
Simply 3 months after the discharge of their state-of-the-art mannequin Gemini 3 Professional, Google DeepMind is right here with its newest iteration: Gemini 3.1 Professional.
A radical improve by way of capabilities and security, Gemini 3.1 Professional mannequin strives to be accessible and operable by all. No matter your desire, platform, buying energy, the mannequin has quite a bit to supply for all of the customers.
I’d be testing the capabilities of Gemini 3.1 Professional and would elaborate on its key options. From learn how to entry Gemini 3.1 Professional to benchmarks, all issues about this new mannequin has been touched upon on this article.
Gemini 3.1 Professional: What’s new?
Gemini 3.1 Professional is the most recent member of the Gemini mannequin household. As common the mannequin comes with an astounding variety of options and enhancements from the previous. A few of the most noticeable one are:
- 1 Million Context Window: Maintains the industry-leading 1 million token enter capability, permitting it to course of over 1,500 pages of textual content or whole code repositories in a single immediate.
- Superior Reasoning Efficiency: It delivers greater than double the reasoning efficiency of Gemini 3 Professional, scoring 77.1% on the ARC-AGI-2 benchmark.
- Enhanced Agentic Reliability: Particularly optimized for autonomous workflows, together with a devoted API endpoint (gemini-3.1-pro-preview-customtools) for high-precision device orchestration and bash execution.
- Pricing: The fee/token of the most recent mannequin is identical as that of its predecessor. For these accustomed to the Professional variant, they’re getting a free improve.
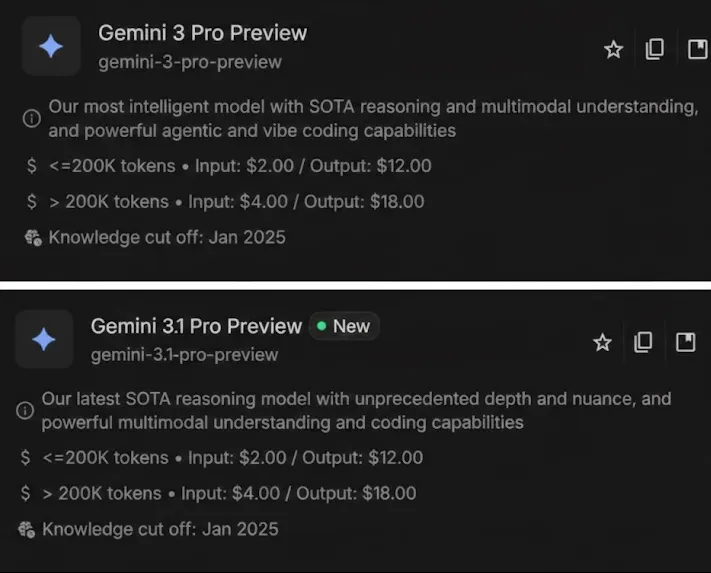
- Superior Vibe Coding: The mannequin handles visible coding exceptionally effectively. It might generate website-ready, animated SVGs purely by code, that means crisp scaling and tiny file sizes.
- Hallucinations: Gemini 3.1 Professional has tacked the hallucinations drawback head on by lowering its fee of hallucinations from 88% to 50% throughout AA-Omniscience: Data and Hallucination Benchmark
- Granular Considering: The mannequin provides extra granularity to the considering choice provided by its predecessor. Now the customers can select between excessive, medium and low considering parameters.
| Considering Degree | Gemini 3.1 Professional | Gemini 3 Professional | Gemini 3 Flash | Description |
| Minimal | Not supported | Not supported | Supported |
Matches the no considering setting for many queries. The mannequin might imagine minimally for complicated coding duties. Minimizes latency for chat or excessive throughput functions. |
| Low | Supported | Supported | Supported | Minimizes latency and price. Finest for easy instruction following or high-throughput functions. |
| Medium | Supported | Not supported | Supported | Balanced reasoning for many duties. |
| Excessive | Supported (Default, Dynamic) | Supported (Default, Dynamic) | Supported (Default, Dynamic) | Maximizes reasoning depth. Might improve latency, however outputs are extra fastidiously reasoned. |
Arms-On: Let’s have some enjoyable
All of the discuss on the planet wouldn’t quantity to something if the efficiency falls flat in follow. To judge Gemini 3.1 Professional correctly, I examined it throughout three classes:
- Advanced reasoning
- Code technology & debugging
- Lengthy-context synthesis
Activity 1: Multi-Step Logical Reasoning
What this checks: Chain-of-thought reasoning, constraint dealing with, and hallucination resistance.
