
With AWS Glue, organizations can uncover, put together, and mix information for analytics, machine studying (ML), AI, and utility improvement. At its core, AWS Glue for Apache Spark jobs function by specifying your code and the variety of Information Processing Models (DPUs) wanted, with every DPU offering computing sources to energy your information integration duties. Nonetheless, though the prevailing employees successfully serve most information integration wants, as we speak’s information landscapes have gotten more and more complicated at bigger scale. Organizations are coping with bigger information volumes, extra numerous information sources, and more and more refined transformation necessities.
Though horizontal scaling (including extra employees) successfully addresses many information processing challenges, sure workloads profit considerably from vertical scaling (growing the capability of particular person employees). These eventualities embrace processing massive, complicated question plans, dealing with memory-intensive operations, or managing workloads that require substantial per-worker sources for operations reminiscent of massive be part of operations, complicated aggregations, and information skew eventualities. The flexibility to scale each horizontally and vertically gives the flexibleness wanted to optimize efficiency throughout numerous information processing necessities.
Responding to those rising calls for, as we speak we’re happy to announce the final availability of AWS Glue R sort, G.12X, and G.16X employees, the brand new AWS Glue employee varieties for essentially the most demanding information integration workloads. G.12X and G.16X employees provide elevated compute, reminiscence, and storage, making it attainable so that you can vertically scale and run much more intensive information integration jobs. R sort employees provide elevated reminiscence to fulfill much more memory-intensive necessities. Bigger employee varieties not solely profit the Spark executors, but additionally in circumstances the place the Spark driver wants bigger capability—as an illustration, as a result of the job question plan is massive. To be taught extra about Spark driver and executors, see Key subjects in Apache Spark.
This submit demonstrates how AWS Glue R sort, G.12X, and G.16X employees assist you to scale up your AWS Glue for Apache Spark jobs.
R sort employees
AWS Glue R sort employees are designed for memory-intensive workloads the place you want extra reminiscence per employee than G employee varieties. G employee varieties run with a 1:4 vCPU to reminiscence (GB) ratio, whereas R employee varieties run with a 1:8 vCPU to reminiscence (GB) ratio. R.1X employees present 1 DPU, with 4 vCPU, 32 GB reminiscence, and 94 GB of disk per node. R.2X employees present 2 DPU, with 8 vCPU, 64 GB reminiscence, and 128 GB of disk per node. R.4X employees present 4 DPU, with 16 vCPU, 128 GB reminiscence, and 256 GB of disk per node. R.8X employees present 8 DPU, with 32 vCPU, 256 GB reminiscence, and 512 GB of disk per node. As with G employee varieties, you possibly can select R sort employees with a single parameter change within the API, AWS Command Line Interface (AWS CLI), or AWS Glue Studio. Whatever the employee used, the AWS Glue jobs have the identical capabilities, together with automated scaling and interactive job authoring utilizing notebooks. R sort employees can be found with AWS Glue 4.0 and 5.0.
The next desk reveals compute, reminiscence, disk, and Spark configurations for every R employee sort.
| AWS Glue Employee Kind | DPU per Node | vCPU | Reminiscence (GB) | Disk (GB) | Approximate Free Disk House (GB) | Variety of Spark Executors per Node | Variety of Cores per Spark Executor |
| R.1X | 1 | 4 | 32 | 94 | 44 | 1 | 4 |
| R.2X | 2 | 8 | 64 | 128 | 78 | 1 | 8 |
| R.4X | 4 | 16 | 128 | 256 | 230 | 1 | 16 |
| R.8X | 8 | 32 | 256 | 512 | 485 | 1 | 32 |
To make use of R sort employees on an AWS Glue job, change the setting of the employee sort parameter. In AWS Glue Studio, you possibly can select R 1X, R 2X, R 4X, or R 8X underneath Employee sort.
