
This submit is co-written with Moshiko Ben Abu, Software program Engineer at CyberArk.
CyberArk achieved as much as 95% discount in case decision time utilizing Amazon Bedrock and Apache Iceberg.
This enchancment addresses a problem in technical assist workflow: when a assist engineer receives a brand new buyer case, the largest bottleneck is usually not diagnosing the issue however getting ready the information. Buyer logs arrive in numerous codecs from a number of distributors, and every new log format usually requires guide integration and correlation earlier than an investigation can start. For easy instances, this course of can take hours. For extra complicated investigations, it could actually take days, slowing decision and lowering general engineer productiveness.
CyberArk is a worldwide chief in id safety. Centered on clever privilege controls, it supplies complete safety for human, machine, and AI identities throughout enterprise functions, distributed workforces, and hybrid cloud environments.
On this submit, we present you ways CyberArk redesigned their assist operations by combining Iceberg’s clever metadata administration with AI-powered automation from Amazon Bedrock. You’ll discover ways to simplify knowledge processing flows, automate log parsing for numerous codecs, and construct autonomous investigation workflows that scale robotically.
To realize these outcomes, CyberArk wanted an answer that might ingest buyer logs, robotically construction them, set up relationships between associated occasions, and make the whole lot queryable in minutes, not days. The structure needed to be serverless to deal with unpredictable assist volumes, safe sufficient to guard buyer Personally Identifiable Info (PII), and quick sufficient to permit identical day case decision.
The legacy structure: Bottlenecks and guide workflows
When assist engineers acquired buyer instances, they might add log recordsdata to the information lake saved in Amazon Easy Storage Service (Amazon S3). The unique design then suffered from the complexity of multi-step uncooked knowledge processing.
First, CyberArk’s customized parsing logic operating on AWS Fargate would parse these uploaded log recordsdata and rework the uncooked knowledge. Throughout this stage, the system additionally needed to scan for PII and masks delicate knowledge to guard buyer privateness.
Subsequent, a separate course of transformed the processed knowledge into Parquet format.
Lastly, AWS Glue crawlers had been required to find new partitions and replace desk metadata for processed Parquet recordsdata. This dependency grew to become essentially the most complicated and time-consuming a part of the pipeline. Crawlers ran as asynchronous batch jobs relatively than in actual time, typically introducing delays of minutes to hours earlier than assist engineers might question the information.
