

|
Amazon S3 Metadata now gives full visibility into all of your present objects in your Amazon Easy Storage Service (Amazon S3) buckets, increasing past new objects and modifications. With this expanded protection, you may analyze and question metadata on your total S3 storage footprint.
Right now, many purchasers depend on Amazon S3 to retailer unstructured knowledge at scale. To grasp what’s in a bucket, you typically have to construct and keep customized programs that scan for objects, observe modifications, and handle metadata over time. These programs are costly to keep up and exhausting to maintain updated as knowledge grows.
Since the launch of S3 Metadata at re:Invent 2024, you’ve been capable of question new and up to date object metadata utilizing metadata tables as an alternative of counting on Amazon S3 Stock or object-level APIs reminiscent of ListObjects, HeadObject, and GetObject—which may introduce latency and affect downstream workflows.
To make it simpler so that you can work with this expanded metadata, S3 Metadata introduces dwell stock tables that work with acquainted SQL-based instruments. After your present objects are backfilled into the system, any updates like uploads or deletions sometimes seem inside an hour in your dwell stock tables.
With S3 Metadata dwell stock tables, you get a totally managed Apache Iceberg desk that gives a whole and present snapshot of the objects and their metadata in your bucket, together with present objects, due to backfill assist. These tables are refreshed robotically inside an hour of modifications reminiscent of uploads or deletions, so that you keep updated. You should utilize them to determine objects with particular properties—like unencrypted knowledge, lacking tags, or specific storage lessons—and to assist analytics, price optimization, auditing, and governance.
S3 Metadata journal tables, beforehand often known as S3 Metadata tables, are robotically enabled whenever you configure dwell stock tables, present a close to real-time view of object-level modifications in your bucket—together with uploads, deletions, and metadata updates. These tables are perfect for auditing exercise, monitoring the lifecycle of objects, and producing event-driven insights. For instance, you need to use them to search out out which objects have been deleted previously 24 hours, determine the requester making probably the most PUT operations, or monitor updates to object metadata over time.
S3 Metadata tables are created in a namespace identify that’s much like your bucket identify for simpler discovery. The tables are saved in AWS desk buckets, grouped by account and Area. After you allow S3 Metadata for a common function S3 bucket, the system creates and maintains these tables for you. You don’t have to handle compaction or rubbish assortment processes—S3 Tables takes care of desk upkeep duties within the background.
These new tables assist keep away from ready for metadata discovery earlier than processing can start, making them excellent for large-scale analytics and machine studying (ML) workloads. By querying metadata forward of time, you may schedule GPU jobs extra effectively and scale back idle time in compute-intensive environments.
Let’s see the way it works
To see how this works in apply, I configure S3 Metadata for a common function bucket utilizing the AWS Administration Console.

After selecting a common function bucket, I select the Metadata tab, then I select Create metadata configuration.
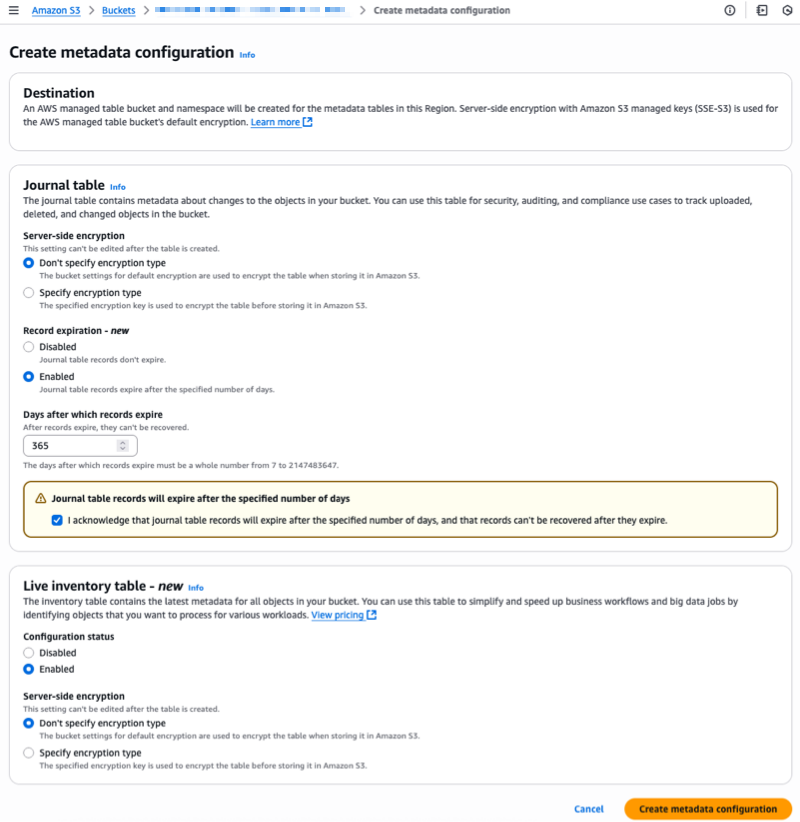 For Journal desk, I can select the Server-side encryption possibility and the Report expiration interval. For Dwell Stock desk, I select Enabled and I can choose the Server-side encryption choices.
