Dealing with scalability limitations with Apache Kafka for log file administration, LinkedIn developed a brand new publish-and-subscribe (pub/sub) system that didn’t face the identical limitations. The substitute pub/sub system that LinkedIn developed is known as Northguard, and it’s now actively migrating its Kafka-based information to Northguard by way of a virtualized pub/sub layer dubbed Xinfra, the corporate introduced as we speak.
When Jay Kreps and his LinkedIn engineer colleagues Jun Rao and Neha Narkhede created Apache Kafka again in 2010, the social media website had 90 million members. At the moment, the corporate struggled with main latency points because it tried to load about 1 billion information per day into its Hadoop-based information infrastructure. To handle this problem, Kreps and firm developed Kafka as a distributed, fault-tolerant, high-throughput, and scalable platform for constructing real-time information pipelines.
Kafka was a giant hit internally at LinkedIn, because it offered a virtualization layer between the creation (or publishers) of information and the customers (or subscribers) of information. It was used extensively internally, and was donated to the Apache Software program Basis the next 12 months. Kreps, Rao, and Narkhede left LinkedIn and in 2014 co-founded Confluent, which final 12 months generated almost $1 billion in income.
Through the years, LinkedIn’s enterprise expanded, and Kafka remained a central element of its inner and user-facing programs and functions. Nevertheless, sooner or later, the amount of information being generated inside LinkedIn surpassed Kafka’s capabilities. At the moment, with 1.2 billion customers, its pub/sub programs are requested to ingest greater than 32 trillion data per day, accounting for 17 PB throughout 400,000 subjects, which run on greater than 150 clusters accounting for greater than 10,000 particular person nodes.
This scale of information has surpassed Kafka’s capabilities, in response to LinkedIn engineers Onur Karaman and Xiongqi Wu. “….[A]s LinkedIn grew and our use instances grew to become extra demanding, it grew to become more and more troublesome to scale and function Kafka,” the engineers wrote in a publish on the LinkedIn Engineering Weblog as we speak. “That’s why we’re transferring to the following step on our journey with Northguard, a log storage system with improved scalability and operability.
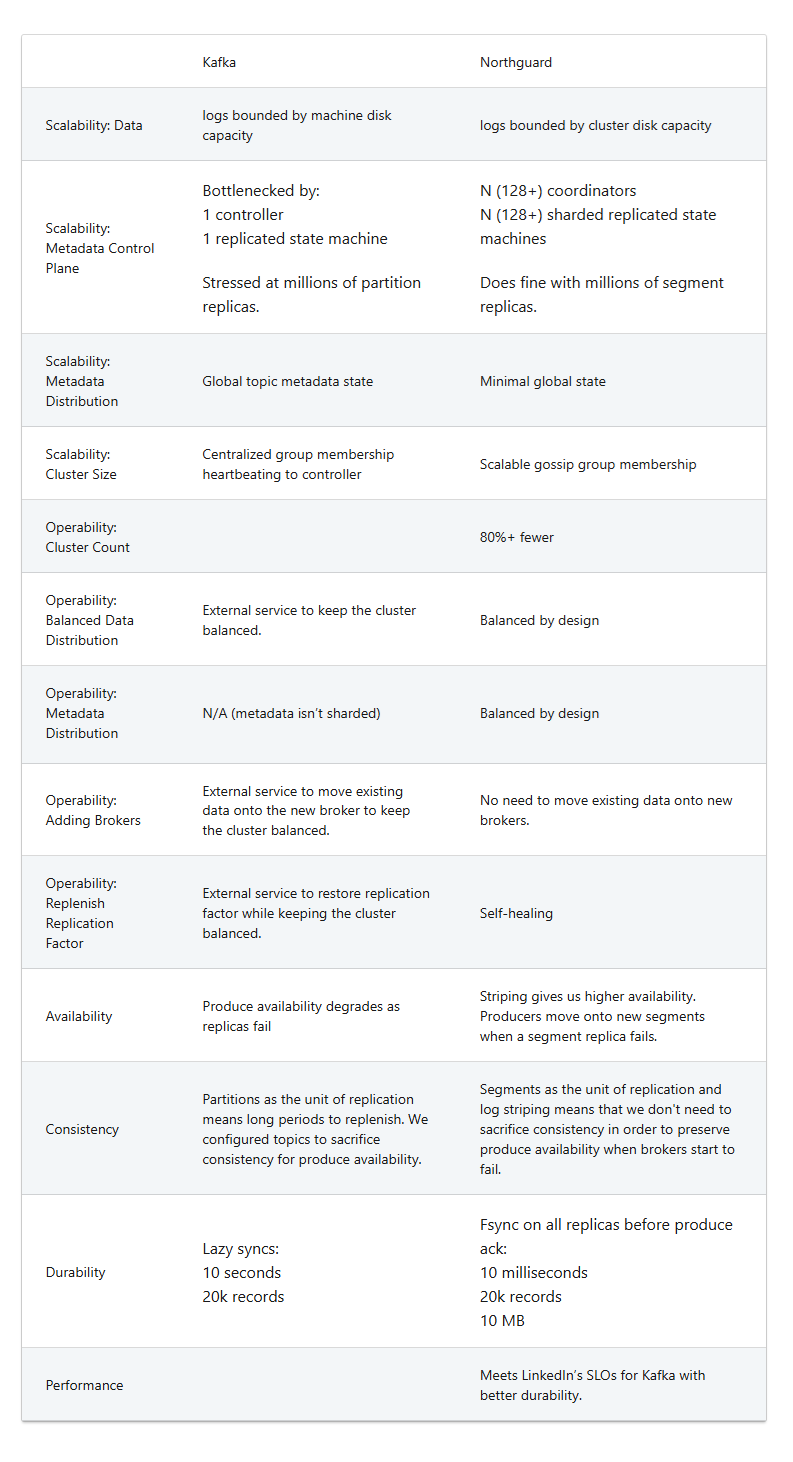
The Kafka challenges centered on 5 foremost areas, in response to Karaman and Wu. Scaling the Kafka clusters grew to become more and more troublesome as LinkedIn added extra use instances, which resulted in additional information and extra metadata. With 150 Kafka clusters to handle, load balancing was additionally a problem.
The supply of information was additionally problem, notably since information replication was dealt with on the particular person partition degree. Consistency additionally grew to become an issue, notably when LinkedIn traded off consistency in favor of availability (because of the aforementioned partition replication subject). Lastly, sturdiness of information suffered from weak ensures.
“We wanted a system that scales properly not simply by way of information, but additionally by way of its metadata and cluster measurement, all whereas supporting lights-out operations with even load distribution by design and quick cluster deployments, no matter scale,” Karaman and Wu wrote. “Moreover, we required robust consistency in each our information and metadata, together with excessive throughput, low latency, extremely out there, excessive sturdiness, low price, compatibility with varied forms of {hardware}, pluggability, and testability.”