However the inefficiency went deeper than simply architectural complexity. CyberArk helps clients operating numerous product environments throughout a number of distributors. Every vendor and product produces logs in numerous codecs with distinctive schemas, area names, and buildings. Including assist for a brand new vendor meant days of integration work to grasp their log format and construct customized parsers.
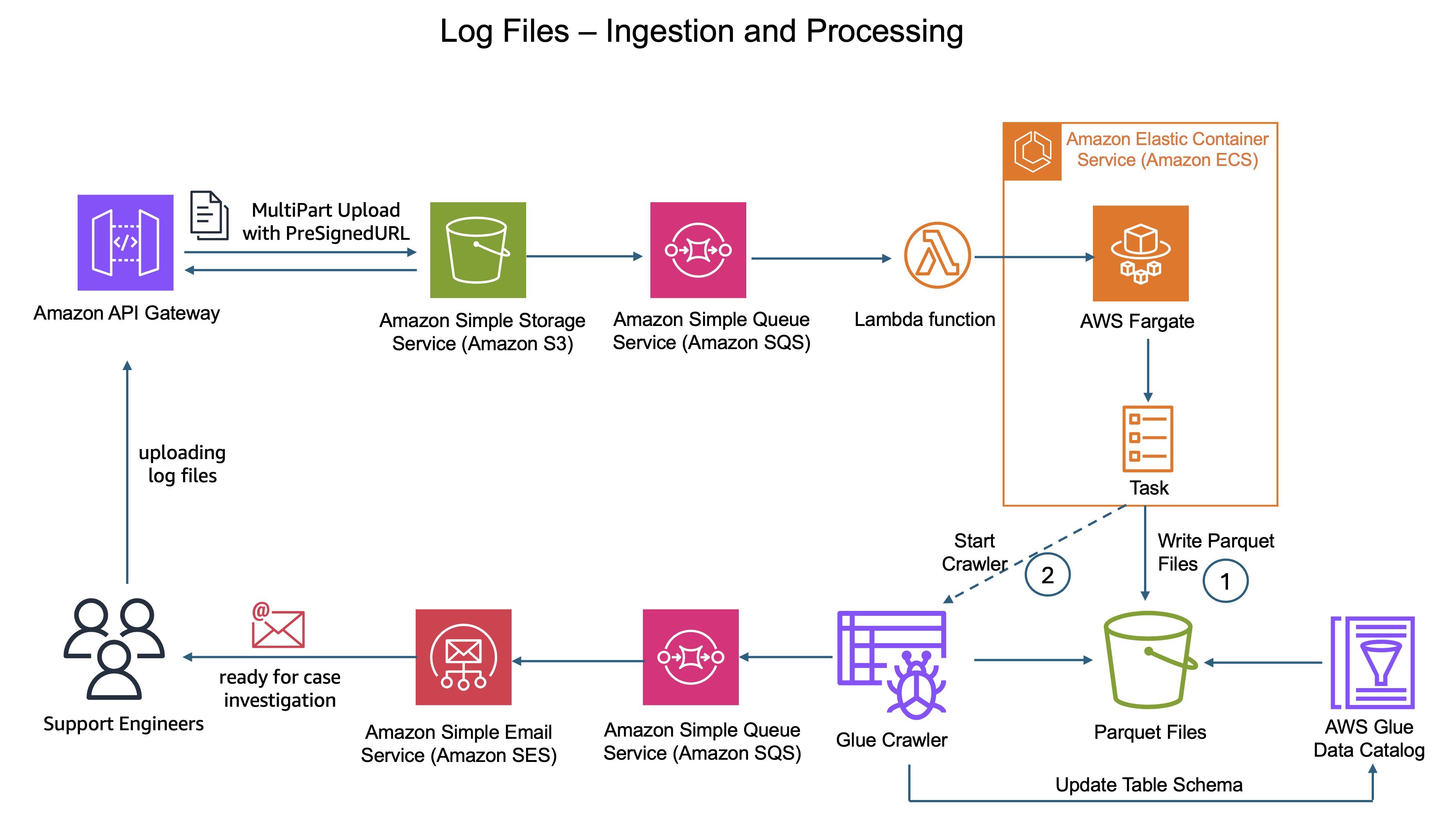
Determine 1: Legacy log ingestion structure diagram displaying the circulate from S3 add via AWS Fargate processing with AWS Glue Crawler
Past ingestion, the investigation course of itself was guide and time consuming. Help engineers would manually question knowledge, correlate occasions throughout totally different log sources, search via product documentation, and piece collectively root trigger evaluation via trial and error. This course of required deep product experience and will take hours or days relying on difficulty complexity. The brand new structure addresses these inefficiencies via three key improvements:
- Single stage serverless processing: AWS Fargate with PyIceberg instantly creates Iceberg tables from uncooked logs in a single move, eradicating intermediate processing steps and crawler dependencies solely.
- AI powered dynamic parsing: Amazon Bedrock robotically generates grok patterns for log parsing by analyzing file schemas, remodeling what was as soon as a guide, time consuming course of into a completely automated workflow.
- Autonomous investigation with AI Brokers: AI Brokers autonomously carry out full root trigger evaluation by querying log knowledge, analyzing product information bases, figuring out occasion flows, and recommending options, remodeling hours of guide investigation into minutes of automated intelligence.
The answer: AI-powered automation meets single-stage Iceberg processing
The brand new system delivers zero contact log processing from add to question. Help engineers merely add buyer log ZIP recordsdata to the system. Right here’s the place the transformation occurs: CyberArk’s customized processing logic nonetheless runs on AWS Fargate, however now it makes use of Amazon Bedrock to intelligently perceive the information.
Zero-touch log processing workflow
The system extracts pattern log entries from the uploaded log recordsdata and sends them to Amazon Bedrock together with context concerning the log supply and desk schema from AWS Glue Information Catalog. Amazon Bedrock analyzes the samples, understands the construction, and robotically generates grok patterns optimized for the precise log format.
