
Introduction to Studying-Based mostly Robotics
Robotic management programs have made vital progress by way of strategies that change hand-coded directions with data-driven studying. As an alternative of counting on express programming, fashionable robots be taught by observing actions and mimicking them. This type of studying, usually grounded in behavioral cloning, allows robots to operate successfully in structured environments. Nevertheless, transferring these realized behaviors into dynamic, real-world eventualities stays a problem. Robots needn’t solely to repeat actions but in addition to adapt and refine their responses when dealing with unfamiliar duties or environments, which is important in reaching generalized autonomous conduct.
Challenges with Conventional Behavioral Cloning
One of many core limitations of robotic coverage studying is the dependence on pre-collected human demonstrations. These demonstrations are used to create preliminary insurance policies by way of supervised studying. Nevertheless, when these insurance policies fail to generalize or carry out precisely in new settings, extra demonstrations are required to retrain them, which is a resource-intensive course of. The lack to enhance insurance policies utilizing the robotic’s personal experiences results in inefficient adaptation. Reinforcement studying can facilitate autonomous enchancment; nevertheless, its pattern inefficiency and reliance on direct entry to complicated coverage fashions render it unsuitable for a lot of real-world deployments.
Limitations of Present Diffusion-RL Integration
Numerous strategies have tried to mix diffusion-based insurance policies with reinforcement studying to refine robotic conduct. Some efforts have targeted on modifying the early steps of the diffusion course of or making use of additive changes to coverage outputs. Others have tried to optimize actions by evaluating anticipated rewards throughout the denoising steps. Whereas these approaches have improved leads to simulated environments, they require intensive computation and direct entry to the coverage’s parameters, which limits their practicality for black-box or proprietary fashions. Additional, they battle with the instability that comes from backpropagating by way of multi-step diffusion chains.
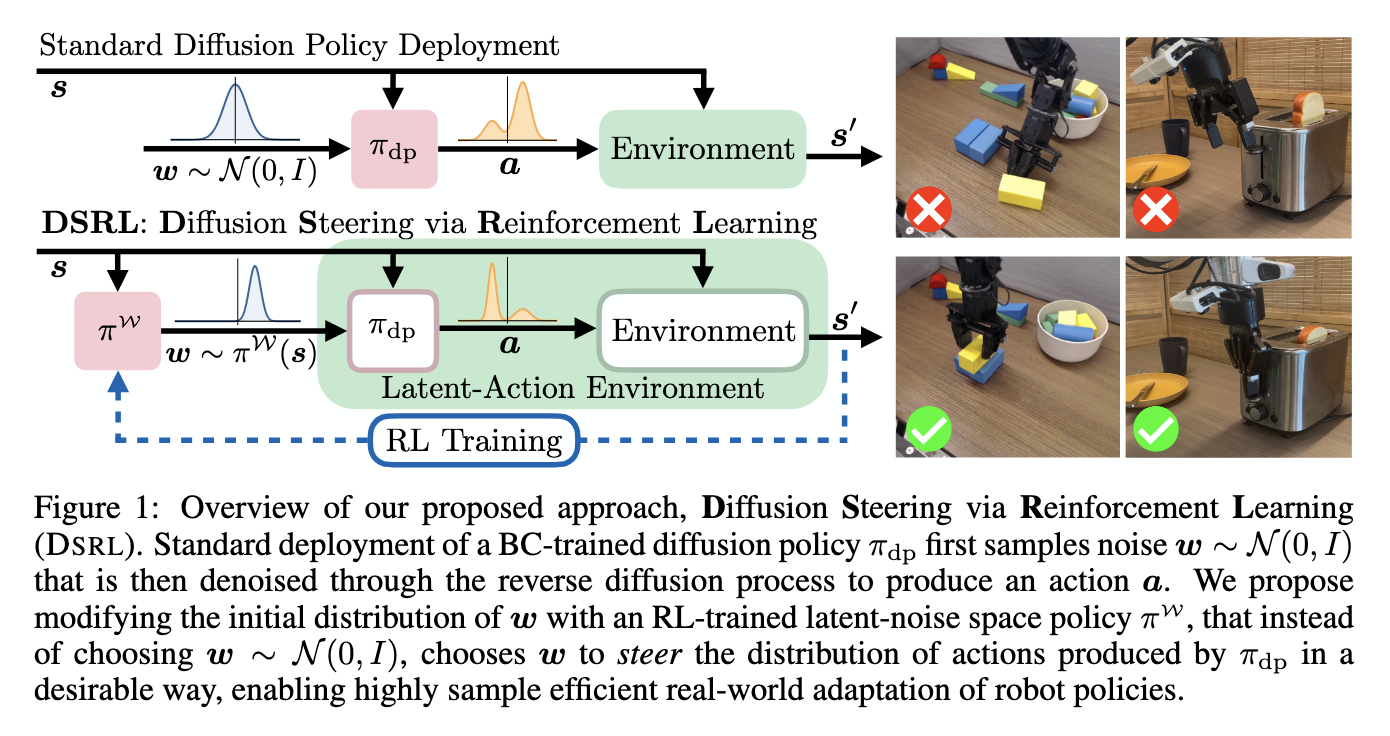
DSRL: A Latent-Noise Coverage Optimization Framework
Researchers from UC Berkeley, the College of Washington, and Amazon launched a method referred to as Diffusion Steering through Reinforcement Studying (DSRL). This methodology shifts the variation course of from modifying the coverage weights to optimizing the latent noise used within the diffusion mannequin. As an alternative of producing actions from a set Gaussian distribution, DSRL trains a secondary coverage that selects the enter noise in a method that steers the ensuing actions towards fascinating outcomes. This permits reinforcement studying to fine-tune behaviors effectively with out altering the bottom mannequin or requiring inside entry.