Northguard is a brand new pub/sub system that can exchange Kafka at LinkedIn (Picture courtesy LInkedIn)
The answer that Karaman and Wu got here up with is a log storage system known as Northguard. The engineer describe the core traits of the brand new system:
“To realize excessive scalability, Northguard shards its information and metadata, maintains minimal world state, and makes use of a decentralized group membership protocol,” they write. “Its operability leans on log striping to distribute load throughout the cluster evenly by design. Northguard is run as a cluster of brokers which solely work together with purchasers that hook up with them and different brokers throughout the cluster.”
The Northguard information mannequin relies on the idea of a document, which consists of a key, a price, and user-defined header. A sequence of data in Northguard is known as a phase, which is the minimal unit of replication within the system. Segments will be energetic, through which case they are often appended to, or they are often sealed, resulting from reproduction failure, reaching a most measurement restrict of 1GB, or from the phase being energetic for a couple of hour.
Equally, a variety is a sequence of segments in Northguard that’s bounded by a keyspace. These segments will be both energetic or sealed, the engineers write. A subject is a named assortment of ranges that covers the complete keyspace when mixed. A subject’s vary will be cut up into two ranges, or merged to create a brand new youngster vary (however provided that it falls inside a novel “buddy vary”). Matters will be sealed or deleted.

Onur Karaman (left) and Xiongqu Wu, the creators of Northguard at LinkedIn
Northguard is unary, the engineers write, which signifies that one request leads to one response. The system shops information within the “fps retailer,” use a write-ahead log (WAL), and in addition maintains a “sparse index” in RocksDB.
“Appends are collected in a batch till adequate time has handed (ex: 10 ms), the batch exceeds a configurable measurement, or the batch exceeds a configurable variety of appends,” the engineers write. “As soon as able to flush the batch, the shop synchronously writes to the WAL, appends data to a number of phase information, fsyncs these information, and updates the index.”
Directors work with subjects by assigning them storage insurance policies, which entails giving them names, retention intervals that defines when the segments must be deleted, and a set of constraints. The constraints are outlined by expressions and a set of keys and values which can be certain to brokers, that are known as attributes, the engineers write.
“Insurance policies and attributes are a strong abstraction,” Karaman and Wu write. “For instance, Northguard itself has no native understanding of racks, datacenters, and so forth. Directors at LinkedIn simply encode this state within the insurance policies and attributes on the brokers we deploy, making insurance policies and attributes a generalized answer to rack-aware reproduction project. We even use insurance policies and attributes to distribute replicas in a method that enables us to securely deploy builds and configs to clusters in fixed time no matter cluster measurement.”