Grok patterns are structured expressions that outline easy methods to extract significant fields from unstructured log textual content. For instance, the next grok sample specifies {that a} timestamp seems first, adopted by a severity degree, then a message physique %{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:severity} %{GREEDYDATA:message}
The system validates these grok patterns in opposition to further samples to confirm accuracy earlier than making use of them to parse the whole log file. Efficiently validated grok patterns are saved in Amazon DynamoDB, making a repository of identified patterns. When the system encounters related log codecs in future uploads, it could actually retrieve these patterns instantly from Amazon DynamoDB, avoiding redundant grok sample technology. Amazon Bedrock processes log samples in real-time with out retaining buyer knowledge or utilizing it for mannequin coaching, sustaining knowledge privateness.
This complete course of invokes Claude 3.7 Sonnet mannequin from Amazon Bedrock and is orchestrated by AWS Fargate duties with retry logic for reliability. The processing makes use of these AI-generated grok patterns to parse the logs and create or replace Iceberg tables utilizing PyIceberg APIs with out human intervention.
This automation diminished logs onboarding time from days to minutes, enabling CyberArk to deal with numerous buyer environments with out guide intervention.
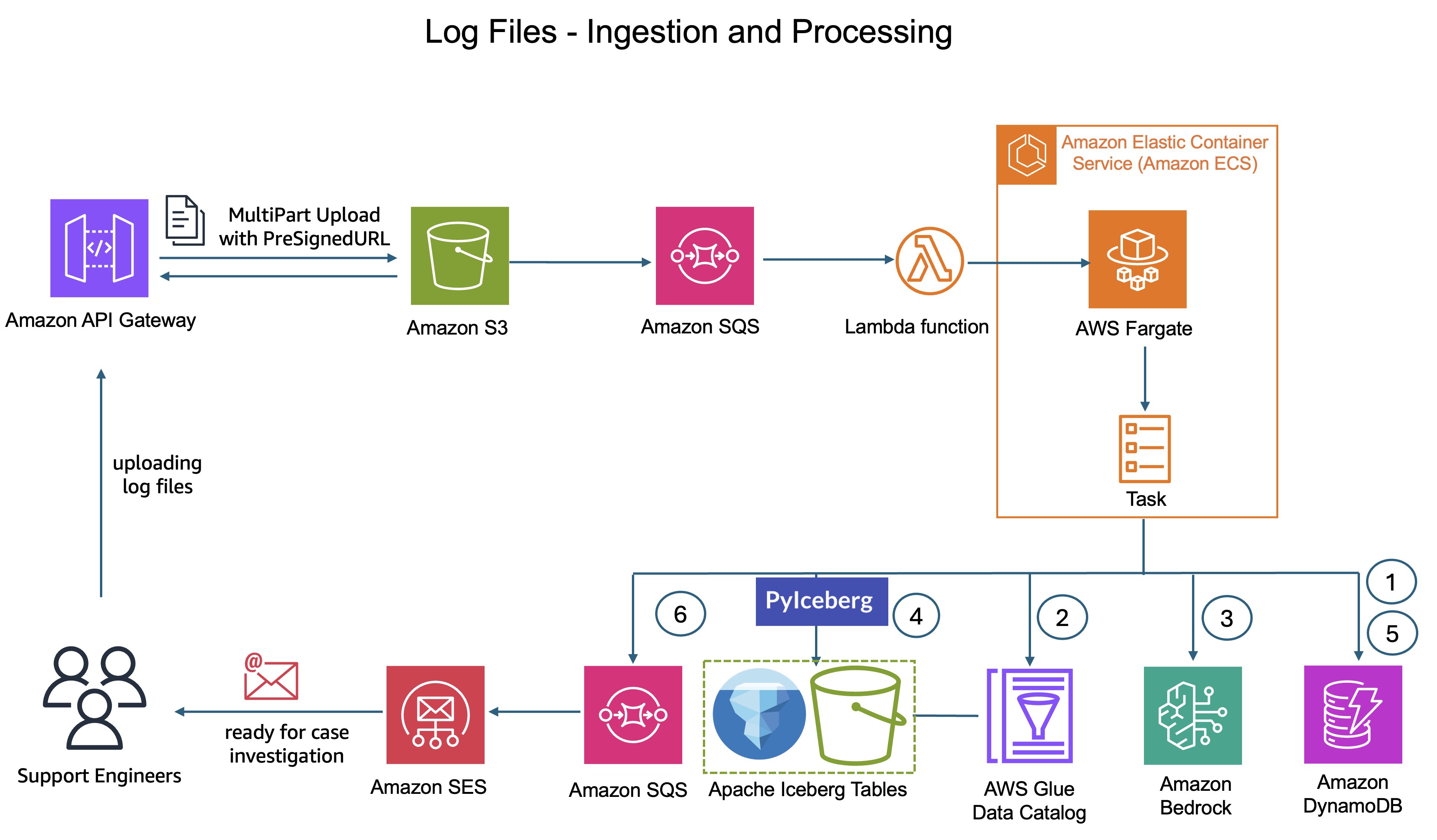
Determine 2: Log ingestion structure diagram displaying the circulate from S3 add via AWS Fargate processing with Amazon Bedrock integration to Iceberg desk creation
Apache Iceberg: Simplified structure, sooner queries
Iceberg simplified and improved CyberArk’s knowledge lake structure by addressing the 2 major bottlenecks within the legacy system: sluggish schema administration and inefficient question efficiency.
Constructed-in schema evolution removes crawler dependency
Within the legacy structure, AWS Glue crawlers grew to become a supply of operational overhead and latency. Even when triggered on demand, crawlers ran as batch jobs over S3 prefixes to find partitions and replace metadata. As knowledge volumes grew and datasets diversified throughout distributors and schemas, groups needed to handle and function a rising variety of crawler jobs. The ensuing delays, typically starting from minutes to hours, slowed knowledge availability and downstream investigation workflows.
