
The Problem of Positive-Tuning Massive Transformer Fashions
Self-attention allows transformer fashions to seize long-range dependencies in textual content, which is essential for comprehending complicated language patterns. These fashions work effectively with large datasets and obtain outstanding efficiency without having task-specific buildings. Consequently, they’re broadly utilized throughout industries, together with software program improvement, training, and content material technology.
A key limitation in making use of these highly effective fashions is the reliance on supervised fine-tuning. Adapting a base transformer to a selected job sometimes includes retraining the mannequin with labeled information, which calls for vital computational assets, typically amounting to 1000’s of GPU hours. This presents a serious barrier for organizations that lack entry to such {hardware} or search faster adaptation occasions. Consequently, there’s a urgent want for strategies that may elicit task-specific capabilities from pre-trained transformers with out modifying their parameters.
Inference-Time Prompting as an Different to Positive-Tuning
To handle this subject, researchers have explored inference-time strategies that information the mannequin’s conduct utilizing example-based inputs, bypassing the necessity for parameter updates. Amongst these strategies, in-context studying has emerged as a sensible strategy the place a mannequin receives a sequence of input-output pairs to generate predictions for brand spanking new inputs. In contrast to conventional coaching, these strategies function throughout inference, enabling the bottom mannequin to exhibit desired behaviors solely primarily based on context. Regardless of their promise, there was restricted formal proof to substantiate that such strategies can persistently match fine-tuned efficiency.
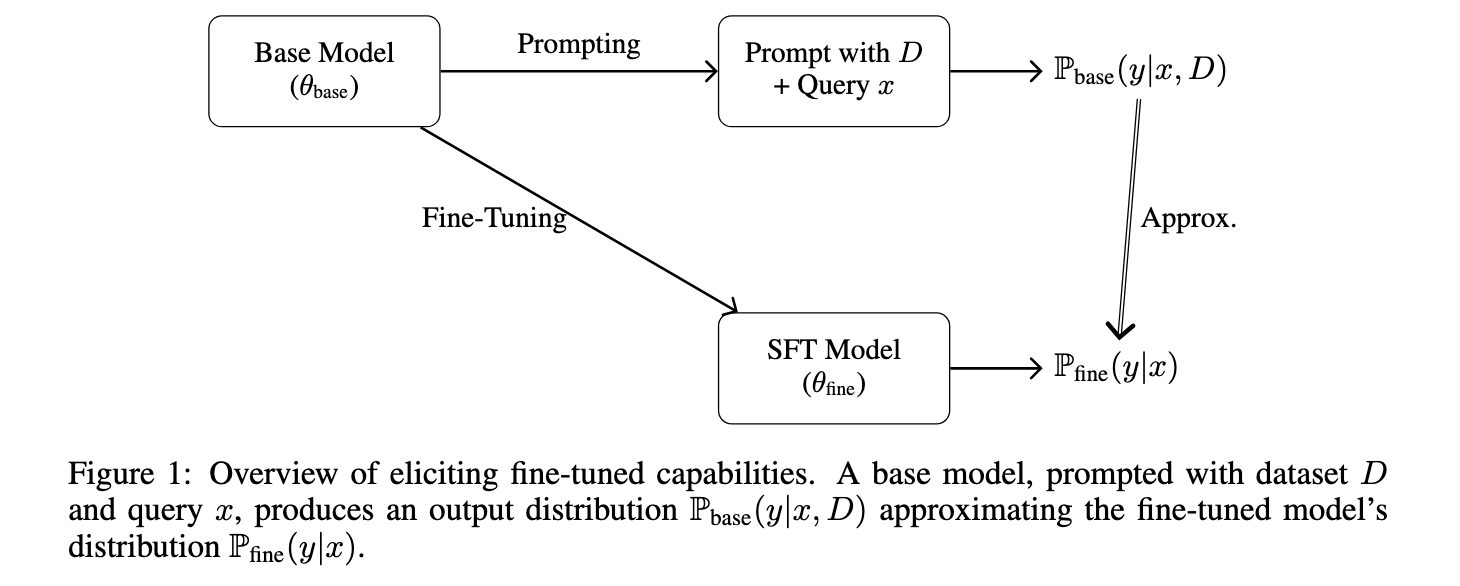
Theoretical Framework: Approximating Positive-Tuned Fashions through In-Context Studying
Researchers from Patched Codes, Inc. launched a way grounded within the Turing completeness of transformers, demonstrating {that a} base mannequin can approximate the conduct of a fine-tuned mannequin utilizing in-context studying, offered enough computational assets and entry to the unique coaching dataset. Their theoretical framework presents a quantifiable strategy to understanding how dataset measurement, context size, and job complexity affect the standard of the approximation. The evaluation particularly examines two job varieties—textual content technology and linear classification—and establishes bounds on dataset necessities to realize fine-tuned-like outputs with an outlined error margin.