Latent-Noise House and Coverage Decoupling
The researchers restructured the training setting by mapping the unique motion house to a latent-noise house. On this remodeled setup, actions are chosen not directly by selecting the latent noise that can produce them by way of the diffusion coverage. By treating the noise because the motion variable, DSRL creates a reinforcement studying framework that operates fully exterior the bottom coverage, utilizing solely its ahead outputs. This design makes it adaptable to real-world robotic programs the place solely black-box entry is accessible. The coverage that selects latent noise could be skilled utilizing commonplace actor-critic strategies, thereby avoiding the computational price of backpropagation by way of diffusion steps. The method permits for each on-line studying by way of real-time interactions and offline studying from pre-collected knowledge.
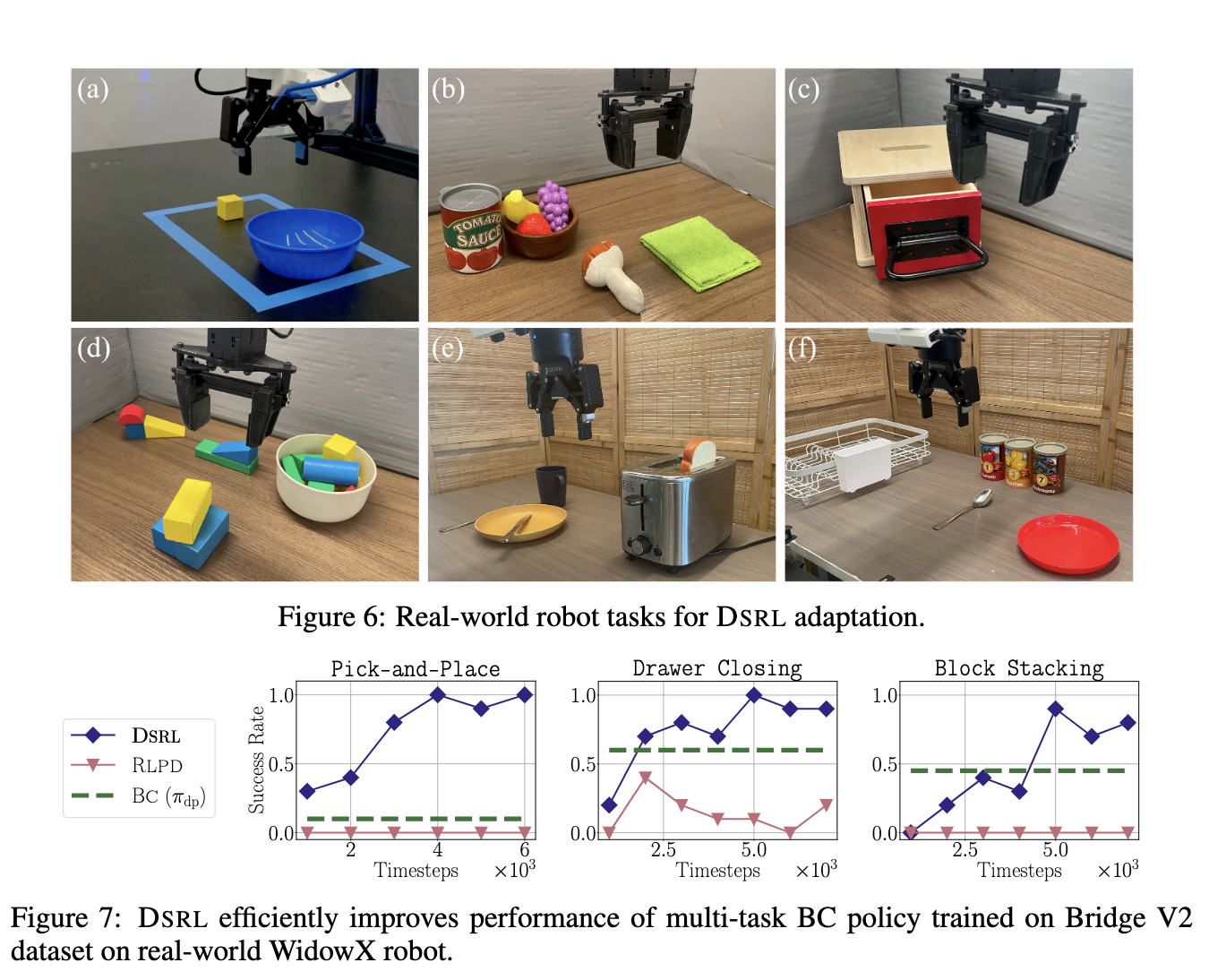
Empirical Outcomes and Sensible Advantages
The proposed methodology confirmed clear enhancements in efficiency and knowledge effectivity. For example, in a single real-world robotic job, DSRL improved job success charges from 20% to 90% inside fewer than 50 episodes of on-line interplay. This represents a greater than fourfold improve in efficiency with minimal knowledge. The tactic was additionally examined on a generalist robotic coverage named π₀, and DSRL was capable of successfully improve its deployment conduct. These outcomes have been achieved with out modifying the underlying diffusion coverage or accessing its parameters, showcasing the strategy’s practicality in restricted environments, resembling API-only deployments.
Conclusion
In abstract, the analysis tackled the core problem of robotic coverage adaptation with out counting on intensive retraining or direct mannequin entry. By introducing a latent-noise steering mechanism, the staff developed a light-weight but highly effective device for real-world robotic studying. The tactic’s energy lies in its effectivity, stability, and compatibility with current diffusion fashions, making it a big step ahead within the deployment of adaptable robotic programs.
Try the Paper and Undertaking Web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


{kind=link}