
Multimodal Massive Language Fashions (MLLMs) have currently turn into the discuss of the AI universe. It’s dynamically reshaping how AI programs perceive and work together with our advanced, multi-sensory world. These multi-sensory inputs that we get will also be coined as our completely different modalities (photographs, audio, and so forth.). From Google’s newest Veo 3, producing state-of-the-art movies to ElevenLabs creating extremely practical AI voice overs, these programs are demonstrating capabilities that have been as soon as thought of to be science fiction.
This complete information is the primary a part of a two-part collection exploring the intricate world of multimodal LLMs. The second a part of this collection will discover how these fashions generate multimodal content material and their sensible purposes throughout varied industries.
Challenges of Multimodality
Multimodality is unquestionably one of many best capabilities and developments in AI fashions. Nonetheless, once we cope with a number of modalities, there will probably be sure challenges that must be curbed. Listed here are two main challenges we face on this regard:
- signify our data?
One of many predominant challenges of multimodal LLMs is with regards to representing various kinds of data. It’s easy methods to signify and summarize these multimodal information in a typical area which we have to practice our multimodal fashions. - How will we align our completely different modalities?
We now have to make sure we determine direct relations between related components from completely different modalities. That is completed in two methods:- Express Alignment: Right here, we immediately discover correspondences between components of various modalities. For this, we have now to coach our mannequin throughout varied modalities like audio, textual content, picture, and so forth. This supervised or rule-based alignment is carried out utilizing algorithms like Dynamic Time Warping (DTW), Consideration with supervision, or alignment matrices.
- Implicit Alignment: This makes use of internally latent alignment of modalities to higher resolve completely different issues. Permitting the mannequin to determine it out itself. Fashions use strategies like self-attention, contrastive studying, or co-attention mechanisms to study which components of 1 modality relate to a different.

Let’s perceive this with a small instance:
Since we have to signify the time period “cat” whether or not it’s within the type of textual content, picture, or speech as intently as attainable, we must always be certain different phrases like ”canine” are removed from the neighborhood of the time period “cat”. These embeddings from varied modalities must be accurately aligned throughout the shared dimensional area.

Illustration Studying
The answer to our first drawback on “easy methods to signify data” could be solved by illustration studying. There are 2 varieties of representations-based studying by which multimodal data could possibly be understood by these multimodal fashions. These are: Joint Illustration and Coordinated Illustration.
Joint Illustration
Joint illustration could possibly be outlined as a single unified illustration of various kinds of data which could possibly be textual content, picture, video, audio, and so forth. We mix the embeddings of every modality in a single embedding dimension area.

Right here, on this strategy, we’ll move every modality throughout its respective encoders. Principally, Textual content will probably be handed by a Textual content Encoder (e.g. BERT) and picture throughout an Picture Encoder (e.g. VIT) likewise for different modalities.

We get the embeddings for every modality. Later, these embedding representations merge utilizing a concatenation method. Then, a projection layer or multimodal consideration mechanism will assign sure significance to sure options. The ensuing joint embedding will comprise the entire semantics of all of the enter modalities.
This whole system is educated. The particular person modality encoders, the fusion mechanism, and the ultimate task-specific layers are all optimized collectively utilizing a single loss operate. This unified coaching setup permits the mannequin to study cross-modal correlations extra successfully, particularly when the modalities are strongly interdependent (e.g. picture and its caption like within the COCO dataset).
These joint embeddings are significantly helpful when the enter modalities are intently aligned or when the accessible coaching information is proscribed, as shared representations assist in regularizing the training course of and extracting richer, semantically significant options from the mixed enter.
Learn extra concerning the Evolution of Embeddings.
Coordinated Illustration
Coordinated Illustration studying on the opposite facet has a very completely different strategy. Right here, we study unbiased representations alone after which coordinate (or align) them collectively within the fusion stage. On this strategy, every modality (textual content, picture, audio, and so forth.) is dealt with by its devoted mannequin, which is educated individually and may have its loss operate and goal.