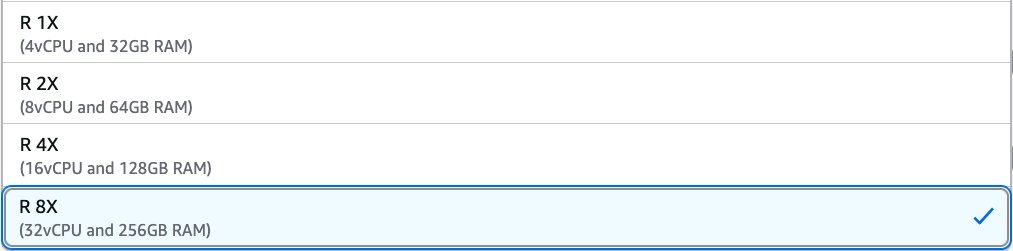
Within the AWS API or AWS SDK, you possibly can specify R employee varieties within the WorkerType parameter. Within the AWS CLI, you should utilize the --worker-type parameter in a create-job command.
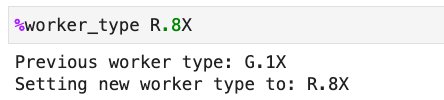
To make use of R employee varieties on an AWS Glue Studio pocket book or interactive classes, set R.1X, R.2X, R.4X, or R.8X within the %worker_type magic:
R sort employees are priced at $0.52 per DPU-hour for every job, billed per second with a 1-minute minimal.
G.12X and G.16X employees
AWS Glue G.12X and G.16X employees provide you with extra compute, reminiscence, and storage to run your most demanding jobs. G.12X employees present 12 DPU, with 48 vCPU, 192 GB reminiscence, and 768 GB of disk per employee node. G.16X employees present 16 DPU, with 64 vCPU, 256 GB reminiscence, and 1024 GB of disk per node. G.16x is double the sources of the prevailing largest employee sort G.8X. You possibly can allow G.12X and G.16X employees with a single parameter change within the API, AWS CLI, or AWS Glue Studio. Whatever the employee used, the AWS Glue jobs have the identical capabilities, together with automated scaling and interactive job authoring utilizing notebooks. G.12X and G.16X employees can be found with AWS Glue 4.0 and 5.0.The next desk reveals compute, reminiscence, disk, and Spark configurations for every G employee sort.
| AWS Glue Employee Kind | DPU per Node | vCPU | Reminiscence (GB) | Disk (GB) | Approximate Free Disk House (GB) | Variety of Spark Executors per Node | Variety of Cores per Spark Executor |
| G.025X | 0.25 | 2 | 4 | 84 | 34 | 1 | 2 |
| G.1X | 1 | 4 | 16 | 94 | 44 | 1 | 4 |
| G.2X | 2 | 8 | 32 | 138 | 78 | 1 | 8 |
| G.4X | 4 | 16 | 64 | 256 | 230 | 1 | 16 |
| G.8X | 8 | 32 | 128 | 512 | 485 | 1 | 32 |
| G.12X (new) | 12 | 48 | 192 | 768 | 741 | 1 | 48 |
| G.16X (new) | 16 | 64 | 256 | 1024 | 996 | 1 | 64 |
To make use of G.12X and G.16X employees on an AWS Glue job, change the setting of the employee sort parameter to G.12X or G.16X. In AWS Glue Studio, you possibly can select G 12X or G 16X underneath Employee sort.