For Journal desk, I can select the Server-side encryption possibility and the Report expiration interval. For Dwell Stock desk, I select Enabled and I can choose the Server-side encryption choices.
I configure Report expiration on the journal desk. Journal desk information expire after the required variety of days, three hundred and sixty five days (one 12 months) in my instance.
Then, I select Create metadata configuration.
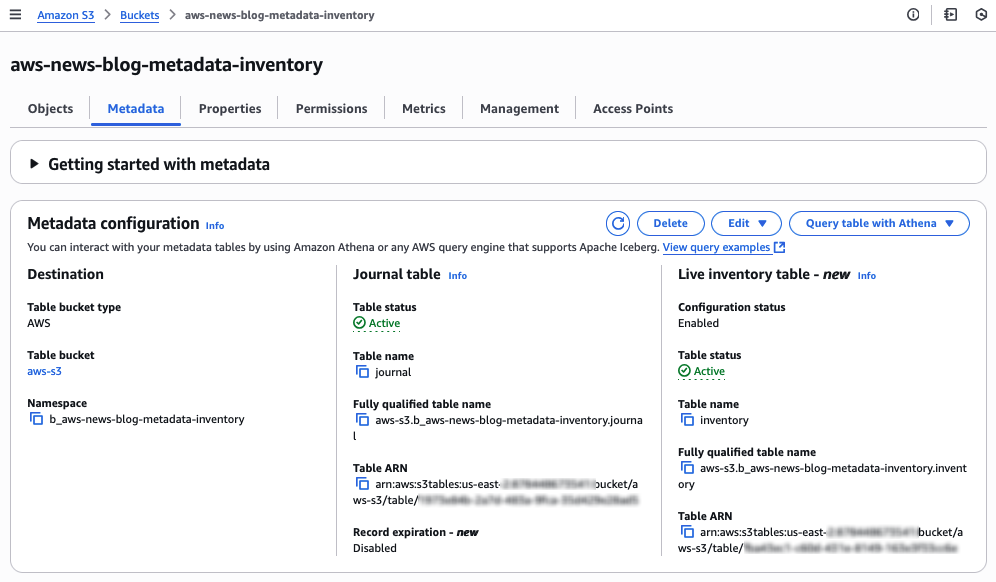
S3 Metadata creates the dwell stock desk and journal desk. Within the Dwell Stock desk part, I can observe the Desk standing: the system instantly begins to backfill the desk with present object metadata. It could take between minutes to hours. The precise time will depend on the amount of objects you may have in your S3 bucket.
Whereas ready, I additionally add and delete objects to generate knowledge within the journal desk.
Then, I navigate to Amazon Athena to begin querying the brand new tables.
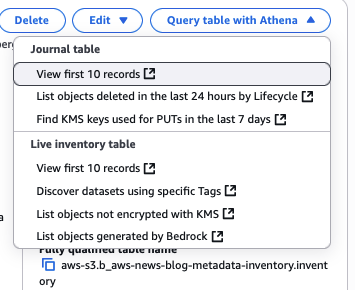
I select Question desk with Athena to begin querying the desk. I can select between a few default queries on the console.
