
Have you ever ever requested an LLM a query, modified the wording a number of instances, and nonetheless felt the reply wasn’t fairly proper? In case you’ve labored with instruments like ChatGPT or Gemini, you’ve most likely rewritten prompts, added extra context, or used phrases like “be concise” or “suppose step-by-step” to enhance outcomes. However what if bettering accuracy was so simple as copying your total immediate and pasting it once more? That’s the thought behind immediate repetition. It might sound too easy to matter, however analysis reveals that giving the mannequin your query twice can considerably enhance accuracy on many duties, making it one of many best efficiency boosts you possibly can attempt.
What Is Immediate Repetition and Why Attempt It?
To grasp why repetition helps, we have to take a look at how LLMs course of textual content. Most massive language fashions are educated in a causal approach. They predict tokens one after the other, and every token can solely attend to the tokens that got here earlier than it. This implies the order of data in your immediate can affect the mannequin’s understanding.
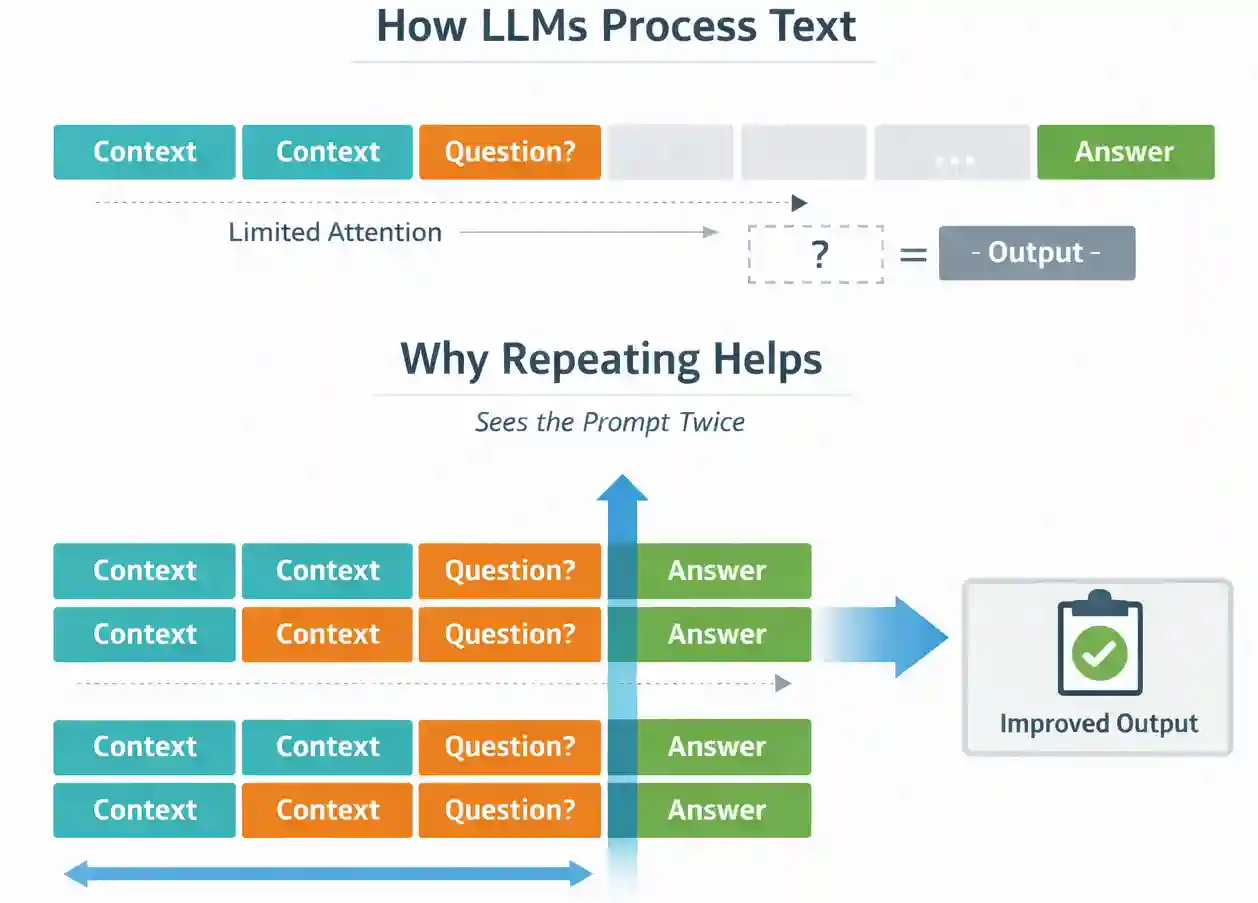
Immediate repetition helps cut back this ordering impact. Once you duplicate the immediate, each token will get one other alternative to take care of all related data. As an alternative of seeing the context as soon as, the mannequin successfully processes it twice through the enter (prefill) stage.
