
In Half I, we launched the enterprise background behind Log Lake. On this put up, we describe how one can construct it, and how one can add mannequin invocation logs from Amazon Bedrock.
The unique use case of Log Lake was to hitch AWS CloudTrail logs (with StartSession API calls) with Amazon CloudWatch logs (with session keystrokes from inside Session Supervisor, a functionality of AWS Techniques Supervisor), to assist a supervisor assessment an worker’s use of elevated permissions to find out if the use was applicable. As a result of there is perhaps just one occasion of elevated privileges in tens of millions or billions of rows of log knowledge, discovering the best row to assessment was like in search of a needle in a haystack.
Log Lake is not only for Session Supervisor, but in addition normal function CloudTrail and CloudWatch logs. After including CloudWatch and CloudTrail logs to uncooked tables at scale, you possibly can arrange AWS Glue jobs to course of the various tiny JSON information of uncooked tables into greater binary information for “readready” tables. Then, these readready tables might be queried with totally different filters to reply questions for a lot of use circumstances, resembling authorized or regulatory critiques for compliance, deep forensic investigations for safety, or auditing. Log Lake is a solution to the query “Are there logs, and in that case, how do I get them?”
Resolution overview
Log Lake is an information lake for compliance-related use circumstances, makes use of CloudTrail and CloudWatch as knowledge sources, has separate tables for writing (authentic in uncooked JSON file format) and studying (read-optimized readready in remodeled Apache ORC file format), and offers you management over the elements so you possibly can customise it for your self.
The next diagram exhibits the system structure.
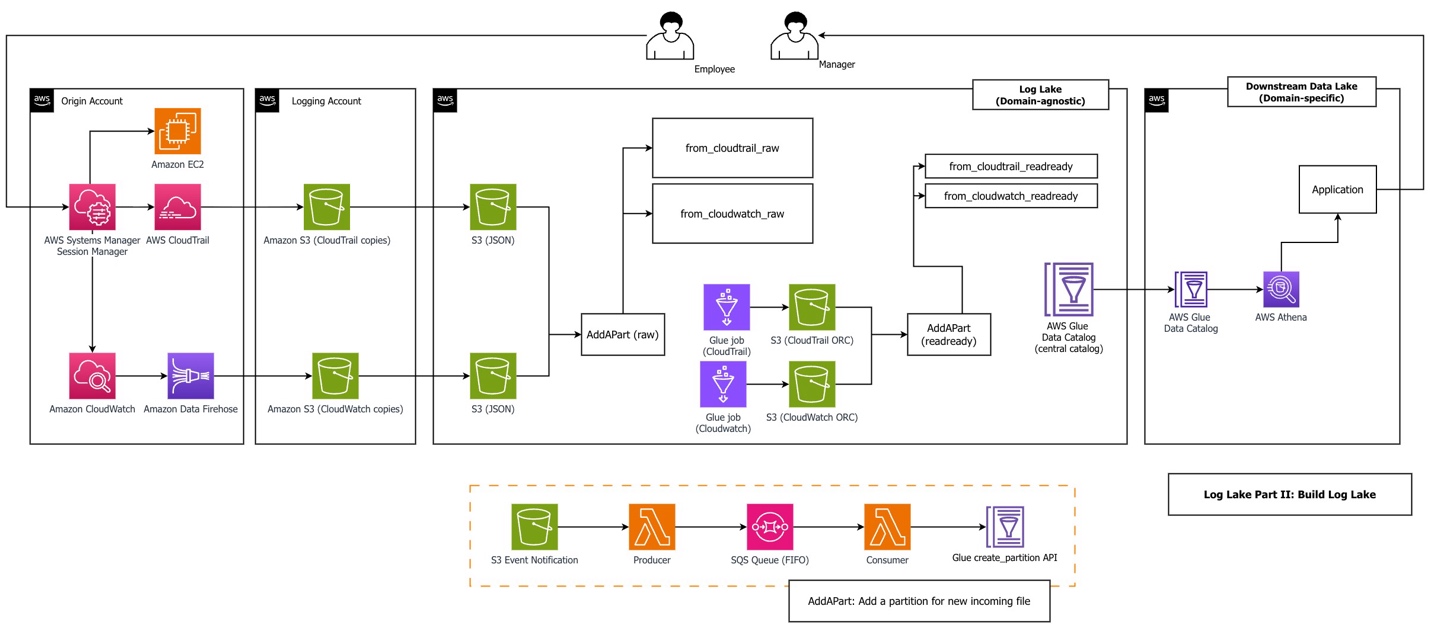
The workflow consists of the next steps:
- An worker makes use of Session Supervisor to entry Amazon Elastic Compute Cloud (Amazon EC2). Classes would possibly embody sessionContext.sourceIdentity if a principal offered it whereas assuming a job (requires
sts:SetSourceIdentitywithin the position belief coverage). Our AWS Glue jobs filtered on this discipline to scale back value and enhance efficiency. - Logging in to an EC2 occasion utilizing Session Supervisor and performing actions throughout a session triggers two sorts of logs: CloudTrail data API exercise (
StartSession) and CloudWatch data session knowledge from throughout the service (sessionData). Pattern CloudTrail and CloudWatch log information are within the GitHub repository, generated from an actual Techniques Supervisor session. We advocate you add these information in your first deployment, however alternatively, you possibly can generate your personal knowledge information. - An Amazon Knowledge Firehose subscription copies logs to Amazon Easy Storage Service (Amazon S3) utilizing a CloudWatch subscription filter. CloudWatch combines a number of log occasions into one Firehose document when it’s despatched utilizing subscription filters. That is why Log Lake makes use of regex serde to course of CloudWatch somewhat than JSON serde. When utilizing Firehose subscription filters, Firehose compresses knowledge with GZIP stage 6 compression.