Immediate Design and Theoretical Ensures
The strategy includes designing a immediate construction that concatenates a dataset of labeled examples with a goal question. The mannequin processes this sequence, drawing patterns from the examples to generate a response. As an example, a immediate might embrace input-output pairs like sentiment-labeled evaluations, adopted by a brand new evaluation whose sentiment should be predicted. The researchers constructed this course of as a simulation of a Turing machine, the place self-attention mimics the tape state and feed-forward layers act as transition guidelines. Additionally they formalized situations underneath which the full variation distance between the bottom and fine-tuned output distributions stays inside a suitable error ε. The paper offers a development for this inference method and quantifies its theoretical efficiency.
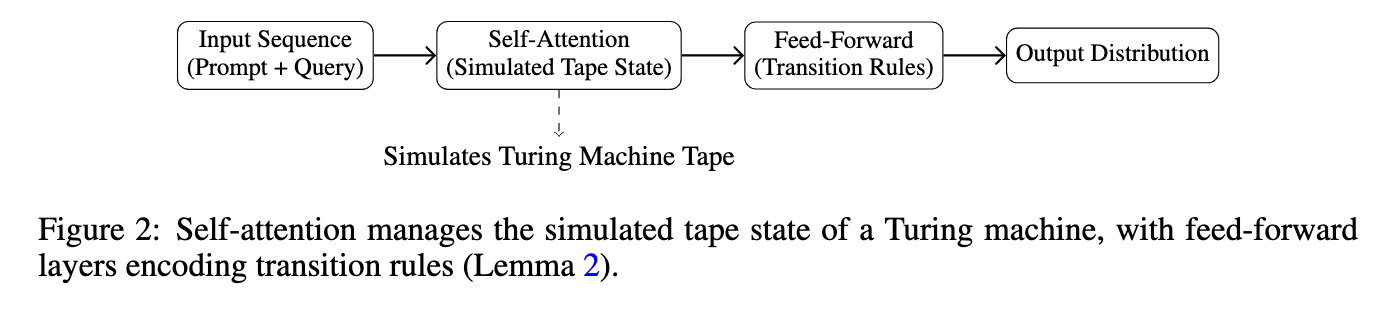
Quantitative Outcomes: Dataset Measurement and Job Complexity
The researchers offered efficiency ensures primarily based on dataset measurement and job kind. For textual content technology duties involving a vocabulary measurement V, the dataset should be of sizeOmVϵ2log1δ to make sure the bottom mannequin approximates the fine-tuned mannequin inside an error ε throughout mmm contexts. When the output size is mounted at l, a smaller dataset of measurement Ol logVϵ2log1δ suffices. For linear classification duties the place the enter has dimension d, the required dataset measurement turns into Odϵ, or with context constraints, O1ϵ2log1δ. These outcomes are strong underneath idealized assumptions but additionally tailored to sensible constraints like finite context size and partial dataset availability utilizing strategies similar to retrieval-augmented technology.
Implications: In direction of Environment friendly and Scalable NLP Fashions
This analysis presents an in depth and well-structured argument demonstrating that inference-time prompting can intently match the capabilities of supervised fine-tuning, offered enough contextual information is provided. It efficiently identifies a path towards extra resource-efficient deployment of huge language fashions, presenting each a theoretical justification and sensible strategies. The research demonstrates that leveraging a mannequin’s latent capabilities by structured prompts isn’t just viable however scalable and extremely efficient for particular NLP duties.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, be at liberty to observe us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Publication.
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


{kind=link}