Importantly, this occurs earlier than the mannequin begins producing a solution. The output format doesn’t change, and the mannequin doesn’t generate additional tokens. You’re merely bettering how the mannequin processes the enter.
Additionally Learn: Immediate Engineering Information 2026
Immediate Repetition in Motion
The examine evaluated immediate repetition throughout 7 totally different duties utilizing 7 LLMs. These weren’t small experimental fashions. They included extensively used fashions equivalent to Gemini, GPT-4o, Claude, and DeepSeek, accessed via their official APIs. The seven duties consisted of:
5 customary benchmarks:
- ARC (science reasoning questions)
- OpenBookQA
- GSM8K (math phrase issues)
- MMLU-Professional (multi-domain data)
- MATH
Two custom-designed duties:
The {custom} duties have been particularly designed to check how effectively fashions deal with structured and positional data.
For every activity, the researchers in contrast two setups:
- The baseline immediate
- The very same immediate repeated twice
Nothing else was modified. The output format remained the identical. The mannequin was not fine-tuned. The one distinction was that the enter was duplicated.
They then measured:
- Accuracy
- Output size
- Latency
Information to AI Benchmarks that cowl all the things MMLU, HumanEval, and Extra Defined
Results of the Immediate Repetition Experiment
Throughout seventy whole comparisons masking totally different fashions and benchmarks, immediate repetition improved accuracy forty-seven instances. It by no means considerably decreased efficiency. The enhancements have been particularly noticeable in multiple-choice codecs and in structured duties the place the mannequin wanted to rigorously observe positional data.
Instance from the Paper: The NameIndex Job
Within the NameIndex activity, the mannequin is given a listing of fifty names and requested a direct query: “What’s the twenty fifth identify?” The duty doesn’t require reasoning or interpretation. It solely requires correct positional monitoring inside a listing.
Within the baseline setting, efficiency was low. For instance, Gemini 2.0 Flash Lite achieved 21.33% accuracy. After making use of immediate repetition, accuracy elevated to 97.33%. This can be a main enchancment in reliability.
Listing indexing requires the mannequin to accurately encode sequence and place. When the immediate seems as soon as, the mannequin processes the checklist and query in a single move. Some positional relationships might not be strongly bolstered. When the complete checklist and query are repeated, the mannequin successfully processes the construction twice earlier than answering. This strengthens its inner illustration of ordering.
However What About Latency and Token Prices?
Each time we enhance accuracy, the following query is apparent: What does it value? Surprisingly, virtually nothing.
These figures examine:
- Accuracy
- Common response size
- Median response size
- Latency
The important thing discovering:
- Immediate repetition doesn’t improve output token size.
- The mannequin doesn’t generate longer solutions.
- Latency additionally stays roughly the identical, besides in very lengthy immediate situations (significantly with Anthropic fashions), the place the prefill stage takes barely longer.
This issues in manufacturing methods.
Not like chain-of-thought prompting, which will increase token era and value, immediate repetition shifts computation to the prefill stage, which is parallelizable.
In real-world purposes:
- Your value per request doesn’t spike
- Your response format stays similar
- Your downstream parsing logic stays intact
This makes it extraordinarily deployment-friendly.
When Does Immediate Repetition Work Greatest?
Immediate repetition doesn’t magically repair each downside. The analysis reveals that it’s handiest in non-reasoning duties, particularly when the mannequin should rigorously course of structured or ordered data.