- Optionally, replication guidelines copy information to consolidated S3 buckets.
- The AddAPart AWS Lambda perform associates many tiny JSON information with uncooked Hive tables within the Knowledge Catalog utilizing the AWS Glue API, triggered by S3 occasion notifications.
- The AWS Glue job reads uncooked tables and writes to larger binary ORC information, a columnar file format appropriate for analytics. Amazon Athena wants JSON paperwork on separate traces for processing. In our benchmarking utilizing CloudWatch and CloudTrail workloads, ORC ZLIB had the quickest (lowest) question length, and was half the file dimension of Parquet Snappy (1246 MB ORC ZLIB vs 2.4GB Parquet Snappy). Additionally, ORC is utilized by AWS CloudTrail Lake. To check file codecs, logs from CloudTrail Techniques Supervisor (
eventsource="ssm.amazonaws.com") have been copied to generate a complete inhabitants of JSON information over 500 GB. First, a JSON desk was created. Then two extra tables have been created utilizing Athena CTAS: one for ORC ZLIB, and one for Parquet Snappy. Checks in contrast three subsequent question durations for 3 totally different workloads throughout ORC vs. Parquet. - The AddAPart Lambda perform associates ORC information with Hive readready tables. AddAPart for readready is created utilizing the identical stack as for uncooked, however totally different parameters (bucket, desk, and so forth). Hive desk format was used for uncooked as a result of incoming information have been JSON, and readready used Hive (not Iceberg) for consistency and append solely operations.
- Customers can question readready tables utilizing the Athena API.
Log Lake makes use of a number of companies collectively:
- CloudTrail logs for StartSession API exercise (required for auditing, compliance, authorized functions)
- CloudWatch logs to increase and add keystrokes from Session Supervisor, so what occurred inside a session could be reviewed for applicable use
- Lambda and Amazon Easy Queue Service (Amazon SQS) for asynchronous invocation of S3 occasion notifications, for serverless event-driven processing to affiliate knowledge information with metadata tables
- The Knowledge Catalog as a metastore to register desk metadata, both standalone or as a part of a knowledge mesh structure
- AWS Glue Spark jobs to remodel knowledge from authentic uncooked format to read-optimized tables
- Athena for one-time queries
The structure of Log Lake contains the next design decisions:
- Separate tables for writing (uncooked) and studying (readready).
- Asynchronous invocation utilizing Lambda and Amazon SQS so as to add partitions for information (AddAPart).
- AWS Glue jobs with Spark SQL and views (“many view”).
- AWS companies designed to do one factor nicely, resembling Amazon S3 for storage and Amazon SQS for message queueing. This provides knowledge engineers management over elements for value or customization.
Separate tables for studying (readready) and writing (uncooked)
The idea of uncooked and readready tables represents two distinct approaches to knowledge storage and processing, every serving totally different functions in an information structure:
- Uncooked tables – Supply-aligned and write-optimized. They’re backed by many tiny information (KB in dimension) in authentic format. For CloudWatch and CloudTrail, this implies JSON file format.
- ReadReady tables – Supply-aligned and read-optimized. They’re backed by greater binary information, normally bigger than 10 MB, in columnar file format.
Half I accommodates our comparability of efficiency, value, and comfort of each desk layers.