Iceberg removes this whole layer of complexity. Iceberg’s clever metadata layer robotically tracks desk construction, schema modifications, and partition info as knowledge is written. When CyberArk’s processing creates or updates Iceberg tables via PyIceberg, the metadata is up to date immediately and atomically. There’s no ready for crawlers jobs to finish, and no threat of stale metadata. The second knowledge is written, it’s instantly queryable in Amazon Athena.
PyIceberg: Making Iceberg accessible past Apache Spark
Working with Iceberg often concerned Apache Spark and the complexity of distributed knowledge processing. PyIceberg modified that by letting CyberArk create and handle Iceberg tables utilizing a easy Python library. CyberArk’s knowledge engineers might write simple Python code operating on AWS Fargate to create Iceberg tables instantly from parsed logs, with out spinning up Spark clusters.
This accessibility was important for CyberArk’s serverless structure. PyIceberg enabled single stage processing the place AWS Fargate duties might parse logs, apply PII masking, and create Iceberg tables in a single move. The consequence was easier code and decrease operational overhead.
Metadata-driven question optimization delivers pace
Along with eradicating crawlers, Iceberg considerably improved question efficiency via its clever metadata structure. Iceberg maintains detailed statistics about knowledge recordsdata, together with min/max values, null counts, and partition info. When assist engineers question knowledge in Athena, Iceberg’s metadata layer helps partition pruning and file skipping, ensuring queries solely learn the precise recordsdata containing related knowledge. For CyberArk’s use case, the place tables are partitioned by case ID, this implies a question for a selected assist case solely reads the recordsdata for that case, ignoring doubtlessly 1000’s of irrelevant recordsdata. This metadata pushed optimization diminished question execution time from minutes to seconds, permitting assist engineers to interactively discover knowledge relatively than ready for outcomes.
ACID transactions keep knowledge consistency
In a multi person assist setting the place a number of engineers could also be analyzing overlapping instances or importing logs concurrently, knowledge consistency is crucial. Iceberg’s ACID transaction assist helps confirm that concurrent writes don’t corrupt knowledge or create inconsistent states. Every desk replace is atomic, remoted, and sturdy, offering the reliability CyberArk wanted for manufacturing assist operations.
