
This put up is co-written with Srinivasa Are, Principal Cloud Architect, and Karthick Shanmugam, Head of Structure Verisk EES (Excessive Occasion Options).
Verisk, a disaster modeling SaaS supplier serving insurance coverage and reinsurance firms worldwide, lower processing time from hours to minutes-level aggregations whereas decreasing storage prices by implementing a lakehouse structure with Amazon Redshift and Apache Iceberg. When you’re managing billions of disaster modeling information throughout hurricanes, earthquakes, and wildfires, this strategy eliminates the normal compute-versus-cost trade-off by separating storage from processing energy.
On this put up, we look at Verisk’s lakehouse implementation, specializing in 4 architectural selections that delivered measurable enhancements:
- Execution efficiency: Sub-hour aggregations throughout billions of information changed lengthy batch course of
- Storage effectivity: Columnar Parquet compression diminished prices with out sacrificing response time
- Multi-tenant safety: Schema-level isolation enforced full knowledge separation between insurance coverage shoppers
- Schema flexibility: Apache Iceberg assist column additions and historic knowledge entry with out downtime
The structure separates compute (Amazon Redshift) from storage (Amazon S3), demonstrating find out how to scale from billions to trillions of information with out proportional price will increase.
Present state and challenges
In Verisk’s world of danger analytics, knowledge volumes develop at exponential charges. Daily, danger modeling techniques generate billions of rows of structured and semi-structured knowledge. Every report captures a micro-slice of publicity, occasion chance, or loss correlation. To transform this uncooked info into actionable insights at scale, consultants want a knowledge engine designed for high-volume analytical workloads.
Every Verisk mannequin run produces detailed, high-granularity outputs that embrace billions of simulated danger elements and event-level outcomes, multi-year loss projections throughout hundreds of perils, and deep relational joins throughout publicity, coverage, and claims datasets.
Operating significant aggregations (reminiscent of, loss by area, peril, or occupancy sort) over such excessive volumes created efficiency challenges.
Verisk wanted to construct a SQL service that would combination at scale within the quickest time doable and combine into their broader AWS options, requiring a serverless, open, and performant SQL engine able to dealing with billions of information effectively.
Previous to this cloud-based launch, Verisk’s danger analytics infrastructure operated on an on-premises structure centered round relational database clusters. Processing nodes shared entry to centralized storage volumes by devoted interconnect networks. This structure required capital funding in server {hardware}, storage arrays, and networking tools. The deployment mannequin required handbook capability planning and provisioning cycles, limiting the group’s means to answer fluctuating workload calls for. Database operations trusted batch-oriented processing home windows, with analytical queries competing for shared compute assets.
Amazon Redshift and lakehouse structure
Lakehouse structure on AWS combines knowledge lake storage scalability with knowledge warehouse analytical efficiency in a unified structure. This structure shops huge quantities of structured and semi-structured knowledge in cost-effective Amazon S3 storage whereas sustaining Amazon Redshift’s massively parallel SQL analytics.
Amazon Redshift is a totally managed, petabyte-scale cloud knowledge warehouse service that delivers quick question efficiency utilizing massively parallel processing (MPP) and columnar storage. Amazon Redshift eliminates the complexity of provisioning {hardware}, putting in software program, and managing infrastructure, preserving deal with deriving insights from their knowledge quite than sustaining techniques.
To satisfy their problem, Verisk designed a hybrid knowledge lakehouse structure that mixes the storage scalability of Amazon S3 with the compute energy of Amazon Redshift. The next diagram exhibits the foundational compute and storage structure that powers Verisk’s analytical resolution.
