

(Anoohani/Shutterstock)
The sector of software program engineering has benefited immensely from new methods and applied sciences, corresponding to DevOps by way of Git, and steady integration/steady deployment (CI/CD) by way of instruments like Jenkins,. Now an organization referred to as Recce is hoping to convey the identical kind of advantages to the sector of knowledge engineering with an open supply product by the identical identify, in addition to a business product.
The aim of the Recce (brief for “reconnaissance”) challenge is to convey the identical kind of finest practices for information validation workflows–corresponding to information diffing, validation checklists, and question outcome comparability–straight into the info transformation workflows. The software program does this by integrating straight with instruments like dbt, thereby enabling information engineers and different information professionals to make sure that the cleanest and finest information is getting used for downstream analytics use instances in information warehouses, information lakes, and lakehouses.
Information engineers and different practitioners (dbt Labs likes to name them “analytics engineers”) are already doing checks, corresponding to in search of null values and to make sure the ranges or referential integrity is maintained. Recce helps to automate these checks and supply a foundation for added verification, says Chia-liang “CL” Kao, the creator of Recce and the CEO of the corporate by the identical identify.
“In different phrases, they’re doing a number of spot checks, like working this particular question for the manufacturing database and your improvement department, sort of staging information, after which eyeballing the outcomes,” Kao tells BigDATAwire. “Oftentimes, it’s very guide. So we’re automating that course of, permitting the practitioner to usher in the enterprise stakeholders earlier to take a look at the info.”

