
Swap in one other LLM
There are a number of methods to run the identical process with a special mannequin. First, create a brand new chat object with that completely different mannequin. Right here’s the code for trying out Google Gemini 3 Flash Preview:
my_chat_gemini Then you possibly can run the duty in certainly one of 3 ways.
1. Clone an present process and add the chat as its solver with $set_solver():
my_task_gemini 2. Clone an present process and add the brand new chat as a solver if you run it:
my_task_gemini 3. Create a brand new process from scratch, which lets you embody a brand new identify:
my_task_gemini Be sure to’ve set your API key for every supplier you wish to take a look at, until you’re utilizing a platform that doesn’t want them, resembling native LLMs with ollama.
View a number of process runs
When you’ve run a number of duties with completely different fashions, you should utilize the vitals_bind() operate to mix the outcomes:
both_tasks 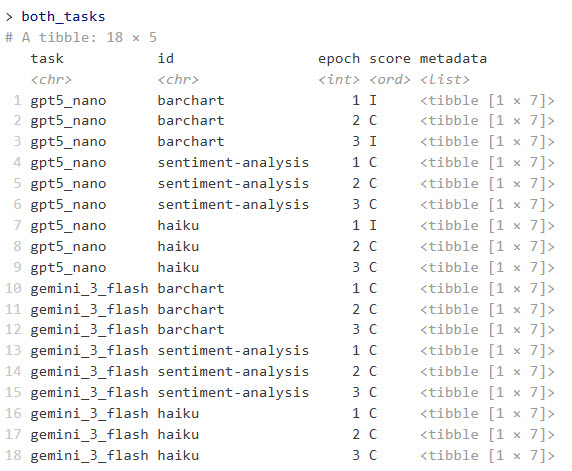
Instance of mixed process outcomes operating every LLM with three epochs.
Sharon Machlis
This returns an R knowledge body with columns for process, id, epoch, rating, and metadata. The metadata column accommodates a knowledge body in every row with columns for enter, goal, consequence, solver_chat, scorer_chat, scorer_metadata, and scorer.
To flatten the enter, goal, and consequence columns and make them simpler to scan and analyze, I un-nested the metadata column with:
library(tidyr)
both_tasks_wide
unnest_longer(metadata) |>
unnest_wider(metadata)I used to be then in a position to run a fast script to cycle by way of every bar-chart consequence code and see what it produced:
library(dplyr)
# Some outcomes are surrounded by markdown and that markdown code must be eliminated or the R code will not run
extract_code
filter(id == "barchart")
# Loop by way of every consequence
for (i in seq_len(nrow(barchart_results))) {
code_to_run Check native LLMs
That is certainly one of my favourite use instances for vitals. Presently, fashions that match into my PC’s 12GB of GPU RAM are slightly restricted. However I’m hopeful that small fashions will quickly be helpful for extra duties I’d love to do domestically with delicate knowledge. Vitals makes it simple for me to check new LLMs on a few of my particular use instances.
vitals (through ellmer) helps ollama, a preferred approach of operating LLMs domestically. To make use of ollama, obtain, set up, and run the ollama utility, and both use the desktop app or a terminal window to run it. The syntax is ollama pull to obtain an LLM, or ollama run to each obtain and begin a chat in case you’d like to ensure the mannequin works in your system. For instance: ollama pull ministral-3:14b.
The rollama R bundle allows you to obtain a neighborhood LLM for ollama inside R, so long as ollama is operating. The syntax is rollama::pull_model("model-name"). For instance, rollama::pull_model("ministral-3:14b"). You may take a look at whether or not R can see ollama operating in your system with rollama::ping_ollama().
I additionally pulled Google’s gemma3-12b and Microsoft’s phi4, then created duties for every of them with the identical dataset I used earlier than. Be aware that as of this writing, you want the dev model of vitals to deal with LLM names that embody colons (the following CRAN model after 0.2.0 ought to deal with that, although):
# Create chat objects
ministral_chat All three native LLMs nailed the sentiment evaluation, and all did poorly on the bar chart. Some code produced bar charts however not with axes flipped and sorted in descending order; different code didn’t work in any respect.

Outcomes of 1 run of my dataset with 5 native LLMs.
Sharon Machlis
R code for the outcomes desk above:
library(dplyr)
library(gt)
library(scales)
# Put together the information
plot_data
rename(LLM = process, process = id) |>
group_by(LLM, process) |>
summarize(
pct_correct = imply(rating == "C") * 100,
.teams = "drop"
)
color_fn
tidyr::pivot_wider(names_from = process, values_from = pct_correct) |>
gt() |>
tab_header(title = "% Appropriate") |>
cols_label(`sentiment-analysis` = html("sentiment-
evaluation")) |>
data_color(
columns = -LLM,
fn = color_fn
)It value me 39 cents for Opus to guage these native LLM runs—not a foul cut price.