Immediate:
“You’re given the next state of affairs:
5 analysts — A, B, C, D, and E — are assigned to a few initiatives: Alpha, Beta, and Gamma.
Guidelines:
1. Every mission should have a minimum of one analyst.
2. A can’t work with C.
3. B have to be assigned to the identical mission as D.
4. E can’t be on Alpha.
5. No mission can have greater than three analysts.
Query: Record all legitimate project combos. Present your reasoning clearly and guarantee no rule is violated.
“
Response:
Gemini 3.1 Professional dealt with constraint-heavy logic with out collapsing into contradictions, which is the place most fashions stumble. The consistency and readability in enumerating legitimate combos confirmed severe reasoning depth.
Activity 2: Code Era & Refactoring
What this checks: Structured considering, edge-case consciousness, code correctness, and manufacturing realism.
Immediate:
“You’re given the next Python operate:
def process_orders(orders):
complete = 0
for order in orders:
if order["status"] == "accomplished":
complete += order["amount"]
return completeRefactor this operate to:
1. Deal with lacking keys safely.
2. Ignore destructive quantities.
3. Log skipped invalid entries.
4. Be production-ready with sort hints and docstrings.
5. Embody unit checks for edge circumstances.
Return clear, well-structured Python code solely.
“
Response:
import logging
import unittest
from typing import Record, Dict, Any
logger = logging.getLogger(__name__)
def process_orders(orders: Record[Dict[str, Any]]) -> float:
"""
Course of a listing of order dictionaries and calculate
the overall quantity of accomplished orders.
"""
complete: float = 0.0
if not isinstance(orders, record):
logger.error("'orders' have to be a listing.")
return complete
for index, order in enumerate(orders):
if not isinstance(order, dict):
logger.warning("Skipping index %d: Not a dictionary.", index)
proceed
if order.get("standing") != "accomplished":
proceed
if "quantity" not so as:
logger.warning("Skipping index %d: Lacking 'quantity'.", index)
proceed
quantity = order["amount"]
if not isinstance(quantity, (int, float)) or isinstance(quantity, bool):
logger.warning("Skipping index %d: 'quantity' have to be numeric.", index)
proceed
if quantity The refactored code felt production-aware, not toy-level. It anticipated edge circumstances, enforced sort security, and included significant checks. That is the form of output that really respects real-world improvement requirements.
Activity 3: Lengthy-Context Analytical Synthesis
What this checks: Info compression, structured summarization, and reasoning throughout context.
Immediate:
“Beneath is an artificial enterprise report:
Firm: NovaGrid AI
2022 Income: $12M
2023 Income : $28M
2024 Income: $46M
Buyer churn elevated from 4% to 11% in 2024.
R&D spending elevated by 70% in 2024.
Working margin dropped from 18% to 9%.
Enterprise prospects grew by 40%.
SMB prospects declined by 22%.
Cloud infrastructure prices doubled.
Activity:
1. Diagnose the almost definitely root causes of margin decline.
2. Establish strategic dangers.
3. Suggest 3 data-backed actions.
4. Current your reply in a structured govt memo format.
“
Response:
It related monetary indicators, operational shifts, and strategic dangers right into a coherent govt narrative. The power to diagnose margin strain whereas balancing progress indicators reveals robust enterprise reasoning. It learn like one thing a pointy technique marketing consultant would draft, not a generic abstract.
Word: I didn’t use the usual “Create a dashboard” duties as most newest fashions like Sonnet 4.6, Kimi Ok 2.5, are simply capable of create one. So it wouldn’t provide a lot of a problem to a mannequin this succesful.
How one can entry Gemini 3.1 Professional?
In contrast to the earlier Professional fashions, Gemini 3.1 Professional is freely accessible by all of the customers on the platform of their alternative.
Now that you simply’ve made up your thoughts about utilizing Gemini 3.1 Professional, let’s see how one can entry the mannequin.
- Gemini Internet UI: Free and Gemini Superior customers now have 3.1 Professional obtainable beneath the mannequin part choice.