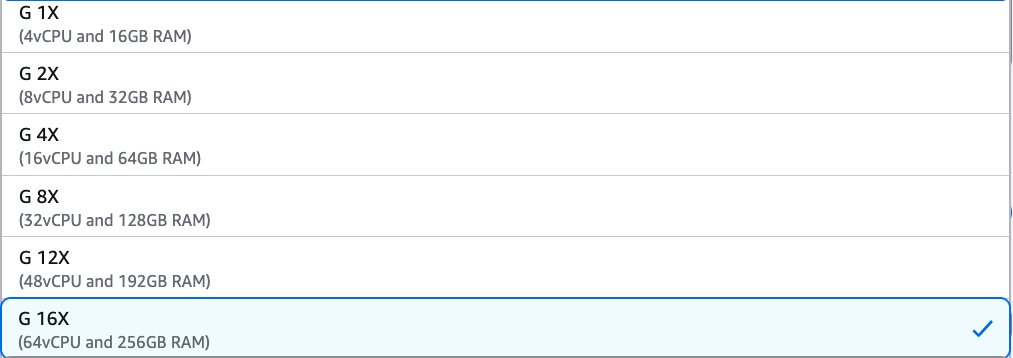
Within the AWS API or AWS SDK, you possibly can specify G.12X or G.16X within the WorkerType parameter. Within the AWS CLI, you should utilize the --worker-type parameter in a create-job command.
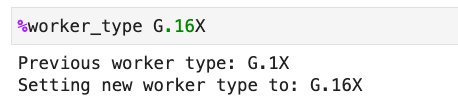
To make use of G.12X and G.16X on an AWS Glue Studio pocket book or interactive classes, set G.12X or G.16X within the %worker_type magic:
G sort employees are priced at $0.44 per DPU-hour for every job, billed per second with a 1-minute minimal. This is identical pricing as the prevailing employee varieties.
Select the fitting employee sort on your workload
To optimize job useful resource utilization, run your anticipated utility workload to determine the perfect employee sort that aligns together with your utility’s necessities. Begin with basic employee varieties like G.1X or G.2X, and monitor your job run from AWS Glue job metrics, observability metrics, and Spark UI. For extra particulars about find out how to monitor the useful resource metrics for AWS Glue jobs, see Finest practices for efficiency tuning AWS Glue for Apache Spark jobs.
When your information processing workload is effectively distributed throughout employees, G.1X or G.2X work very effectively. Nonetheless, some workloads would possibly require extra sources per employee. You need to use the brand new G.12X, G.16X, and R sort employees to handle them. On this part, we focus on typical use circumstances the place vertical scaling is efficient.
Giant be part of operations
Some joins would possibly contain massive tables the place one or either side have to be broadcast. Multi-way joins require a number of massive datasets to be held in reminiscence. With skewed joins, sure partition keys have disproportionately massive information volumes. Horizontal scaling doesn’t assist when the complete dataset must be in reminiscence on every node for broadcast joins.
Excessive-cardinality group by operations
This use case consists of aggregations on columns with many distinctive values, operations requiring upkeep of enormous hash tables for grouping, and distinct counts on columns with excessive uniqueness. Excessive-cardinality operations typically end in massive hash tables that have to be maintained in reminiscence on every node. Including extra nodes doesn’t scale back the scale of those per-node information buildings.
Window features and sophisticated aggregations
Some operations would possibly require a big window body, or contain computing percentiles, medians, or different rank-based analytics throughout massive datasets, along with complicated grouping units or CUBE operations on high-cardinality columns. These operations typically require retaining massive parts of knowledge in reminiscence per partition. Including extra nodes doesn’t scale back the reminiscence requirement for every particular person window or grouping operation.
Complicated question plans
Complicated question plans can have many levels and deep dependency chains, operations requiring massive shuffle buffers, or a number of transformations that want to take care of massive intermediate outcomes. These question plans typically contain massive quantities of intermediate information that have to be held in reminiscence. Extra nodes don’t essentially simplify the plan or scale back per-node reminiscence necessities.
Machine studying and sophisticated analytics
With ML and analytics use circumstances, mannequin coaching would possibly contain massive characteristic units, extensive transformations requiring substantial intermediate information, or complicated statistical computations requiring whole datasets in reminiscence. Many ML algorithms and sophisticated analytics require the complete dataset or massive parts of it to be processed collectively, which may’t be successfully distributed throughout extra nodes.