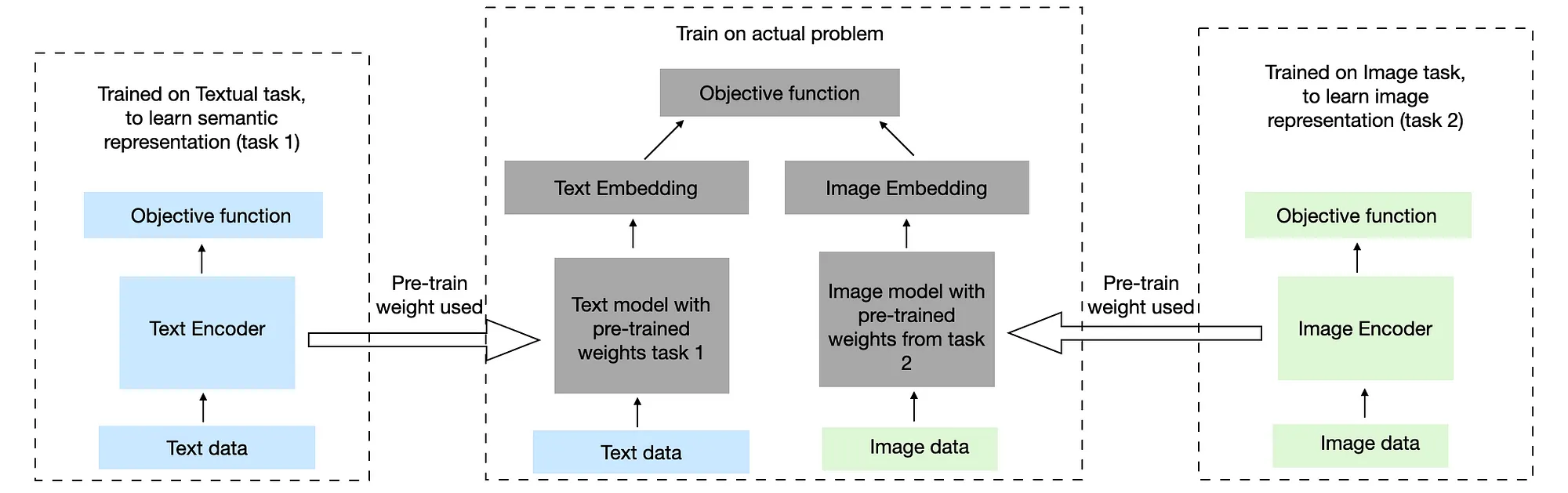
As soon as these fashions are educated, their particular person output embeddings are mixed utilizing a coordinated fusion mechanism like late fusion (easy concatenation), cross-modal consideration, or statistical alignment strategies akin to Canonical Correlation Evaluation (CCA). The coordination section focuses on making certain that the separate embeddings are semantically aligned with one another in order that they’ll collectively contribute to the ultimate prediction. In contrast to joint embeddings, coordinated embeddings enable every modality to protect its personal characteristic construction with out being compelled right into a shared illustration area prematurely.
This methodology is very efficient when modalities are considerably unbiased or loosely coupled, when there may be ample modality-specific information, or when computational sources enable for extra intensive pre-training. Coordinated embeddings additionally provide higher flexibility in mannequin structure and coaching pipelines, as every modality could be improved independently earlier than coordination.
Express vs Implicit Alignment
Let’s attempt to tabulate our understanding right here:
| Function | Express Alignment | Implicit Alignment |
| Nature | Supervised / Annotated | Unsupervised / Realized throughout coaching |
| Want for Labels | Requires aligned or annotated information | Doesn’t require specific alignments |
| Method | Guide or rule-based mapping | Realized through consideration or contrastive loss |
| Instance Duties | Picture captioning with bounding containers | CLIP, VQA with unsupervised consideration |
| Benefits | Excessive precision, interpretable | Scalable, versatile, study fine-grained hyperlinks |
| Challenges | Costly to label, much less versatile | Will be much less interpretable, data-hungry |
We’ll now attempt to perceive one other necessary time period that we used within the above part named “fusion” subsequent.
If you wish to perceive how implicit alignment could be completed, learn this. On this analysis paper, the mannequin embeds fragments of photographs (objects within the picture) and fragments of sentences (typed dependency tree relations) into a typical area.

Let’s dive a little bit deeper into this.
The Idea of Fusion in Multimodal LLMs
The cornerstone of multimodal studying lies in understanding how various kinds of information could be mixed successfully. In different phrases, it serves as a option to precisely align our completely different modalities throughout a unified dimensional area. Fusion methods decide when and the way data from completely different modalities is built-in, basically shaping the mannequin’s capability to know advanced multimodal inputs.
Fusion refers back to the integration of knowledge from a number of modalities akin to textual content, picture, and audio right into a unified illustration. It performs a important function in enabling fashions to leverage complementary data from every modality. The aim is to mix options in such a manner that the mannequin could make extra knowledgeable predictions. It’s fairly much like the idea of fusion that we use in Deep Studying.
There are two broadly used methods for fusion: Early Fusion and Late Fusion.

There additionally exists a 3rd class – mid-fusion, about which I’ll clarify shortly.