It tends to work greatest in situations equivalent to:
- A number of-choice query answering
- Duties involving lengthy context adopted by a brief query
- Listing indexing or retrieval issues
- Structured information extraction
- Classification duties with clearly outlined labels
The enhancements are significantly noticeable when the mannequin should accurately observe positions or relationships inside structured inputs. Repeating the immediate reinforces these relationships.
Nevertheless, when express reasoning is enabled, equivalent to prompting the mannequin to “suppose step-by-step,” the advantages develop into smaller. In these instances, the mannequin typically restates or reprocesses components of the query throughout reasoning anyway. Repetition nonetheless doesn’t harm efficiency, however the enchancment is often impartial quite than dramatic.
The important thing takeaway is easy. In case your activity doesn’t require lengthy chain-of-thought reasoning, immediate repetition is probably going value testing.
The way to Implement Immediate Repetition in Observe
The implementation is easy. You do not want particular tooling or mannequin adjustments. You merely duplicate the enter string earlier than sending it to the mannequin.
As an alternative of sending:
immediate = questionYou ship:
immediate = question + "n" + questionThat’s the total change.
There are a number of sensible issues. First, guarantee your immediate size doesn’t exceed the mannequin’s context window. Doubling a really lengthy immediate could push you near the restrict. Second, take a look at the change in your particular activity. Whereas the analysis reveals constant positive aspects, each manufacturing system has its personal traits.
The good thing about this strategy is that nothing else in your system wants to alter. Your output format stays the identical. Your parsing logic stays the identical. Your analysis pipeline stays the identical. This makes it simple to experiment with out threat.
Immediate Repetition vs. Chain-of-Thought Prompting
You will need to perceive how immediate repetition differs from chain-of-thought prompting.
Chain-of-thought prompting encourages the mannequin to clarify its reasoning step-by-step. This typically improves efficiency on math and logic-heavy duties, but it surely will increase output size and token utilization. It additionally adjustments the construction of the response.
Immediate repetition does one thing totally different. It doesn’t change the output type. It doesn’t ask the mannequin to motive aloud. As an alternative, it strengthens how the enter is encoded earlier than era begins.
Within the experiments, when reasoning prompts have been used, repetition produced principally impartial outcomes. That is sensible. If the mannequin is already revisiting the query throughout its reasoning course of, duplicating the immediate provides little new data.
For duties that require detailed reasoning, chain-of-thought should still be helpful. For structured or classification-style duties the place you want concise solutions, immediate repetition presents an easier and cheaper enchancment.
Sensible Takeaways for Engineers
If you’re constructing LLM-powered methods, here’s what this analysis suggests:
- Take a look at immediate repetition on non-reasoning duties.
- Prioritize structured or position-sensitive workflows.
- Measure accuracy earlier than and after the change.
- Monitor context size to keep away from hitting token limits.
As a result of this methodology doesn’t change output formatting or considerably improve latency, it’s protected to check in staging environments. In lots of instances, it will possibly enhance robustness with out architectural adjustments or fine-tuning.
In manufacturing methods the place small enhancements in accuracy translate into measurable enterprise affect, even a number of proportion factors can matter. In some structured duties, the positive aspects are a lot bigger.
Additionally Learn:
Conclusion
Immediate engineering typically appears like trial and error. We alter phrasing, add constraints, and experiment with totally different directions. The concept that merely repeating your complete immediate can enhance accuracy could sound trivial, however the experimental proof suggests in any other case.
Throughout a number of fashions and 7 totally different duties, immediate repetition persistently improved efficiency with out rising output size or considerably affecting latency. The strategy is straightforward to implement, doesn’t require retraining, and doesn’t alter response formatting.
Attempt it out your self and let me know your take within the remark part.
Discover all particulars right here: Immediate Repetition Improves Non-Reasoning LLMs Analysis Paper
Hi there, I’m Nitika, a tech-savvy Content material Creator and Marketer. Creativity and studying new issues come naturally to me. I’ve experience in creating result-driven content material methods. I’m effectively versed in search engine optimisation Administration, Key phrase Operations, Internet Content material Writing, Communication, Content material Technique, Modifying, and Writing.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}