Information skew eventualities
In some information skew eventualities, you may need to course of closely skewed information the place sure partitions are considerably bigger, or carry out operations on datasets with high-cardinality keys, resulting in uneven partition sizes. Horizontal scaling can’t handle the elemental challenge of knowledge skew, the place some partitions stay a lot bigger than others whatever the variety of nodes.
State-heavy stream processing
State-heavy stream processing can embrace stateful operations with massive state necessities, windowed operations over streaming information with massive window sizes, or processing micro-batches with complicated state administration. Stateful stream processing typically requires sustaining massive quantities of state per key or window, which may’t be simply distributed throughout extra nodes with out compromising the integrity of the state.
In-memory caching
These eventualities would possibly embrace massive datasets that should be be cached for repeated entry, iterative algorithms requiring a number of passes over the identical information, or caching massive datasets for quick entry, which regularly requires retaining substantial parts of knowledge in every node’s reminiscence. Horizontal scaling won’t assist if the complete dataset must be cached on every node for optimum efficiency.
Information skew instance eventualities
A number of widespread patterns can usually trigger information skew, reminiscent of sorting or groupBy transformations on columns with non-uniformed worth distributions, and be part of operations the place sure keys seem extra steadily than different keys.
Within the following instance, we evaluate the conduct with two totally different employee varieties, G.2X and R.2X in the identical pattern workload to course of skewed information.
With G.2X employees
