and develop .zip archive to the /tmp listing.
When exploring the contents of export.zip, there are a number of attention-grabbing datasets out there. These knowledge embrace exercise routes (in .gpx format), electrocardiograms (in .csv), and HealthKit data (in .xml). For our functions we’re concentrating on export.xml, which tracks most of our well being metrics in Apple HealthKit. Please word, if export.xml accommodates hundreds of thousands of data (like mine does), chances are you’ll want to extend the scale of the Apache Spark driver for processing. Please confer with GitHub for reference.
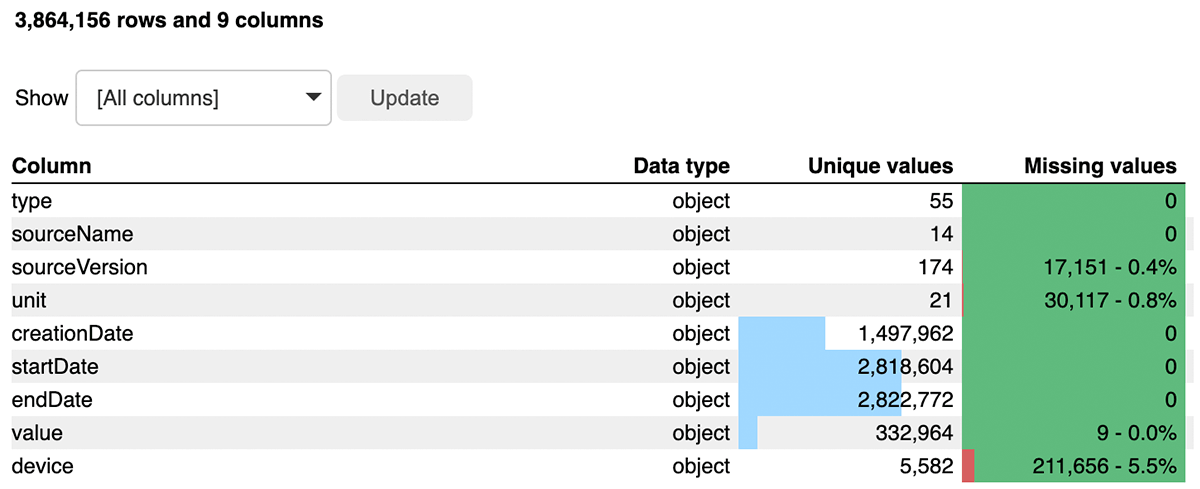
Earlier than continuing, we’ll do a fast overview of the dataframe utilizing Bamboolib, which offers a lowcode/no-code strategy to exploring the info and making use of transformations, altering datatypes, or performing aggregations with minimal code. This can give us nice insights into our knowledge and alert us to any attainable knowledge high quality issues. Take a look at EDA pocket book
As seen in Determine 3, the export.xml consists of greater than 3.8M data throughout 55 kinds of knowledge. By means of this exploration, we see it is a comparatively clear dataset, with minimal null values within the worth column, which is vital as a result of it shops metrics primarily based on the column kind. The kind column consists of various out there metrics – from sleep monitoring to heartbeats per minute.