Time journey permits historic evaluation
Iceberg’s built-in versioning permits assist engineers to question historic states of knowledge, important for understanding how buyer points developed over time. If an engineer must see what the logs seemed like when a case was first opened versus after a buyer utilized a patch, Iceberg’s time journey capabilities make this simple. This characteristic proved important for complicated troubleshooting situations the place understanding the timeline of occasions was important to decision.
Automated desk optimization with AWS Glue
Iceberg tables require periodic upkeep to keep up question efficiency.
CyberArk enabled AWS Glue automated desk optimization for his or her Iceberg tables, which handles compaction and expired snapshot cleanup within the background.
For CyberArk’s steady add workflow, this automation avoids efficiency degradation over time. Tables keep optimized with out guide intervention from the engineering staff.
AI Brokers: Autonomous investigation workflow
Whereas the Claude 3.7 Sonnet mannequin from Amazon Bedrock automates grok sample technology for log ingestion, the extra superior use of Amazon Bedrock comes within the investigation workflow. We use AI brokers with Bedrock fashions to vary how assist engineers analyze and resolve buyer points.
From guide evaluation to AI powered investigation
Within the legacy workflow, assist engineers would manually question knowledge, correlate occasions throughout totally different log sources, search via product documentation, and piece collectively root trigger evaluation via trial and error. This course of required deep product experience and will take hours or days relying on difficulty complexity. AI Brokers automate this whole investigation course of. Help engineers use an inside portal to ask questions in pure language about buyer points, questions like
“Present me authentication errors for case 12345 within the final 24 hours”, “What had been the most typical errors throughout instances opened this week?” or “Examine the error patterns between case 12345 and case 12346.”
Behind the scenes, the system fires specialised AI Brokers that autonomously carry out thorough evaluation.
How assist brokers work
Every AI Agent operates as an clever investigator with a transparent mission: perceive what occurred, decide why it occurred, and suggest easy methods to repair it. When a assist engineer asks a query, the agent collects related knowledge by querying Athena to retrieve log knowledge from Iceberg tables, filtering for the precise case and time interval related to the investigation. The agent then accesses CyberArk’s inside information base for the precise product concerned, understanding identified points, frequent error patterns, and documented options. The agent then performs the next evaluation:
- Circulate identification: Analyzes the sequence of occasions within the logs to grasp what really occurred through the buyer’s difficulty
- Root trigger dedication: Correlates log occasions with product information to establish the underlying explanation for the issue
- Resolution suggestions: Suggests particular remediation steps based mostly on the foundation trigger evaluation and identified decision patterns
This complete course of occurs in minutes, delivering superior evaluation that may have taken assist engineers hours to carry out manually.
For complicated instances the place an answer shouldn’t be discovered, the assist agent escalates to a different, specialised agent that interacts with service engineers to gather further inputs and experience. This human-in-the-loop strategy makes certain that even essentially the most difficult instances obtain applicable consideration whereas nonetheless benefiting from the automated investigation workflow. The insights gathered from these escalated instances are robotically fed again into CyberArk’s information base, repeatedly bettering the system’s capacity to deal with related points autonomously sooner or later.
Amazon Bedrock by no means shares buyer knowledge with mannequin suppliers or makes use of it to coach basis fashions, case knowledge and investigation insights stay inside CyberArk’s setting.
Concurrent agent execution at scale
When a number of assist engineers examine totally different instances concurrently, the answer runs specialised brokers concurrently. CyberArk at the moment makes use of Claude 3.7 Sonnet as the inspiration mannequin for these brokers. Every agent works independently on its assigned investigation, working in parallel with out useful resource rivalry. This concurrent execution permits the investigation workflow to scale robotically with assist quantity, dealing with peak masses with out efficiency degradation.
AI-powered investigation benefit
This AI-powered investigation workflow delivers two key benefits.
Investigations that took hours now full in minutes, enabling assist engineers to resolve as much as 4x extra instances per day.
The system additionally creates a steady studying suggestions loop. When instances require guide decision by engineers, these resolutions are robotically recorded and fed again into the information base. Future investigations profit from this gathered experience, with brokers making use of classes discovered from earlier guide resolutions to related instances. Amazon Bedrock doesn’t use buyer knowledge to coach basis fashions. Case knowledge and investigation insights stay inside CyberArk’s setting.