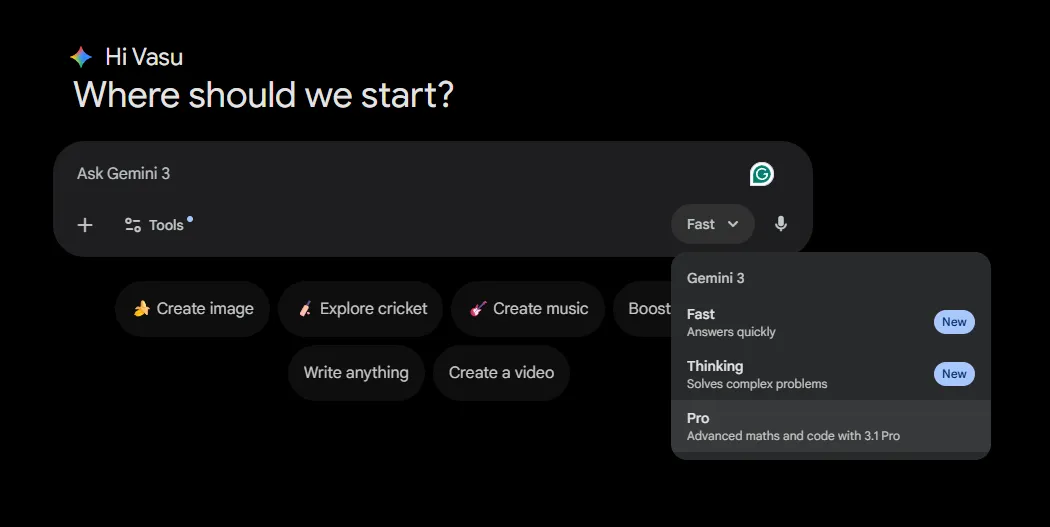
- API: Out there by way of Google AI Studio for builders (fashions/Gemini-3.1-pro).
| Mannequin | Base Enter Tokens | 5m Cache Writes | 1h Cache Writes | Cache Hits & Refreshes | Output Tokens |
| Gemini 3.1 Professional (≤200 Ok tokens) | $2 / 1M tokens | ~$0.20–$0.40 / 1M tokens | ~$4.50 / 1M tokens per hour storage | Not formally documented | $12 / 1M tokens |
| Gemini 3.1 Professional (>200 Ok tokens) | $4 / 1M tokens | ~$0.20–$0.40 / 1M tokens | ~$4.50 / 1M tokens per hour storage | Not formally documented | $18 / 1M tokens |
- Cloud Platforms: Being rolled out to NotebookLM, Google Cloud’s Vertex AI, and Microsoft Foundry.
Benchmarks
To quantify how good this mannequin is, the benchmarks would help.
There’s a lot to decipher right here. However probably the most astounding enchancment of all is actually in Summary reasoning puzzles.
Let me put issues into perspective: Gemini 3 Professional launched with a ARC-AGI-2 rating of 31.1%. This was the best for the time and thought of a breakthrough for LLM requirements. Quick ahead simply 3 months, and that rating has been eclipsed by its personal successor by double the margin!
That is the fast tempo at which AI fashions are enhancing.
In case you’re unfamiliar with what these benchmarks check, learn this text: AI Benchmarks.
Conclusion: Highly effective and Accessible
Gemini 3.1 Professional proves it’s greater than a flashy multimodal mannequin. Throughout reasoning, code, and analytical synthesis, it demonstrates actual functionality with manufacturing relevance. It’s not flawless and nonetheless calls for structured prompting and human oversight. However as a frontier mannequin embedded in Google’s ecosystem, it’s highly effective, aggressive, and completely value severe analysis.
Regularly Requested Questions
A. It’s constructed for superior reasoning, long-context processing, multimodal understanding, and production-grade AI functions.
A. Builders can entry it by way of Google AI Studio for prototyping or Vertex AI for scalable, enterprise deployments.
A. It performs strongly however nonetheless requires structured prompting and human oversight to make sure accuracy and scale back hallucinations.
I specialise in reviewing and refining AI-driven analysis, technical documentation, and content material associated to rising AI applied sciences. My expertise spans AI mannequin coaching, knowledge evaluation, and knowledge retrieval, permitting me to craft content material that’s each technically correct and accessible.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}