With the G.2X employee sort, an AWS Glue job with 10 employees failed as a consequence of a No house on left machine error whereas writing data into Amazon Easy Storage Service (Amazon S3). This was primarily attributable to massive shuffling on a particular column. The next Spark UI view reveals the job particulars.
The Jobs tab reveals two accomplished jobs and one lively job the place 8 duties failed out of 493 duties. Let’s drill all the way down to the main points.
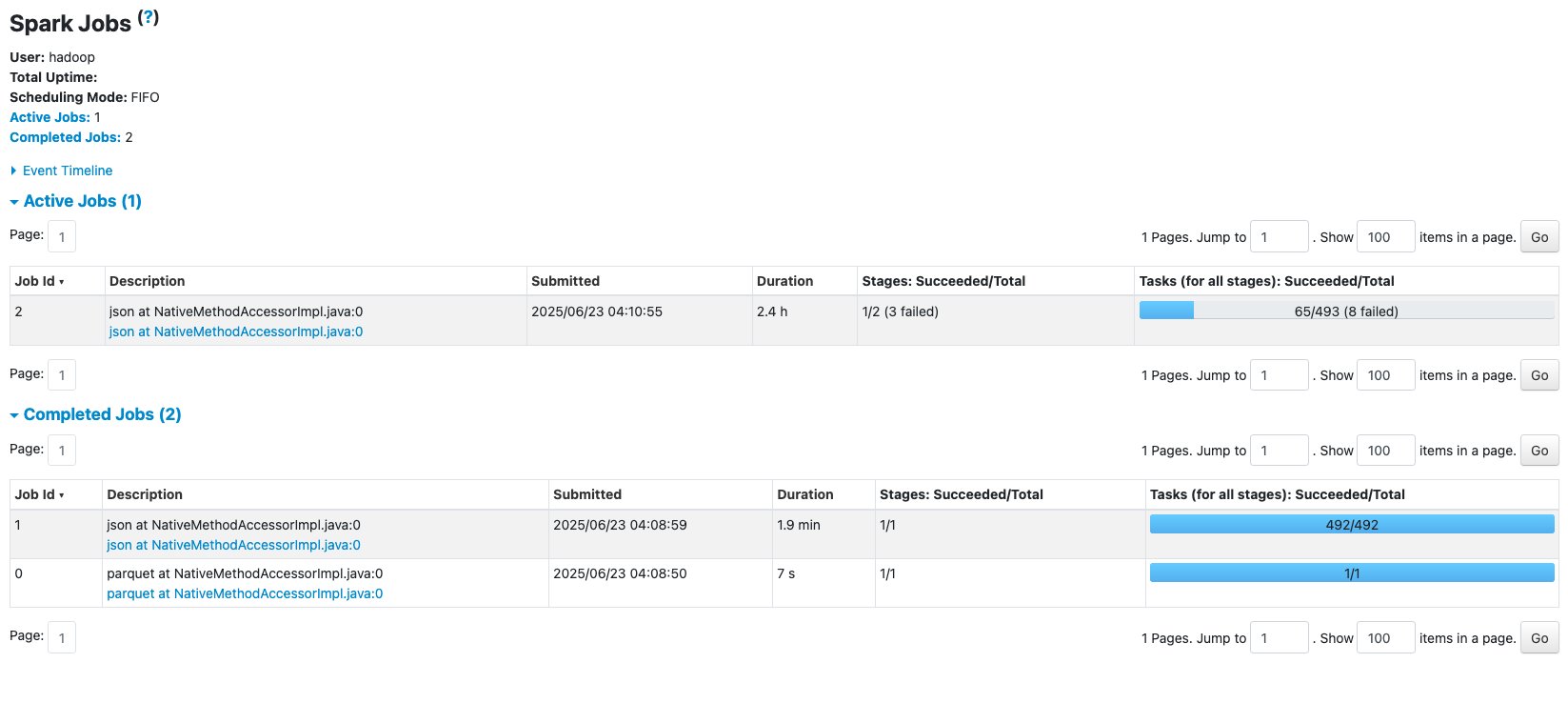
The Executors tab reveals an uneven distribution of knowledge processing throughout the Spark executors, which signifies information skew on this failed job. Executors with IDs 2, 7, and 10 have failed duties and browse roughly 64.5 GiB of shuffle information as proven within the Shuffle Learn column. In distinction, the opposite executors present 0.0 B of shuffle information within the Shuffle Learn column.

The G.2X employee sort can deal with most Spark workloads reminiscent of information transformations and be part of operations. Nonetheless, on this instance, there was important information skew, which precipitated sure executors to fail as a consequence of exceeding the allotted reminiscence.
With R.2X employees
With the R.2X employee sort, an AWS Glue job with 10 employees efficiently ran with none failures. The variety of employees is identical because the earlier instance—the one distinction is the employee sort. R employees have two instances extra reminiscence in comparison with G employees. The next Spark UI view reveals extra particulars.
The Jobs tab reveals three accomplished jobs. No failures are proven on this web page.
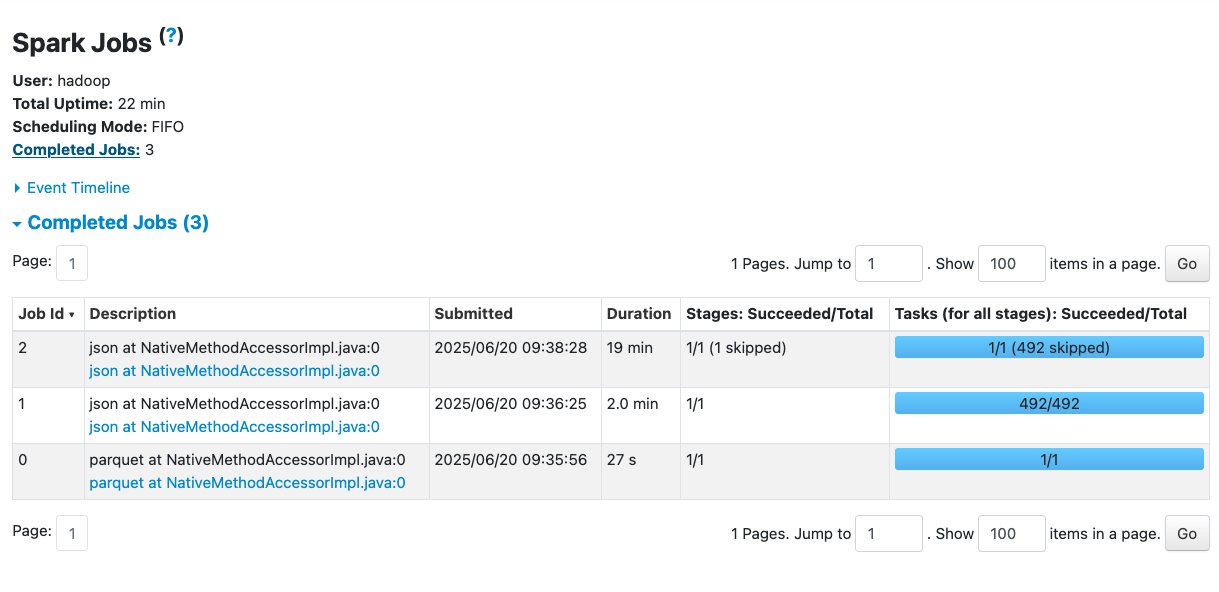
The Executors tab reveals no failed duties per executor despite the fact that there’s an uneven distribution of shuffle reads throughout executors.