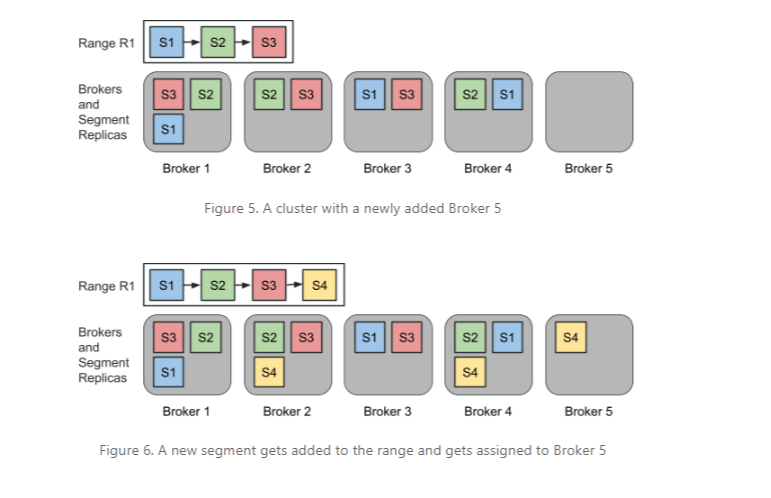
Northguard additionally implement the idea of log striping, which it makes use of to keep away from situations of “useful resource skew” in clusters. Since Northguard has such a low-level unit of replication–the person log, versus a partition in Kafka, which prompted its personal set of issues–it will be liable to useful resource skew, which will be laborious to take care of.
Variations between Kafka and Northguard (Picture courtesy LinkedIn)
“Northguard ranges keep away from these points by implementing log striping, that means that it breaks a log into smaller chunks for balancing IO load,” the engineers write. “These chunks have their very own reproduction units versus the log. Ranges and segments are the Northguard analog of logs and chunks. Since segments are created comparatively typically, we don’t want to maneuver present segments onto new brokers. New brokers simply organically begin changing into phase replicas of recent segments. This additionally signifies that unfortunate combos of segments touchdown on a dealer aren’t a problem, as it’ll type itself out when new segments are created and assigned to different brokers. The cluster balances by itself.”
The engineers additionally talk about Northguard’s metadata mannequin, which is used for managing subjects, ranges, and segments. The pub/sub system makes use of the idea of a “vnode” to retailer a shard of the cluster’s metadata. “A vnode is a fault-tolerant replicated state machine backed by Raft and acts because the core constructing block behind Northguard’s distributed metadata storage and metadata administration,” Karaman and Wu write.
The enterprise logic of the metadata lives inside a coordinator, which is the chief of a given vnode and the place state is endured. The coordinator tracks modifications for subjects owned by the vnode, resembling sealing or deleting the subject and splitting or merging ranges from that matter, the engineers write. The way in which it manages metadata makes Northguard self-healing, they write.
A group of vnodes assembled right into a hash ring is known as a Dynamically-Sharded Replicated State Machine (DS-RSM). By sharding metadata throughout vnodes utilizing hashing, it may well keep away from metadata hotspots, the engineers write. Northguard makes use of a distributed system protocol known as SWIM, which “employs random probing for failure detection however infection-style dissemination for membership modifications and broadcasts,” the engineers write.
LinkedIn has begun implementing Northguard and changing Kafka because the pub/sub system for sure functions. Since Northguard is written in C++ and Kafka was written in Java, there are compatibility points. One other issue is the enterprise vital nature of the functions and the shortcoming to just accept downtime.
To handle these points, LinkedIn developed a virtualized pub/sub layer known as Xinfra (pronounced ZIN-frah) that may assist each Northguard and Kafka. Whereas a Kafka consumer can solely discuss to a single Kafka cluster, Xinfra isn’t certain by the identical limitations, permitting an utility utilizing Xinfra to concurrently assist Kafka and Northguard. “This implies customers don’t want to alter the subject when it’s migrated between clusters at runtime,” the engineers write.
LinkedIn has already migrated hundreds of subjects from Kafka to Northguard, but it surely nonetheless has a number of hundred thousand to go. The excellent news for LinkedIn is that greater than 90% of its functions now are operating Xinfra purchasers, which ought to make the migration simpler.
“Trying forward, our focus can be on driving even higher adoption of Northguard and Xinfra, including options resembling auto-scaling subjects based mostly on site visitors development, and enhancing fault tolerance for virtualized matter operations,” the engineers write. “We’re thrilled to proceed this journey!”
Associated Objects:
Confluent Says ‘Au Revoir’ to Zookeeper with Launch of Confluent Platform 8.0
LinkedIn Donates Characteristic Retailer to Linux Basis

{kind=link}