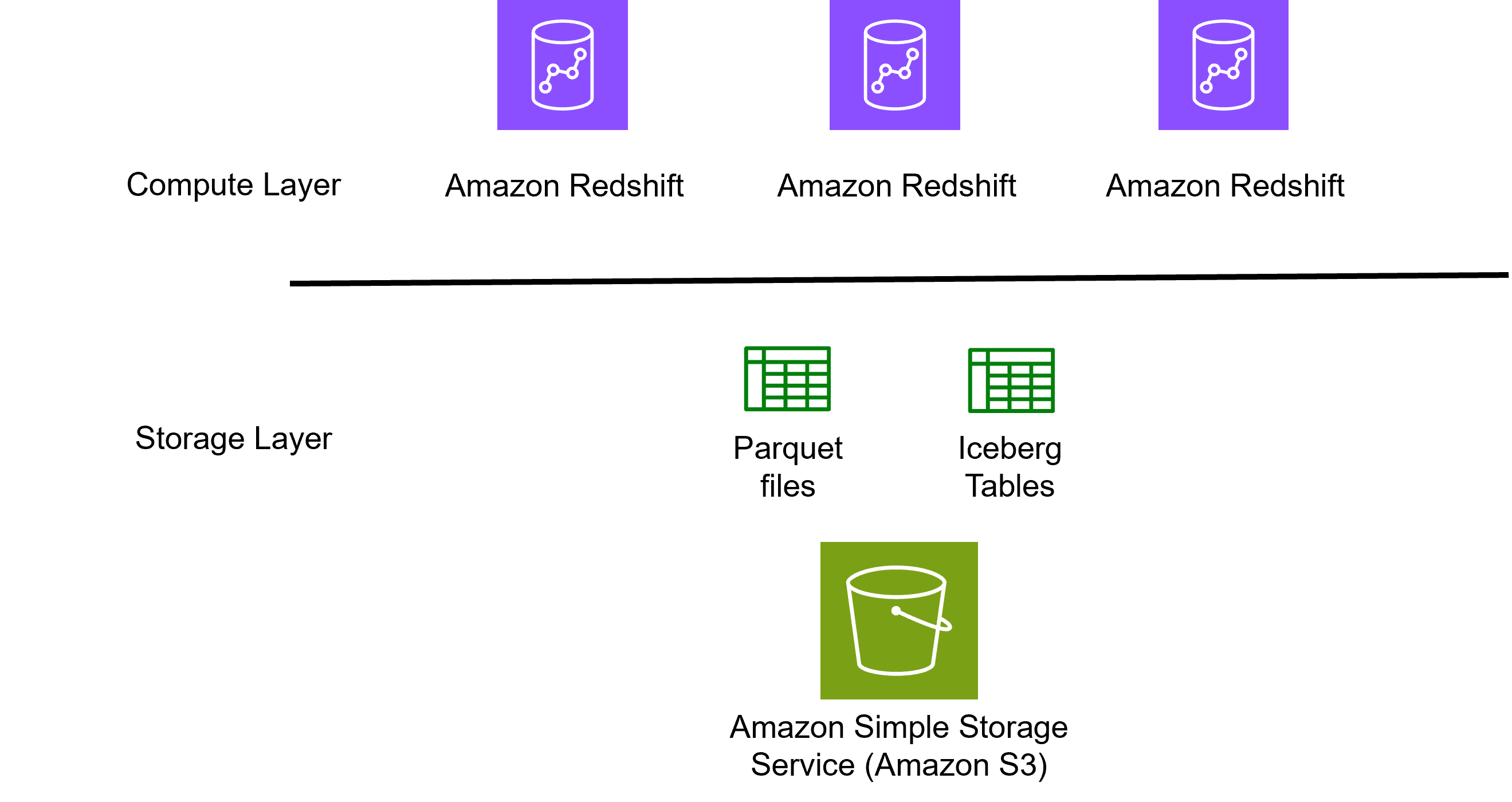
Structure Overview
The structure processes danger and loss knowledge by three distinct phases inside the lakehouse structure, with complete multi-tenant supply capabilities to take care of isolation between insurance coverage shoppers.
Amazon Redshift permits retrieving knowledge immediately from S3 utilizing commonplace SQL for background processing. This resolution collects detailed consequence outputs, be a part of them with inside reference knowledge, and executes aggregations over billions of rows. Concurrency scaling ensures that a whole lot of background analyses utilizing a number of serverless clusters can run simultaneous aggregation queries.