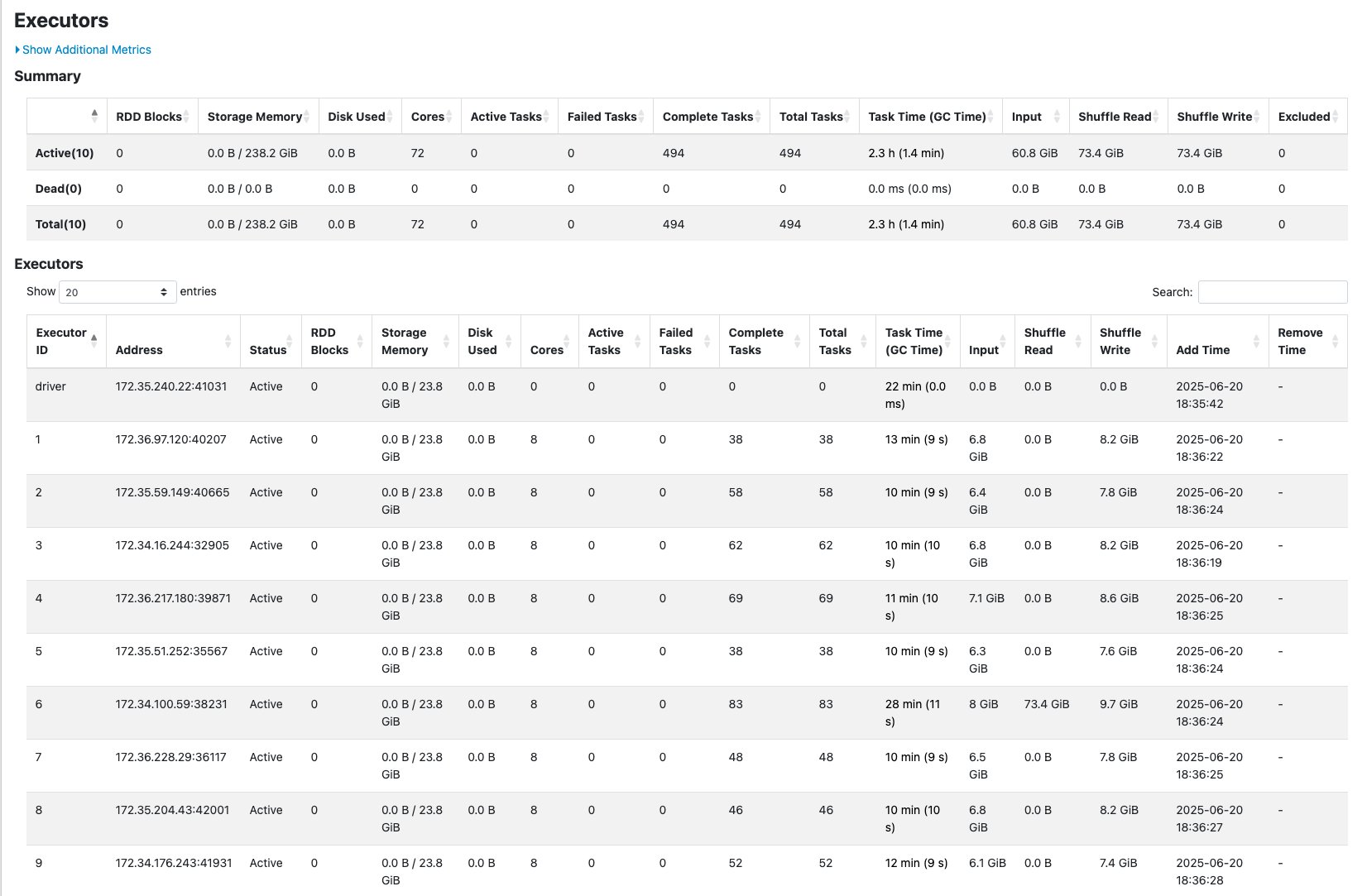
The outcomes confirmed that R.2X employees efficiently accomplished the workload that failed on G.2X employees utilizing the identical variety of executors however with the extra reminiscence capability to deal with the skewed information distribution.
Conclusion
On this submit, we demonstrated how AWS Glue R sort, G.12X, and G.16X employees may also help you vertically scale your AWS Glue for Apache Spark jobs. You can begin utilizing the brand new R sort, G.12X, and G.16X employees to scale your workload as we speak. For extra data on these new employee varieties and AWS Areas the place the brand new employees can be found, go to the AWS Glue documentation.
To be taught extra, see Getting Began with AWS Glue.
In regards to the Authors
 Noritaka Sekiyama is a Principal Large Information Architect with AWS Analytics companies. He’s answerable for constructing software program artifacts to assist prospects. In his spare time, he enjoys biking on his highway bike.
Noritaka Sekiyama is a Principal Large Information Architect with AWS Analytics companies. He’s answerable for constructing software program artifacts to assist prospects. In his spare time, he enjoys biking on his highway bike.
 Tomohiro Tanaka is a Senior Cloud Assist Engineer at Amazon Internet Companies. He’s captivated with serving to prospects use Apache Iceberg for his or her information lakes on AWS. In his free time, he enjoys a espresso break together with his colleagues and making espresso at house.