This automated suggestions mechanism means the investigation workflow turns into simpler over time, repeatedly bettering decision accuracy and pace.
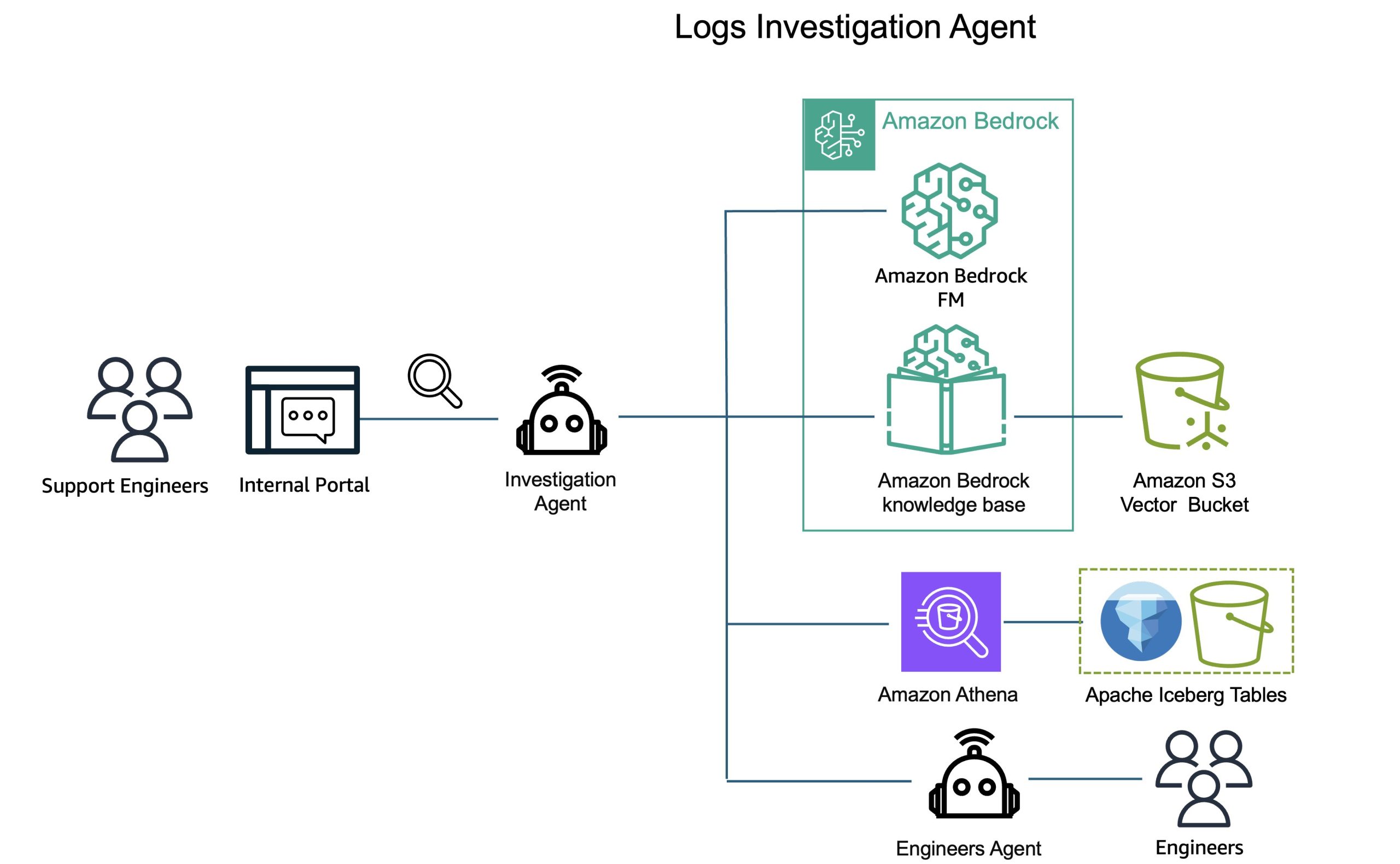
Determine 3: Investigation workflow diagram displaying pure language question via AI Brokers to Athena queries and information base evaluation
Scaling with out proportional engineering development
The enterprise affect of this AI automation is important. CyberArk can develop its vendor protection and product portfolio with out including knowledge engineering headcount. The identical system that handles right this moment’s log varieties will robotically deal with tomorrow’s additions, whether or not that’s ten new codecs or 1000’s, considerably lowering time to marketplace for new product and vendor integrations.