1. Early Fusion
Early Fusion represents the best strategy to multimodal integration, right here the uncooked information from completely different modalities is mixed on the enter degree itself earlier than any processing happens. In early fusion programs, information from varied sources akin to pixel values from photographs and tokenized textual content are concatenated or mixed by easy operations on the very starting of the processing pipeline. This strategy permits for complete interplay between modalities from the earliest levels of computation, enabling the mannequin to seize delicate correlations and dependencies that is likely to be misplaced in later-stage fusion approaches.
- Course of: Uncooked modalities -> Function Extraction (low-level options) -> Concatenation/Easy Mixture -> Joint Processing by a single mannequin.
- Execs: It permits the mannequin to study correlations and interactions between modalities from the earliest levels. It will also be conceptually less complicated.
- Cons: It may be troublesome to implement successfully if modalities have vastly completely different buildings or scales. The mixed characteristic area can turn into very high-dimensional and unwieldy. It forces a “one-size-fits-all” processing strategy early on, which could not be optimum for every modality.
Instance: Earlier makes an attempt may contain flattening a picture and concatenating it with textual content embeddings earlier than feeding it right into a neural community. That is much less widespread in fashionable refined multimodal LLMs as a consequence of their limitations.
2. Late Fusion
Late Fusion takes the alternative strategy, processing every modality independently by specialised networks earlier than combining the outcomes on the determination degree. Right here separate neural networks course of every information kind utilizing architectures optimized for that particular modality like convolutional neural networks for photographs, or transformer architectures for textual content and VIT for photographs. The outputs from these specialised processors are then mixed utilizing strategies akin to weighted averaging, concatenation, or extra refined fusion modules.
- Course of: Modality A -> Mannequin A -> Output A; Modality B -> Mannequin B -> Output B. Then, Output A and Output B are mixed (utilizing averaging, voting, a small neural community, and so forth.).
- Execs: It permits for optimum, specialised processing of every modality utilizing fashions greatest fitted to it. It’s less complicated to implement if you have already got sturdy unimodal fashions. It’s extra strong in lacking modalities.
- Cons: It fails to seize low-level options between modalities as a result of they’re processed in isolation for too lengthy. Additionally, the fusion occurs too late to affect the characteristic studying inside every modality stream.
Instance: A picture classifier identifies objects in a picture, and a textual content classifier analyzes a caption. A separate module then combines/fuses these classifications to say if the caption precisely describes the picture.
3. Mid Fusion
Mid Fusion or intermediate fusion strikes a steadiness between early and late approaches by integrating multimodal data at varied intermediate layers of the community. This technique permits the mannequin to seize each low-level cross-modal interactions and high-level semantic relationships. Mid-fusion architectures typically make use of consideration mechanisms or specialised switch modules that enable data to circulate between modality-specific processing streams at a number of factors all through the community. The Multimodal Switch Module (MMTM) makes use of this strategy by utilizing squeeze and excitation operations to recalculate channel-wise options in every CNN stream based mostly on data from a number of modalities.
- Course of: Modality A -> Partial Processing A -> Options A; Modality B -> Partial Processing B -> Options B. Then, Options A and Options B are mixed and fed right into a joint multimodal processing community.
- Execs: It permits specialised preliminary processing whereas nonetheless enabling the mannequin to study wealthy cross-modal relationships at a deeper characteristic degree. It additionally affords extra flexibility.
- Cons: It may be extra advanced to design and practice. Discovering the optimum level and methodology of fusion could be difficult on this case.
Instance: Most fashionable vision-language fashions (like LLaVA) use this. A picture encoder processes the picture right into a set of characteristic vectors, and a textual content encoder processes the textual content into token embeddings. These are then projected and mixed in a manner that permits a central LLM to take care of each.
Core Encoder Architectures
Let’s now attempt to get an over-the-top understanding of some broadly used encoders which can be utilized within the VLMS.
If you want to study extra about varied Massive Imaginative and prescient Language mannequin architectures click on right here.
CLIP: Contrastive Language-Picture Pre-training
CLIP represents a foundational breakthrough in multimodal studying, introducing a easy but highly effective strategy to studying joint representations of photographs and textual content by contrastive pre-training. The structure consists of two separate encoders: a imaginative and prescient encoder that processes photographs and a textual content encoder that processes pure language descriptions. These encoders are educated collectively utilizing a contrastive goal that encourages the mannequin to affiliate photographs with their corresponding textual descriptions whereas distinguishing them from unrelated text-image pairs.

The coaching course of for CLIP includes presenting the mannequin with batches (for the sake of understanding the above picture let’s say n=5) of n image-caption pairs, the place every picture is paired with its appropriate textual description. The mannequin computes embeddings for all photographs and texts within the batch, creating two units of n-dimensional vectors.