Extract structured knowledge from textual content
Vitals has a particular operate for extracting structured knowledge from plain textual content: generate_structured(). It requires each a chat object and an outlined knowledge kind you need the LLM to return. As of this writing, you want the event model of vitals to make use of the generate_structured() operate.
First, right here’s my new dataset to extract matter, speaker identify and affiliation, date, and begin time from a plain-text description. The extra complicated model asks the LLM to transform the time zone to Jap Time from Central European Time:
extract_dataset R Package deal Improvement in PositronrnThursday, January fifteenth, 18:00 - 20:00 CET (Rome, Berlin, Paris timezone) rnStephen D. Turner is an affiliate professor of knowledge science on the College of Virginia Faculty of Knowledge Science. Previous to re-joining UVA he was a knowledge scientist in nationwide safety and protection consulting, and later at a biotech firm (Colossal, the de-extinction firm) the place he constructed and deployed scores of R packages.",
"Extract the workshop matter, speaker identify, speaker affiliation, date in 'yyyy-mm-dd' format, and begin time in Jap Time zone in 'hh:mm ET' format from the textual content under. (TZ is the time zone). Assume the date yr makes essentially the most sense on condition that at present's date is February 7, 2026. Return ONLY these entities within the format {matter}, {speaker identify}, {date}, {start_time}. Convert the given time to Jap Time if required. R Package deal Improvement in PositronrnThursday, January fifteenth, 18:00 - 20:00 CET (Rome, Berlin, Paris timezone) rnStephen D. Turner is an affiliate professor of knowledge science on the College of Virginia Faculty of Knowledge Science. Previous to re-joining UVA he was a knowledge scientist in nationwide safety and protection consulting, and later at a biotech firm (Colossal, the de-extinction firm) the place he constructed and deployed scores of R packages. "
),
goal = c(
"R Package deal Improvement in Positron, Stephen D. Turner, College of Virginia (or College of Virginia Faculty of Knowledge Science), 2026-01-15, 18:00. OR R Package deal Improvement in Positron, Stephen D. Turner, College of Virginia (or College of Virginia Faculty of Knowledge Science), 2026-01-15, 18:00 CET.",
"R Package deal Improvement in Positron, Stephen D. Turner, College of Virginia (or College of Virginia Faculty of Knowledge Science), 2026-01-15, 12:00 ET."
)
)Beneath is an instance of the way to outline a knowledge construction utilizing ellmer’s type_object() operate. Every of the arguments provides the identify of a knowledge subject and its kind (string, integer, and so forth). I’m specifying I wish to extract a workshop_topic, speaker_name, current_speaker_affiliation, date (as a string), and start_time (additionally as a string):
my_object Subsequent, I’ll use the chat objects I created earlier in a brand new structured knowledge process, utilizing Sonnet because the choose since grading is easy:
my_task_structured It value me 16 cents for Sonnet to guage 15 analysis runs of two queries and outcomes every.
Listed here are the outcomes:
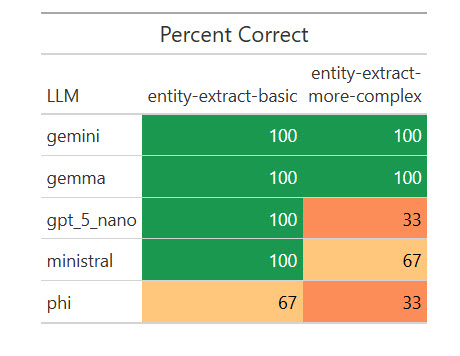
How numerous LLMs fared on extracting structured knowledge from textual content.
Sharon Machlis
I used to be shocked {that a} native mannequin, Gemma, scored 100%. I needed to see if that was a fluke, so I ran the eval one other 17 occasions for a complete of 20. Weirdly, it missed on two of the 20 primary extractions by giving the title as “R Package deal Improvement” as a substitute of “R Package deal Improvement in Positron,” however scored 100% on the extra complicated ones. I requested Claude Opus about that, and it stated my “simpler” process was extra ambiguous for a much less succesful mannequin to grasp. Necessary takeaway: Be as particular as potential in your directions!
Nonetheless, Gemma’s outcomes have been adequate on this process for me to think about testing it on some real-world entity extraction duties. And I wouldn’t have identified that with out operating automated evaluations on a number of native LLMs.
Conclusion
For those who’re used to writing code that provides predictable, repeatable responses, a script that generates completely different solutions every time it runs can really feel unsettling. Whereas there aren’t any ensures in relation to predicting an LLM’s subsequent response, evals can enhance your confidence in your code by letting you run structured exams with measurable responses, as a substitute of testing through guide, ad-hoc queries. And, because the mannequin panorama retains evolving, you possibly can keep present by testing how newer LLMs carry out—not on generic benchmarks, however on the duties that matter most to you.

{kind=link}