The outcomes: Vital enhancements in decision time and productiveness
The transformation delivered measurable enhancements throughout each key metric.
Decision time: CyberArk achieved as much as 95% discount in time from case project to decision. Easy instances that used to take 4 to six hours now take simply 15 to half-hour. Complicated instances that beforehand took as much as 15 days are actually accomplished in 2 to 4 hours.
Engineer productiveness: Help engineers now deal with 8 to 12 instances per day, in comparison with simply 2 to three instances earlier than. This implies every engineer helps as much as 4x extra clients.
Information availability: Logs are queryable inside minutes of add as a substitute of ready hours or days. Help engineers can begin investigating points virtually instantly after receiving buyer knowledge.
Operational effectivity: The system requires zero guide intervention for brand new log codecs or schema modifications. Instances that used to require days of knowledge engineering work now occur robotically.
Value optimization: The serverless structure alleviated idle infrastructure prices whereas scaling robotically with demand. CyberArk solely pays for what they use, once they use it.
Buyer satisfaction: Quicker decision instances and proactive difficulty identification considerably improved the shopper expertise. Issues get solved in hours as a substitute of days, and clients spend much less time ready for solutions.
What’s subsequent?
Whereas AWS continues to innovate throughout each knowledge lake administration and agentic AI infrastructure, the next capabilities align effectively with CyberArk’s structure and will supply further operational advantages because the system scale.
Agent infrastructure maturity
Because the agent-based structure scales to deal with 1000’s of concurrent investigations, CyberArk is transitioning to Amazon Bedrock AgentCore for future agent deployments. AgentCore supplies a managed runtime for manufacturing AI brokers with enhanced observability via AWS X-Ray integration, clever reminiscence for context retention throughout periods, and streamlined operational workflows. Whereas the present AI Brokers implementation delivers the efficiency and reliability CyberArk wants right this moment, AgentCore represents a pure evolution path as operational necessities develop, providing framework-agnostic deployment, automated scaling, and complete monitoring capabilities with out infrastructure administration overhead.
Amazon S3 Tables
CyberArk’s present structure makes use of Iceberg tables saved in Amazon S3 buckets. Amazon S3 Tables presents totally managed Iceberg tables with built-in optimization.
As CyberArk proceed to scale with tons of of Iceberg tables and speedy knowledge development, CyberArk is exploring a migration to Amazon S3 Tables to additional scale back operational overhead.
S3 Tables take away the necessity to arrange and monitor AWS Glue upkeep jobs. It robotically performs upkeep to reinforce the efficiency of Iceberg tables, together with unreferenced file removing, file compaction, and snapshot administration. Moreover, S3 Tables supplies Clever-Tiering that robotically strikes knowledge between storage courses based mostly on entry patterns, optimizing storage prices with out guide intervention.
As a result of S3 Tables makes use of Iceberg open desk format, migration wouldn’t require modifications to current Athena queries and PyIceberg code. This flexibility permits CyberArk to guage and undertake S3 Tables when the operational and value advantages align with their enterprise wants.
Conclusion
CyberArk’s transformation demonstrates how combining trendy knowledge lake structure with AI automation can considerably change operational economics. By combining Iceberg’s clever metadata administration with AI-powered automation from Amazon Bedrock, CyberArk reworked case decision from days to minutes whereas enabling assist operations to scale robotically with enterprise development. Help engineers now spend their time fixing buyer issues as a substitute of wrangling knowledge, clients obtain sooner resolutions, and the system scales robotically with the enterprise.
To study extra about Iceberg on AWS, check with Working with Amazon S3 Tables and desk buckets and Utilizing Apache Iceberg on AWS. To study extra about Amazon Bedrock AgentCore, check with Amazon Bedrock AgentCore.
In regards to the authors

{kind=link}