The contrastive loss operate encourages excessive similarity between appropriate image-text pairs whereas penalizing excessive similarity between incorrect pairs. As we are able to visualize within the above picture the diagonal weights will probably be maximized and the remaining will probably be penalized. Mathematically, that is expressed as a symmetric cross-entropy loss over similarity scores, the place the temperature parameter controls the sharpness of the distribution.
CLIP’s effectiveness got here from its capability to study from naturally occurring image-text pairs discovered on the web (400 million scrapped data from the online), eliminating the necessity for manually annotated datasets. This strategy permits the mannequin to study wealthy semantic relationships that generalize effectively to downstream duties. The discovered representations reveal exceptional zero-shot capabilities, permitting the mannequin to carry out picture classification and retrieval duties on classes it has by no means seen throughout coaching. The success of CLIP has impressed quite a few follow-up works and established contrastive pre-training as a dominant methodology in multimodal studying.
Additionally, do take into account studying about ViT right here.
SigLIP: Sigmoid Loss for Improved Effectivity
SigLIP represents an evolution of the CLIP structure that addresses among the computational limitations of the unique contrastive strategy. Whereas CLIP requires computing similarities between all pairs of photographs and texts in a batch, SigLIP employs a pairwise sigmoid loss that operates on particular person image-text pairs independently. This modification eliminates the necessity for a worldwide view of all pairwise similarities inside a batch, enabling extra environment friendly scaling to bigger batch sizes whereas sustaining or enhancing efficiency.
The sigmoid loss operate utilized in SigLIP affords a number of benefits over the standard contrastive loss. It offers a extra steady coaching mechanism and higher efficiency with smaller batch sizes, making the strategy extra accessible with restricted computational sources. The pairwise nature of the loss permits extra versatile coaching configurations and higher dealing with of datasets with various numbers of optimistic examples per pattern.
SigLIP’s structure maintains the dual-encoder construction of CLIP however incorporates architectural enhancements and coaching optimizations that improve each effectivity and effectiveness. The mannequin makes use of separate picture and textual content encoders to generate representations for each modalities, with the sigmoid loss encouraging similarity between matched pairs and dissimilarity between unmatched pairs. This strategy has demonstrated superior efficiency throughout varied image-text duties whereas providing improved computational effectivity in comparison with conventional contrastive strategies.

RoPE: Rotary Place Embedding
Though RoPE can’t be thought of as an encoder mannequin, it positively is an embedding technique broadly utilized in giant language fashions.
Rotary Place Embedding (RoPE) represents a classy strategy to encoding positional data in transformer-based architectures. RoPE encodes absolutely the positional data utilizing rotation matrices whereas naturally together with the express relative place dependencies in self-attention formulations. This strategy offers invaluable properties together with flexibility to increase to any sequence size, decaying inter-token dependency with rising relative distances, and the aptitude to equip linear self-attention with relative place encoding.
The mathematical basis of RoPE includes making use of rotation matrices to embedding vectors based mostly on their positions within the sequence. This rotation-based strategy ensures that the dot product between embeddings captures each content material similarity and relative positional relationships. The decay property of RoPE signifies that tokens which can be farther aside within the sequence have naturally decreased consideration weights, which aligns effectively with many pure language and multimodal duties the place native context is often extra necessary than distant context.

In multimodal purposes, RoPE permits fashions to deal with variable-length sequences extra successfully, which is essential when processing multimodal information the place completely different modalities might have completely different temporal or spatial traits. The flexibility to extrapolate to longer sequences than these seen throughout coaching makes RoPE significantly invaluable for multimodal fashions that must deal with numerous enter codecs and lengths.
Case Research in Imaginative and prescient-Language Fashions
Now, let’s see how these ideas and parts come collectively in some open-sourced influential multimodal LLMs, significantly specializing in how they “see.”
1. LLaVA (Massive Language and Imaginative and prescient Assistant)
LLaVA’s core concept is to reveal {that a} remarkably easy structure can obtain spectacular visible reasoning capabilities by effectively connecting a pre-trained imaginative and prescient encoder (from CLIP) to a pre-trained Massive Language Mannequin (Vicuna) utilizing a single, trainable linear projection layer. It leverages the sturdy present capabilities of those unimodal fashions for multimodal understanding.

Coaching Course of
LLaVA makes use of pre-trained Vicuna LLM and CLIP imaginative and prescient encoder parts. The coaching is a 2-stage instruction-tuning process:
Stage 1: Visible Function Alignment (Pre-training)
- Purpose: Educate the projection layer to map visible options into the LLM’s phrase embedding area.