The next diagram exhibits the structure designed by Verisk
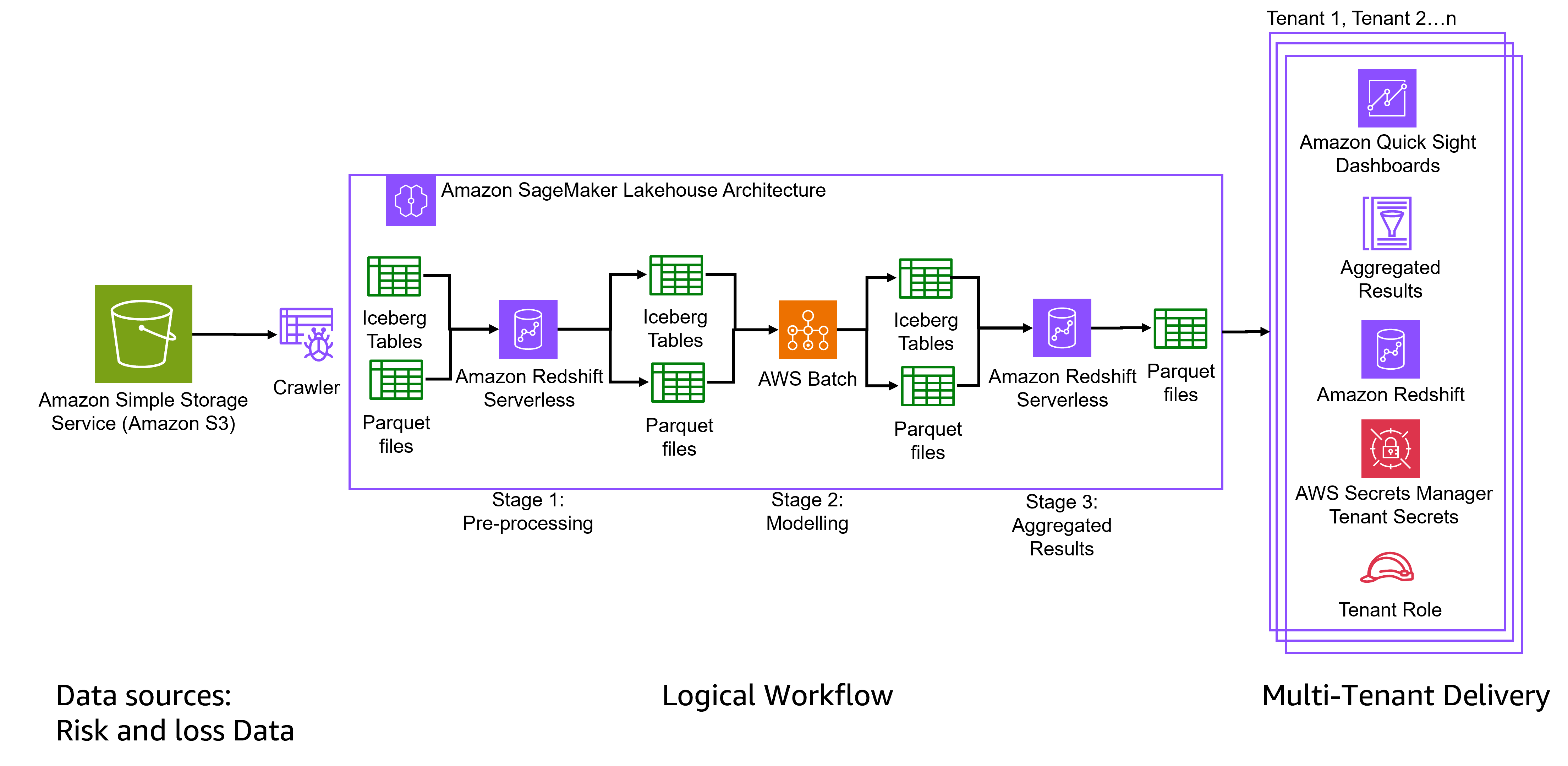
Information ingestion and storage basis
Verisk shops danger mannequin outputs, location stage losses, publicity tables, and mannequin knowledge in columnar Parquet format inside Amazon S3. An AWS Glue crawler extracts metadata from S3 and feeds it into the lakehouse processing pipeline.
For versioned datasets like publicity tables, Verisk adopted Apache Iceberg, an open desk format that addresses schema evolution and historic versioning necessities. Apache Iceberg offers transactional consistency by atomicity, consistency, isolation, sturdiness ACID-compliant operations that keep constant snapshots throughout concurrent updates. Snapshot-based time journey permits knowledge retrieval at earlier time limits for regulatory compliance, audit trails, and mannequin comparability with rollback capabilities. Schema evolution helps including, dropping, or renaming columns with out downtime or dataset rewrites. Incremental processing makes use of metadata monitoring to course of solely modified knowledge, decreasing refresh occasions. Hidden partitioning and file-level statistics cut back I/O operations, enhancing aggregation efficiency. Engine interoperability permits accessing the identical tables throughout Amazon Redshift, Amazon Athena, Spark, and different engines with out knowledge duplication.
Verisk constructed a basis that mixes S3’s cost-effectiveness with knowledge administration by adopting Apache Iceberg as open desk format for this resolution.
Three-stage processing pipeline
This pipeline orchestrates knowledge stream from uncooked inputs to analytical outputs by three sequential phases. Pre-processing prepares and cleanses knowledge, modeling applies danger calculations and analytics, and post-processing aggregates outcomes for supply.