Now that we perceive the info form and relationships, we will transfer on to the enjoyable stuff!
Go for the GOLD – Medallion framework!
Upon additional inspection, the xml – just isn’t so easy in any case. As offered by our Bamboolib evaluation, though contained in a single XML, it’s truly 55 totally different metrics which might be tracked. Enter Lakehouse! We are going to apply the ETL Medallion framework on the lakehouse to curate our knowledge lake and course of our knowledge for downstream consumption by knowledge science and BI groups – all on low cost object storage!
Processing and touchdown this knowledge into the Delta format permits us to maintain uncooked knowledge and begin reaping the advantages.
As a part of the ELT course of, we’ll be profiting from Delta Reside Tables (DLT) to automate and simplify our knowledge processing. DLT offers the benefit of a declarative framework to automate features, which might be in any other case manually developed by engineering groups, together with streaming pipeline duties resembling checkpointing and auto-scaling with enhanced autoscaling, knowledge validation duties with expectations, and pipeline observability metrics.
Information Exploration and Manipulation
We’ll base our subsequent evaluation on the ‘kind’ column, which defines the info within the payload. For instance, HeartRate kind may have totally different metrics tracked when in comparison with ActiveEnergyBurned kind. As seen under – our xml file truly accommodates 55+ metrics (at the least in my case – YMMV) tracked by Apple healthKit.
Every of those sources represents an distinctive metric being tracked by Apple HealthKit – concerning totally different elements of total well being. For instance, it is going to pull metrics from environmental decibel ranges and lat/lon of exercises, to coronary heart charge and energy burned. Along with distinctive measurements, they supply totally different timescales – from per exercise, per day, to per second measurements – a wealthy dataset certainly!
Clear up!
We need to guarantee we monitor any knowledge high quality issues all through the pipeline. From our earlier investigation, it appeared that some values may need been measured incorrectly – which could skew our knowledge (coronary heart charge above 200??). Fortunately, DLT makes knowledge high quality points manageable utilizing expectations and pipeline metrics. A DLT expectation is a selected situation you anticipate of the occasion (for instance IS NOT NULL OR x>5), which DLT will take an motion on. These actions might be only for monitoring functions (“dlt.anticipate”) or might embrace dropping the occasion (‘dlt.expect_or_drop’) or failing the desk/pipeline (‘dlt.expect_or_fail’). For extra info on DLT and Expectations, please confer with the next web page (hyperlink).
Metadata FTW!
As talked about above, every kind will present distinctive insights into your total well being. With over 55 differing types and metrics, it may be a frightening activity to handle. Particularly when new metrics and our knowledge sources pop into the pipeline. Because of this, we’ll leverage a metadata-driven framework to simplify and modularize our pipeline.
For our subsequent step, we ship over 10 distinctive sources to particular person silver tables with particular columns and obligatory transformations to make the info ML and BI-ready. We use the metadata-driven framework, which simplifies and quickens improvement throughout totally different knowledge sources, to pick out particular values from our bronze desk and rework into particular person silver tables. These transforms can be primarily based on the kind column in our bronze desk. On this instance, we’ll be extracting a subset of knowledge sources, however the metadata desk is definitely prolonged to incorporate extra metrics/tables as new knowledge sources come up. The metadata desk is represented under and accommodates columns that drive our DLT framework, together with source_name, table_name, columns, expectations, and feedback.

We incorporate our metadata desk into our DLT pipeline by leveraging looping capabilities out there within the python API. Mixing capabilities between SQL and Python makes DLT an especially highly effective framework for improvement and transformation. We’ll learn within the Delta desk (however might be something Spark can learn right into a dataframe; see instance metadata.json in repo) and loop through to extract metadata variables for our silver tables utilizing the table_iterator operate.

This easy snippet of code, accompanied by a metadata desk, will learn in knowledge from bronze, and supply extractions and distinctive columns to over 10 downstream silver tables. This course of is additional outlined within the “DLT_bronze2silver” pocket book which accommodates knowledge ingestion (autoloader) and metadata-driven transformations for silver tables. Beneath is an instance of the DLT DAG created primarily based on the totally different sources out there in Apple HealthKit.

And clear datasets!

Lastly, we mix a number of attention-grabbing datasets – on this case, coronary heart charge and exercise info. We then create ancillary metrics (like HeartRate Zones) and carry out by-minute and day aggregations to make downstream analytics extra performant and applicable for consumption. That is additional outlined within the ‘DLT_AppleHealth_iterator_Gold’ pocket book within the repo.
With our knowledge out there and cleaned up, we’re capable of construct out some dashboards to assist us monitor and visualize our journey. On this case, I constructed a easy dashboard utilizing capabilities included in Databricks SQL to trace KPIs that can assist me obtain my targets, together with exercise time, coronary heart charge variability, exercise efforts, total averages, and brief and long-term developments. In fact, if you’re more adept in different knowledge visualization instruments (like Energy BI or Tableau), Databricks might be absolutely built-in into your present workflow.
Beneath is a straightforward dashboard with related metrics, cut up by 7 day and 30 day averages. I like getting a view throughout KPIs and time all in a single dashboard. This can assist information my exercise program to make sure I constantly enhance!

With such a wealthy dataset, it’s also possible to begin delving into ML and analyze all measures of well being. Since I am not a knowledge scientist, I leveraged the built-in functionality of autoML to forecast my weight reduction primarily based on some gold and silver tables! AutoML offers a simple and intuitive option to practice fashions, automate hyperparameters tuning, and combine with MLflow for experiment monitoring and Serving of mannequin!

Abstract
Hopefully this experiment offered a consumable introduction to Databricks and a number of the nice function performance out there on the platform.
Now it is your flip to leverage the ability of knowledge to alter habits in a optimistic approach! Get began with your personal experiment.

{kind=link}