- Knowledge: A subset of Conceptual Captions (CC3M), containing image-caption pairs.
- Methodology: The picture is fed by the (frozen) CLIP-ViT. The output visible options are handed by the (trainable) linear projection layer. These projected visible tokens are prepended to the tokenized caption. The Vicuna LLM (frozen) is then tasked with autoregressively predicting the caption. Solely the linear projection layer’s weights are up to date.
Stage 2: Instruction High-quality-tuning (Finish-to-Finish)
- Purpose: Enhance the mannequin’s capability to observe directions and interact in advanced visible dialogue.
- Knowledge: A small, high-quality synthetically generated dataset (LLaVA-Instruct-158K) utilizing GPT-4 to create diversified questions on photographs, detailed descriptions, and complicated reasoning duties. This dataset contains – Multimodal conversations (58k), Detailed Textual content Descriptions of photographs (23k), and Complicated reasoning/advanced visible QA (77k).
- Methodology: Each the projection layer and the LLM weights are fine-tuned on this instruction dataset. The enter to the LLM is a mixture of projected picture options and a textual instruction/query.
Working
The LLaVA mannequin processes inputs which could be textual content, a picture, or a mixture. Right here’s the way it works:
- Textual content Enter: Vicuna’s native tokenizer and embedding system prepares the offered textual content (e.g. a query) for the LLM by tokenizing and embedding it.
- Picture Enter: The CLIP imaginative and prescient encoder (particularly, its Imaginative and prescient Transformer, ViT) extracts wealthy visible options from the picture. These options, sometimes representing picture patches, are a sequence of vectors.
- Projection: These visible characteristic vectors then move by the MLP Projection Layer. This layer performs a linear transformation, projecting the visible options into the identical dimensionality as Vicuna’s phrase embeddings. This makes the visible data “appear like” phrase tokens to the LLM.
- Mixed Enter to LLM: The mannequin then combines the projected visible tokens with the textual content token embeddings (e.g., by prepending the visible tokens to the textual content tokens).
- LLM Processing (Fusion & Reasoning): This mixed sequence is fed into the Vicuna LLM. The LLM’s consideration mechanisms course of each varieties of tokens concurrently. That is the place “Fusion” occurs, permitting the mannequin to correlate components of the textual content with related visible tokens. The aim is to realize Joint embedding (a shared illustration area) and Implicit Alignment (connecting visible ideas to textual ones).
- Output Technology: Primarily based on the processed mixed enter, the LLM autoregressively generates a textual response to the question or instruction.

Simplified Model
LLaVA appears to be like at a picture and creates captions for the photographs utilizing CLIP (imaginative and prescient encoder). A particular translator (projection layer) adjustments these captions right into a language the Vicuna LLM understands. The Vicuna mind then reads each the translated captions and any precise textual content phrases (like your query). Lastly, the Vicuna mind makes use of all this data to offer you a solution within the textual content.
Encoder-Decoder Structure
Whereas not a conventional encoder-decoder within the sequence-to-sequence translation sense, LLaVA makes use of parts that serve these roles:
- Imaginative and prescient Encoder: A pre-trained CLIP ViT-L/14. This mannequin takes a picture and outputs visible embeddings (options).
- Language Mannequin (acts as Decoder): Vicuna (an instruction-tuned Llama variant). It takes the visible embeddings (after projection) and textual content embeddings as enter, and autoregressive generates the textual content output.
- Connector/Projector (The “Bridge”): A single linear MLP layer. That is the important thing new part that interprets visible options from the imaginative and prescient encoder’s area to the LLM’s enter embedding area.
Strengths
- Simplicity & Effectivity: Outstanding efficiency for its comparatively easy structure and environment friendly coaching (particularly Stage 1).
- Leverages Pre-trained Fashions: Successfully makes use of the facility of sturdy, available pre-trained imaginative and prescient (CLIP) and language (Vicuna) fashions.
- Value-Efficient High-quality-tuning: The preliminary characteristic alignment stage solely trains a small projection layer, making it computationally cheaper.
- Instruction Following: The LLaVA-Instruct-158K dataset was essential for enabling sturdy conversational and instruction-following talents.
- Open Supply: Contributed considerably to open analysis in vision-language fashions.
Limitations
- Granularity (Early Variations): Unique LLaVA typically relied on a single world characteristic vector or a small sequence from the picture (e.g., [CLS] token options), which might restrict the understanding of very fine-grained particulars or advanced spatial relationships. (Later variations like LLaVA-1.5 improved this by utilizing extra patch options and an MLP projector).