- Stage 1: Pre-processing transforms uncooked knowledge into structured codecs utilizing Iceberg Tables and Parquet recordsdata, then processes it by Amazon Redshift Serverless for preliminary knowledge cleansing and transformation.
- Stage 2: Modeling takes place with a course of constructed on AWS Batch the pre-processed knowledge and applies superior analytics and have engineering. Outcomes are saved in Iceberg Tables and Parquet recordsdata.
- Stage 3: Aggregated Outcomes are obtained throughout post-processing utilizing Amazon Redshift Serverless, it produces the ultimate analytical outputs in Parquet recordsdata, prepared for consumption by finish customers.
Multi-tenant supply system
The structure delivers outcomes to a number of insurance coverage shoppers (tenants) by a safe, remoted supply system that features:
- Amazon Fast Sight dashboards for visualization and enterprise intelligence
- Amazon Redshift as the info warehouse for querying aggregated outcomes
- AWS Batch for modelling processing.
- AWS Secrets and techniques Supervisor to handle tenant-specific credentials
- Tenant Roles implementing role-based entry management to offer knowledge isolation between shoppers
Summarized outcomes are uncovered by Amazon Fast Sight dashboards or downstream APIs to underwriting groups.
Multi-tenant safety structure
A vital requirement for Verisk’s SaaS resolution was supporting complete knowledge and compute isolation between totally different insurance coverage and reinsurance shoppers. Verisk carried out a complete multi-tenant safety mannequin that gives isolation whereas sustaining operational effectivity.
Our resolution implements an isolation technique in two layers combining logical and bodily separation. On the logical layer, every shopper’s knowledge resides in devoted schemas with entry controls that forestall cross-tenant operations. Amazon Redshift Metadata safety restricts tenants from discovering or accessing different shoppers’ schemas, tables, or database objects by system catalogs. On the bodily layer, for bigger deployments, devoted Amazon Redshift clusters present workload separation on the compute stage, stopping one tenant’s analytical operations from impacting one other’s efficiency. This twin strategy meets regulatory necessities for knowledge isolation within the insurance coverage business by schema-level isolation inside clusters for normal deployments and full compute separation throughout devoted clusters for larger-scale implementations.
The implementation makes use of saved procedures to automate safety configuration, sustaining constant software of entry controls throughout tenants. This defense-in-depth strategy combines schema-level isolation, system catalog lockdown, and selective permission grants to create a safety mannequin.
For knowledge architects keen on implementing related multi-tenant architectures, evaluation Implementing Metadata Safety for Multi-Tenant Amazon Redshift Atmosphere.
Implementation concerns
Verisk’s structure reveals three resolution factors for firms constructing related techniques.
When to undertake open desk codecs
Apache Iceberg proved important for datasets requiring schema evolution and historic versioning. Information engineers ought to consider open desk codecs when analytical workloads span a number of engines (Amazon Redshift, Amazon Athena, Spark) or when regulatory necessities demand point-in-time knowledge reconstruction.
Multi-tenant isolation technique
Schema-level separation mixed with metadata safety prevented cross-tenant knowledge discovery with out efficiency overhead. This strategy scales extra effectively than database-per-tenant architectures whereas assembly insurance coverage business compliance necessities. Safety consultants ought to implement isolation controls throughout preliminary deployment quite than retrofitting them later.
Saved procedures or software logic
Redshift saved procedures standardized aggregation calculations throughout groups and constructed dynamic SQL queries. This strategy works greatest when enterprise logic adjustments incessantly or when a number of groups want totally different aggregation dimensions on the identical datasets.
Conclusion
Verisk’s implementation of Amazon Redshift Serverless with Apache Iceberg and lakehouse structure exhibits how separating compute from storage addresses enterprise analytics challenges at billion-record scale. By combining cost-effective Amazon S3 storage with Redshift’s massively parallel SQL compute, Verisk achieved aggregations throughout billions of disaster modeling information, diminished storage prices by environment friendly parquet compression, and eradicated ingestion delays. Now underwriting groups can run ad-hoc analyses throughout enterprise hours quite than ready for long-running batch jobs. The mixture of open requirements like Apache Iceberg, serverless compute with Amazon Redshift, and multi-tenant safety offers the scalability, efficiency, and price effectivity wanted for contemporary analytics workloads.
Verisk’s journey has positioned them to scale confidently into the long run, processing not simply billions, however doubtlessly trillions of information as their mannequin decision will increase.
In regards to the authors

{kind=link}