Tomohiro Tanaka is a Senior Cloud Assist Engineer at Amazon Internet Companies. He’s captivated with serving to prospects use Apache Iceberg for his or her information lakes on AWS. In his free time, he enjoys a espresso break together with his colleagues and making espresso at house.
 Peter Tsai is a Software program Growth Engineer at AWS, the place he enjoys fixing challenges within the design and efficiency of the AWS Glue runtime. In his leisure time, he enjoys mountain climbing and biking.
Peter Tsai is a Software program Growth Engineer at AWS, the place he enjoys fixing challenges within the design and efficiency of the AWS Glue runtime. In his leisure time, he enjoys mountain climbing and biking.
 Matt Su is a Senior Product Supervisor on the AWS Glue staff. He enjoys serving to prospects uncover insights and make higher selections utilizing their information with AWS Analytics companies. In his spare time, he enjoys snowboarding and gardening.
Matt Su is a Senior Product Supervisor on the AWS Glue staff. He enjoys serving to prospects uncover insights and make higher selections utilizing their information with AWS Analytics companies. In his spare time, he enjoys snowboarding and gardening.
 Sean McGeehan is a Software program Growth Engineer at AWS, the place he builds options for the AWS Glue achievement system. In his leisure time, he explores his house of Philadelphia and work metropolis of New York.
Sean McGeehan is a Software program Growth Engineer at AWS, the place he builds options for the AWS Glue achievement system. In his leisure time, he explores his house of Philadelphia and work metropolis of New York.

{kind=link}