- Hallucination: Can typically “hallucinate” objects or particulars not current within the picture, a typical concern with LLMs.
- Reasoning Depth: Whereas good, reasoning on very advanced scenes or summary visible ideas is likely to be restricted in comparison with bigger, extra extensively educated fashions.
- Dataset Dependency: Efficiency is closely influenced by the standard and nature of the instruction-tuning dataset.
2. Llama 3 Imaginative and prescient (Llama 3.1 Imaginative and prescient 8B / 70B)
Llama 3 Imaginative and prescient goals to construct state-of-the-art open-source multimodal fashions by integrating a strong imaginative and prescient encoder with the sturdy base of Llama 3 LLMs. The core concept is to leverage Meta’s developments in LLMs, imaginative and prescient fashions, and large-scale coaching methodologies to create fashions that may carry out advanced visible reasoning, perceive nuanced visible particulars, and observe intricate directions involving photographs and textual content.
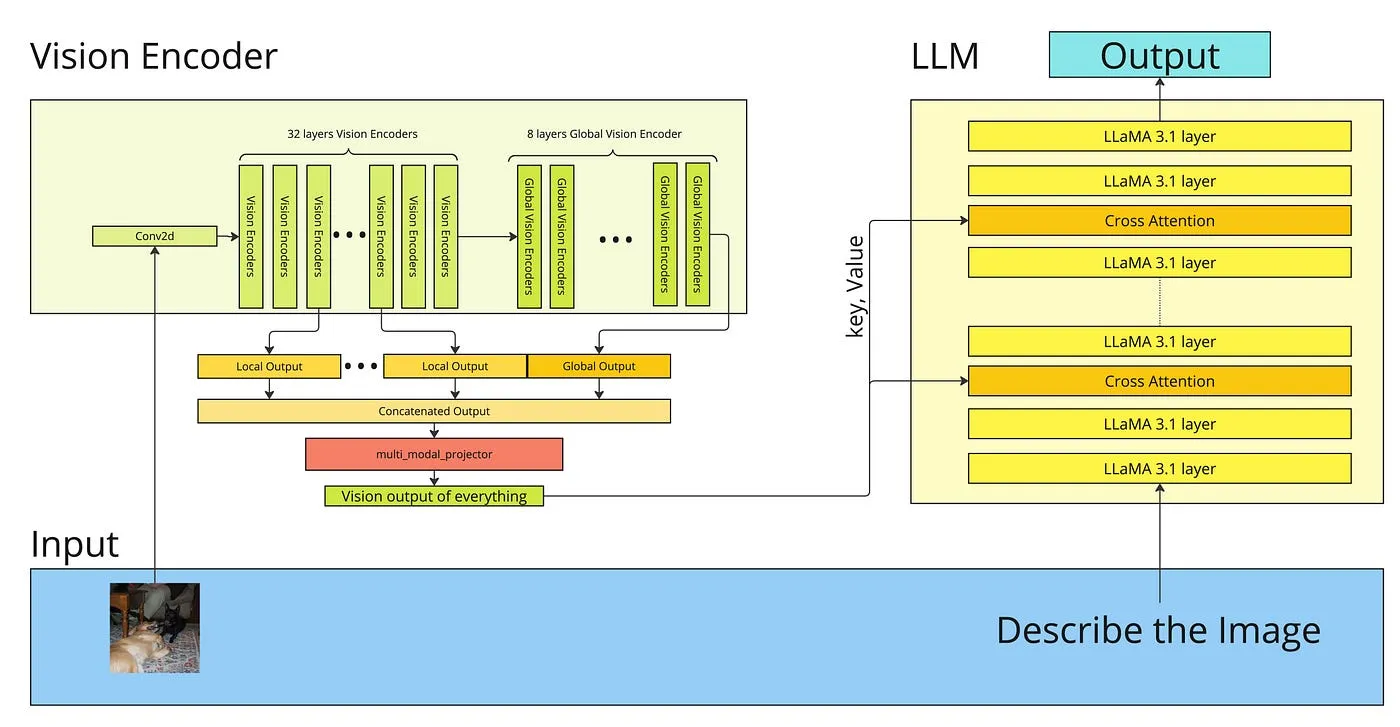
Coaching Course of
Llama 3 Imaginative and prescient fashions leverage pre-trained Llama 3 LLMs and highly effective pre-trained imaginative and prescient encoders (e.g., CLIP ViT). The coaching technique sometimes includes:
Stage 1: Massive-Scale Multimodal Pre-training
- Purpose: Educate the mannequin basic visible ideas and their deep alignment with language at an enormous scale.