CL Kao, the creator of Recce and SVK
By automating the checks that dbt is already doing and making the outcomes simpler to devour by way of a graphical consumer interface (GUI), the outcomes shall be consumable by a broader vary of personas and due to this fact have a wider impression on the enterprise, says Kao, the previous Apple engineer who developed SVK, the precursor to Git.
It’s all about serving to the info high quality checks make sense for the customers’ specific atmosphere, Kao says.
“So by studying the output of the comparability, just like the variations or the aggregation of the variations, they’re capable of create a guidelines to say, ‘Hey, I’ve checked out this question. I meant this to be X and it’s certainly X,’” he says. “That is how they presently go about making the verification themselves, however it’s finished manually. So we’re serving to them to automate that course of right into a dependable approach, in order that once you add extra commits to your pull request, these checks will be robotically rerun and reverified, in order that they’re not misplaced within the void.”
Kao has focused dbt with the primary launch of Recce as a result of dbt is so broadly utilized by information engineers and different information professionals. The plan requires Recce finally to assist different common information instruments, corresponding to SQLMesh, Dagster, and others, he says.
The aim is to make sure the standard and integrity of knowledge as far up the info provide chain as doable, Kao says. The sector of knowledge observability is fixing an identical drawback, however it’s principally information after it has been loaded into an analytics database or warehouse and has undergone the all-important transformations–the “T” in ETL and ELT–which is the place many errors are launched.
The introduction of AI, each as an utility and as an information engineering software, makes it all of the extra important to resolve information high quality points as early as doable within the information lifecycle, Kao says. As information turns into extra important for software program improvement, the info assessment will develop into as necessary–if no more necessary–than the code assessment for Python, SQL, or different code.![]()
“Now the immediate or the underlying mannequin is a constructing block that you simply’re utilizing as a part of the pipeline. Now you’re altering the logic of the pipeline. You have got this sort of sudden impression to your downstream. How do you confirm that?” says Kao, who can also be the CEO of Recce. “We’re counting on sure eval or one thing for our purposes. However finally I feel the long run is like code assessment. As we do in software program, after we are doing this new kind of LLM-driven code [development], it’s going to be information assessment.”
Nevertheless, software program can solely take us up to now. People are a important hyperlink within the information assessment course of, as a result of computer systems can’t validate whether or not the last word values are right or not, Kao says. Context is important for figuring out the correctness of knowledge, he says. That’s why Recce is searching for to streamline as a lot of the method as doable and take away impediments to getting this data in entrance of human eyes.
“The main distinction from software program CI/CD is that the correctness will depend on the interpretation of the drift, like in comparison with the manufacturing system,” Kao says. “And that wasn’t often finished as a result of it was very involving. However after we talked to extra mature groups, they must spend time on that to make sure the output for the info is right. So what Recce brings is actually simplifying that workflow after which additionally integrating it into the CI/CD system.”
Throughout a demo of a dbt pull request in Recce, Kao confirmed how a consumer is ready to visually decide how adjustments to a sure database area will impression downstream tables. It’s a real-time cross-referencing functionality that can let customers, for example, see how a coupon change will impression how buyer lifetime worth is calculated, Kao says.
“You possibly can see after I alter that coupon definition, how is my buyer lifetime worth throughout the client altering?” he says. “Is the distribution change one thing I anticipated?”
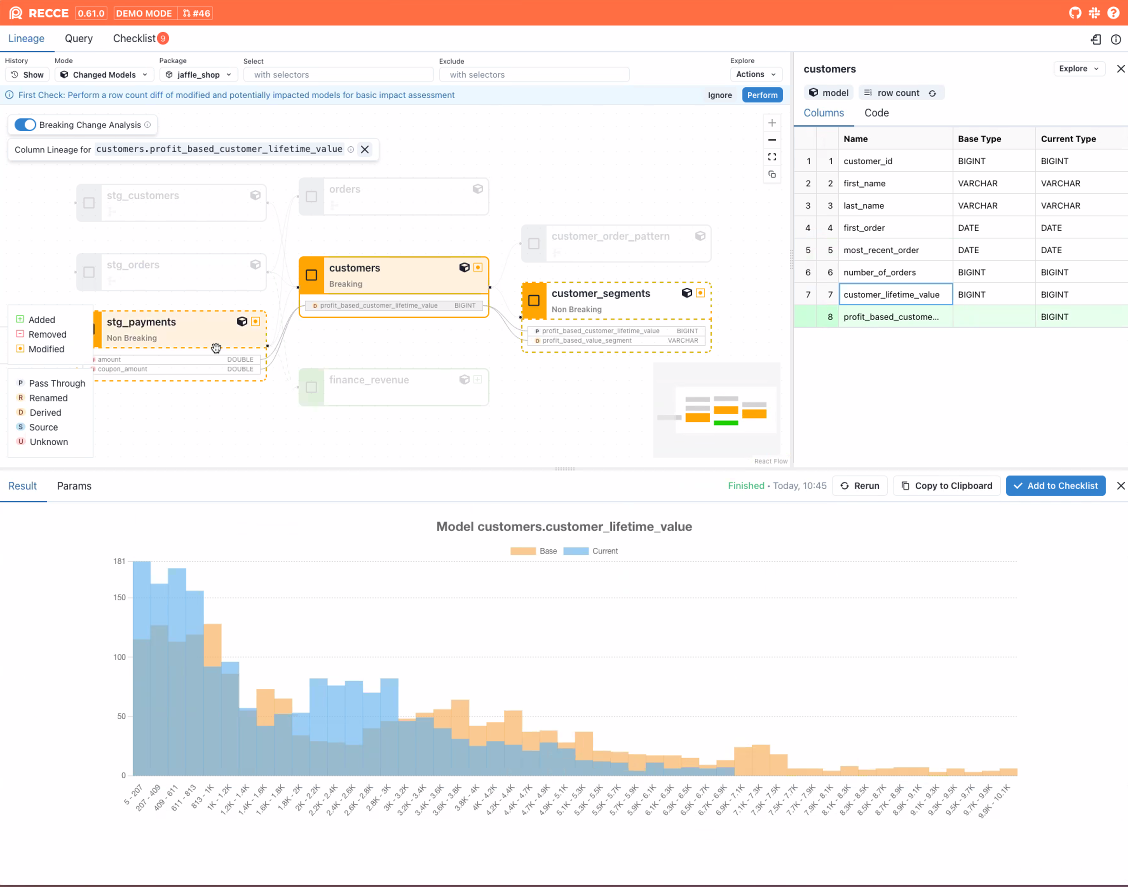
Recce permits customers to see how a change to a single file can negatively impression downstream tables
The primary launch of Recce got here out a couple of yr in the past, and right now it’s being downloaded about 3,000 instances per week, Kao says. Anybody can obtain Recce and run an area Recce server.
Yesterday, Recce introduced the model 1.0 launch of the product, which provides a number of recent options, together with assist for column-level lineage; breaking change evaluation; profile, worth, and High-Ok diff to the column; interactive customized queries, and structured checklists and proof assortment.
The corporate additionally introduced the launch of Recce Cloud. At the moment in beta, the service offers extra collaboration performance for groups than what is obtainable within the open supply product, together with: full data-validation context sharing with groups, together with lineage diffs, customized question outcomes, and structured checklists, and automatic sync checks throughout environments and blocked merging till all checks are authorized.
Lastly, the San Francisco-based firm introduced that it has raised $4 million in enterprise capital to gasoline its progress. The spherical was led by Heavybit, with participation from Vertex Ventures US, Hive Ventures, and angels Visionary, SVT Angels, Brighter Capital, Ventek Ventures, Scott Breitenother and Tim Chen of Essence VC.
“Information pipelines are the New Secret Sauce for each firm constructing with AI, enabling groups to create and enhance high-quality coaching information from their very own IP,” mentioned Heavybit Basic Companion Jesse Robbins, who’s becoming a member of Recce’s board. “Recce offers the important toolkit for unlocking the total worth of their information with iteration, refinement, and monitoring, whereas mitigating the chance of errors and corruption. Heavybit is thrilled to assist them as they develop the ecosystem for information pipeline validation within the age of AI as a part of our ongoing mission of 10+ years: Bringing important enterprise infrastructure to market.”
Associated Objects:
Information High quality Getting Worse, Report Says
Information High quality High Impediment to GenAI, Informatica Survey Says
Information High quality Acquired You Down? Thank GenAI

{kind=link}