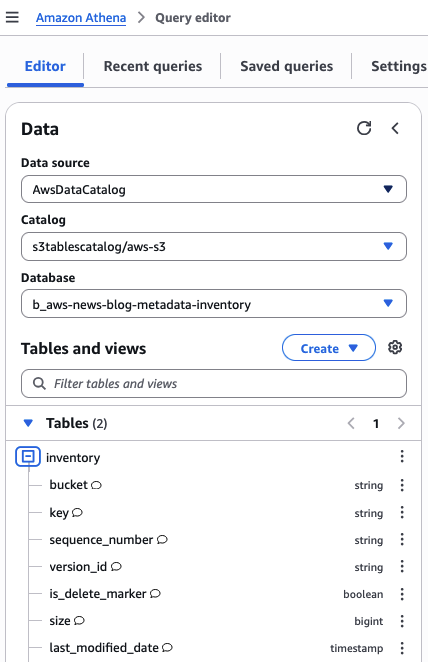
In Athena, I observe the construction of the tables within the AWSDataCatalog Knowledge supply and I begin with a brief question to examine what number of information can be found within the journal desk. I have already got 6,488 entries:
SELECT rely(*) FROM "b_aws-news-blog-metadata-inventory"."journal";
# _col0
1 6488Listed here are a few instance queries I attempted on the journal desk:
# Question deleted objects in final 24 hours
# Use is_delete_marker=true for versioned buckets and record_type="DELETE" in any other case
SELECT bucket, key, version_id, last_modified_date
FROM "s3tablescatalog/aws-s3"."b_aws-news-blog-metadata-inventory"."journal"
WHERE last_modified_date >= (current_date - interval '1' day) AND is_delete_marker = true;
# bucket key version_id last_modified_date is_delete_marker
1 aws-news-blog-metadata-inventory .construct/index-build/arm64-apple-macosx/debug/index/retailer/v5/information/G0/NSURLSession.h-JET61D329FG0
2 aws-news-blog-metadata-inventory .construct/index-build/arm64-apple-macosx/debug/index/retailer/v5/information/G5/cdefs.h-PJ21EUWKMWG5
3 aws-news-blog-metadata-inventory .construct/index-build/arm64-apple-macosx/debug/index/retailer/v5/information/FX/buf.h-25EDY57V6ZXFX
4 aws-news-blog-metadata-inventory .construct/index-build/arm64-apple-macosx/debug/index/retailer/v5/information/G6/NSMeasurementFormatter.h-3FN8J9CLVMYG6
5 aws-news-blog-metadata-inventory .construct/index-build/arm64-apple-macosx/debug/index/retailer/v5/information/G8/NSXMLDocument.h-1UO2NUJK0OAG8
# Question latest PUT requests IP addresses
SELECT source_ip_address, rely(source_ip_address)
FROM "s3tablescatalog/aws-s3"."b_aws-news-blog-metadata-inventory"."journal"
GROUP BY source_ip_address;
# source_ip_address _col1
1 my_laptop_IP_address 12488
# Question S3 Lifecycle expired objects in final 7 days
SELECT bucket, key, version_id, last_modified_date, record_timestamp
FROM "s3tablescatalog/aws-s3"."b_aws-news-blog-metadata-inventory"."journal"
WHERE requester="s3.amazonaws.com" AND record_type="DELETE" AND record_timestamp > (current_date - interval '7' day);
(not relevant to my demo bucket)The outcomes helped me observe the particular objects that have been eliminated, together with their timestamps.
Now, I take a look at the dwell stock desk:
# Distribution of object tags
SELECT object_tags, rely(object_tags)
FROM "s3tablescatalog/aws-s3"."b_aws-news-blog-metadata-inventory"."stock"
GROUP BY object_tags;
# object_tags _col1
1 {Supply=Swift} 1
2 {Supply=swift} 1
3 {} 12486
# Question storage class and dimension for particular tags
SELECT storage_class, rely(*) as rely, sum(dimension) / 1024 / 1024 as utilization
FROM "s3tablescatalog/aws-s3"."b_aws-news-blog-metadata-inventory"."stock"
GROUP BY object_tags['pii=true'], storage_class;
# storage_class rely utilization
1 STANDARD 124884 165
# Discover objects with particular person outlined metadata
SELECT key, last_modified_date, user_metadata
FROM "s3tablescatalog/aws-s3"."b_aws-news-blog-metadata-inventory"."stock"
WHERE cardinality(user_metadata) > 0 ORDER BY last_modified_date DESC;
(not relevant to my demo bucket)These are only a few examples of what’s attainable with S3 Metadata. Your most popular queries will rely in your use circumstances. Consult with Analyzing Amazon S3 Metadata with Amazon Athena and Amazon QuickSight within the AWS Storage Weblog for extra examples.
Pricing and availability
S3 Metadata dwell stock and journal tables can be found as we speak in US East (N. Virginia), US East (Ohio), and US West (Oregon).
The journal tables are charged $0.30 per million updates. It is a 33 % drop from our earlier worth.
For stock tables, there’s a one-time backfill price of $0.30 for 1,000,000 objects to arrange the desk and generate metadata for present objects. There aren’t any further prices in case your bucket has lower than one billion objects. For buckets with greater than a billion objects, there’s a month-to-month payment of $0.10 per million objects monthly.
As typical, the Amazon S3 pricing web page has all the small print.
With S3 Metadata dwell stock and journal tables, you may scale back the effort and time required to discover and handle giant datasets. You get an up-to-date view of your storage and a report of modifications, and each can be found as Iceberg tables you may question on demand. You’ll be able to uncover knowledge sooner, energy compliance workflows, and optimize your ML pipelines.
You may get began by enabling metadata stock in your S3 bucket by means of the AWS console, AWS Command Line Interface (AWS CLI), or AWS SDKs. Once they’re enabled, the journal and dwell stock tables are robotically created and up to date. To be taught extra, go to the S3 Metadata Documentation web page.
Replace 7/15/2025: Revised some code and up to date Area checklist.

{kind=link}