- Knowledge: Billions of image-text pairs from numerous sources (e.g., publicly accessible net information, licensed datasets). Meta has entry to huge (anonymized and privacy-preserving) image-text information.
- Methodology: The imaginative and prescient encoder, a projector module (e.g., a two-layer MLP), and the Llama 3 LLM are educated collectively. The mannequin learns to foretell textual content related to photographs or masked parts of textual content/photographs. This stage trains the projector and fine-tunes each the imaginative and prescient encoder and the LLM for multimodal understanding.
Stage 2: Instruction High-quality-tuning (Finish-to-Finish)
- Purpose: Improve the mannequin’s capability to observe numerous directions, interact in dialogue, and carry out particular multimodal duties.
- Knowledge: A curated mixture of high-quality multimodal instruction-following datasets. This contains Visible Query Answering (VQA), picture captioning, visible reasoning, object grounding, Optical Character Recognition (OCR) in photographs, chart/diagram understanding, and so forth.
- Methodology: Your entire mannequin (or important components of it) is fine-tuned on these instruction datasets to enhance its helpfulness, security, and task-specific efficiency.
- Scaling: Meta emphasizes scaling legal guidelines, which means Llama 3 Imaginative and prescient advantages from scaling up the LLM measurement (e.g., 8B to 70B), the imaginative and prescient encoder measurement, and the coaching information quantity and high quality.

Working
Llama 3 Imaginative and prescient processes picture and textual content inputs to generate textual outputs.
- Textual content Enter: Textual content (e.g., questions, directions) is tokenized utilizing Llama 3’s superior tokenizer (e.g., 128k vocabulary) and transformed into token embeddings.
- Picture Enter: The enter picture is preprocessed (e.g., scaled to a decision like 448×448 for Llama 3.1 Imaginative and prescient). It’s then fed into a strong imaginative and prescient encoder (e.g., a CLIP ViT mannequin). The imaginative and prescient encoder processes the picture and outputs a sequence of visible embeddings, representing quite a few picture patches (e.g., Llama 3.1 Imaginative and prescient produces 144 visible tokens from a CLIP ViT-L/14).
- Projection: These visible embeddings are handed by a projector module, sometimes a multi-layer perceptron (e.g., a two-layer MLP in Llama 3.1 Imaginative and prescient). The projector transforms these visible options into embeddings which can be appropriate with the Llama 3 LLM’s enter area.
- Mixed Enter to LLM: The projected visible tokens are mixed with the textual content token embeddings. Particular picture tokens is likely to be used to demarcate visible data inside the sequence.
- LLM Processing (Fusion & Reasoning): The Llama 3 LLM processes this interleaved sequence of visible and textual tokens. Its refined consideration mechanisms (Grouped Question Consideration for effectivity with lengthy sequences) enable it to deeply combine and correlate data from each modalities. This allows Joint embedding and Implicit Alignment at a really fine-grained degree.
- Output Technology: The LLM leverages its huge pre-trained data, detailed visible data, and the textual context to carry out reasoning and generate a coherent and related textual response.
Simplified Model
Llama 3 Imaginative and prescient makes use of a really sharp ViT variant mannequin to take a look at a picture, breaking it down into many detailed image phrases(patch information). A projector makes these detailed picture captions prepared for the super-smart Llama 3 LLM. The Llama 3 mind reads these captions together with any textual content questions you ask it. As a result of the Llama 3 mind is so large and well-trained, it might probably perceive advanced issues within the image and provide you with very detailed and clever solutions within the textual content.
Encoder-Decoder Structure
Just like LLaVA, it’s a imaginative and prescient encoder + projector + LLM structure:
- Imaginative and prescient Encoder: A robust, pre-trained Imaginative and prescient Transformer. For Llama 3.1 Imaginative and prescient, it is a CLIP ViT mannequin, probably a big variant.
- Language Mannequin (acts as a Decoder): The Llama 3 mannequin (e.g., Llama 3 8B or Llama 3 70B), which is an autoregressive decoder.
- Connector/Projector: A learnable module, sometimes an MLP (e.g., a two-layer MLP for Llama 3.1 Imaginative and prescient) to map the sequences of visible options from the ViT output into the LLM’s enter embedding area.

Strengths
- State-of-the-Artwork Efficiency: Goals for top-tier efficiency on a variety of vision-language benchmarks as a consequence of scale and superior coaching.
- Scale: Advantages from giant base LLMs (Llama 3 8B, 70B), highly effective imaginative and prescient encoders, and large coaching datasets.
- Robust Base LLM: Constructed upon the extremely succesful Llama 3 fashions recognized for wonderful textual content technology and reasoning.
- Improved Reasoning & Decreased Hallucination: Intensive pre-training and fine-tuning on high-quality, numerous information assist enhance reasoning and scale back the tendency to hallucinate.
- Superior Capabilities: Reveals sturdy efficiency in areas like OCR, understanding charts/graphs, and fine-grained visible element recognition.
- Architectural Refinements: Leverages LLM developments like Grouped Question Consideration (GQA) for environment friendly dealing with of lengthy sequences (together with visible tokens).
Limitations
- Computational Value: Bigger fashions (like 70B) require important computational sources for coaching and inference.
- Knowledge Dependency & Bias: Efficiency and potential biases are nonetheless depending on the huge datasets used for coaching. Making certain equity and mitigating dangerous biases is an ongoing problem.
- Hallucination: Whereas decreased, the danger of producing believable however incorrect data (hallucination) persists, particularly for out-of-distribution or extremely ambiguous inputs.
- Complexity: The elevated scale and complexity could make debugging, interpretation, and fine-tuning more difficult for end-users in comparison with less complicated fashions.
Developments in Llama 4
Whereas particular, verified particulars for Llama 4 are nonetheless rising, discussions round its developments typically middle on tackling the inherent challenges of large-scale multimodal studying, significantly by architectural improvements like Combination-of-Specialists (MoE).

1. Addressing Computational Complexity and Scalability with MoE
A key conceptual development for Llama 4 is the efficient implementation of MoE. This structure considerably mitigates computational prices by activating solely a related skilled. This enables for enhancing mannequin capability whereas retaining the computational load for coaching and inference manageable.
Such effectivity is essential for dealing with more and more giant, high-resolution multimodal datasets and lengthy sequence lengths, which might in any other case be bottlenecked by the quadratic scaling of conventional consideration mechanisms. This additionally permits broader scalability options, permitting the mannequin to study from extra intensive and numerous information.
2. Improved Alignment of Heterogeneous Knowledge
With the capability afforded by MoE and developments in coaching methods, Llama 4 would purpose for a extra refined alignment of numerous modalities like photographs and textual content. This includes growing extra strong representations that may seize modality-specific traits (e.g., spatial correlations in imaginative and prescient, semantic guidelines in textual content) whereas enabling deeper cross-modal understanding and interplay.
Llama4 structure additionally mentions using the Early Fusion mechanism to align the embeddings right into a unified illustration area. Whereas not its main function, the elevated capability and specialization inside an MoE framework might not directly assist in higher dealing with statistical and even temporal discrepancies between modalities if educated on acceptable information.
3. Enhanced Robustness and Bias Mitigation
Fashions like Llama 4 are anticipated to include extra superior methods to deal with inherited biases and enhance total robustness. Llama 4 would purpose to:
- Implement extra complete bias mitigation strategies throughout pre-training and fine-tuning to scale back the amplification of biases by cross-modal interactions.
- Construct higher resilience to enter high quality variations, out-of-distribution information, and adversarial assaults which may exploit cross-modal vulnerabilities. The aim is to realize extra dependable and safe efficiency throughout a wider vary of real-world situations.
Conclusion
The evolution of multimodal LLMs represents probably the most important advances in synthetic intelligence, basically altering how machines understand and work together with the world round us. From the foundational ideas of early and late fusion to the delicate architectures of contemporary programs like Llama 4, we have now traced the technical journey that has enabled AI programs to know and course of a number of modalities with human-like sophistication. The technical foundations we explored together with contrastive studying ideas, joint embedding areas, and alignment mechanisms present the theoretical framework that makes multimodal understanding attainable.
Our case research of LLaVA, Llama 3.2 Imaginative and prescient, and Llama 4 illustrate the speedy development of multimodal capabilities. LLaVA demonstrated that elegant simplicity might obtain exceptional outcomes by visible instruction tuning. Llama 3.2 Imaginative and prescient confirmed how refined cross-attention mechanisms might allow strong multimodal reasoning. Llama 4 represents the present state-of-the-art, introducing mixture-of-experts architectures and unprecedented context lengths that open solely new classes of purposes. Within the second a part of this collection, we’ll discover how these Multimodal LLMs are in a position to perceive audio.
GenAI Intern @ Analytics Vidhya | Closing 12 months @ VIT Chennai
Keen about AI and machine studying, I am desperate to dive into roles as an AI/ML Engineer or Knowledge Scientist the place I could make an actual affect. With a knack for fast studying and a love for teamwork, I am excited to deliver progressive options and cutting-edge developments to the desk. My curiosity drives me to discover AI throughout varied fields and take the initiative to delve into information engineering, making certain I keep forward and ship impactful tasks.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}