Add partition Lambda capabilities (AddAPart)
Log Lake makes use of an event-based, asynchronous invocation strategy so as to add partitions to uncooked tables. We name this strategy “AddAPart with LoLLs” (Numerous Little Lambdas). It’s optimized for including new incoming information in textual content format to current Hive tables as quick as attainable, with the next assumptions:
- Incoming uncooked information are in JSON or CSV and should be saved and queried in authentic format (can’t be modified to Iceberg-compatible codecs resembling Parquet or ORC). Append solely, not merge or replace.
- Partition administration should be computerized.
- File-based, no dependency on a job (information could be landed by totally different pipelines in several methods, and dealt with persistently by the identical AddAPart perform).
- No dependency on Athena partition projection (Knowledge Catalog solely).
The AddAPart perform consists of 5 steps:
- An S3 occasion notification triggers the AddAPart producer Lambda perform.
- The AddAPart producer sends messages to a first-in-first-out (FIFO) SQS queue.
- Amazon SQS helps forestall duplicate messages utilizing MessageDeduplicationId.
- The AddAPart client processes a message and interprets it to a partition placer profile.
- The AddAPart client makes use of the AWS Glue API to create a partition if none exists.
The next are some methods we have now used AddAPart:
- Minimizing the time it takes to affiliate new knowledge (JSON information) with new partitions (desk in Hive).
- Decreasing the price of partition including (duplicate S3 prefixes are ignored).
- Altering file names (Knowledge Firehose postprocessing Lambda capabilities are another).
- Customization, resembling ignoring information with sure regex patterns within the S3 prefix or file title. If you wish to exclude an information supply or do an emergency energy off, you are able to do it from inside AddAPart with out modifying different assets.
“Many view” AWS Glue jobs
Each Log Lake jobs are what we name “many view” AWS Glue jobs, which use createOrReplaceTempView from Spark, utilizing code like the next:
Now we have used this strategy to handle the next antipatterns:
- Making an attempt to do every little thing in a single step – Making an attempt to do all operations and relational algebra in a single Spark SQL assertion can turn out to be too complicated to troubleshoot, perceive, or keep. For us, after we see a single assertion with at the least 200 traces and a pair of subqueries, we choose to interrupt it down into smaller statements.
- Code that isn’t standardized (inconsistent APIs and approaches) that’s tougher to take care of, help, and improve – Now we have seen the liberty of Spark to combine API approaches (Spark SQL API, RDD API, DataFrame API) lead to inconsistency and complexity in massive code bases with many contributors.
- Mixing enterprise logic with Spark atmosphere (resembling session settings) – Enterprise logic ought to be separate and transportable.
AWS Glue jobs with customized bounded execution and tables that help workload partitioning
You possibly can inform AWS Glue jobs to take a look at a most of n days or n rows with customized bounds, which we implement utilizing Spark Knowledge Frames as follows:
Additionally, jobs can prune knowledge utilizing desk partitions (and use partition indexes). This helps you put together routine mechanisms up entrance which might be able to run and get well from lacking knowledge by operating relative backfill jobs till knowledge is updated.
Stipulations
Full the next prerequisite steps to implement this answer:
- Obtain the repository:
- Create or establish an S3 bucket to make use of through the walkthrough. This shall be used for storing the AWS Glue job scripts, Lambda Python information, and AWS CloudFormation stacks.
- Copy all information underneath
log_laketo the S3 bucket. - If the S3 bucket is encrypted utilizing an AWS Key Administration Service (AWS KMS) key, be aware the Amazon Useful resource Identify (ARN) of the important thing.
Construct Log Lake
To construct Log Lake, comply with the deployment steps within the how_to_deploy.md file within the repo.
After deployment is full, you possibly can add demo knowledge information and run the AWS Glue jobs to demo how one can reply the query, “Who did what in session supervisor?” For this, swap over to the how_to_demo.md file and comply with the steps.
When you find yourself finished, you must see the next tables within the Knowledge Catalog:
- from_cloudtrail_readready – Accommodates processed CloudTrail session knowledge
- from_cloudwatch_readready – Accommodates processed CloudWatch session logs
You possibly can view them on the AWS Glue console or question them instantly in Athena. The next is a pattern question from the repository that exhibits how one can be part of each tables to get API exercise from CloudTrail and be part of it to session knowledge (keystrokes) from CloudWatch:
Add Amazon Bedrock mannequin invocation logs
Including Bedrock mannequin invocation logs to Log Lake is vital to allow human assessment of agent actions with elevated permissions. Some examples of the necessity for human oversight are device use, pc use, agentic misalignment, and excessive influence AI in federal companies. In case you have not thought-about this use case and are utilizing LLMs, we urge you to assessment Amazon Bedrock logs and think about both a managed product or a self-built knowledge lake like Log Lake.
On this put up, we use “agentic” and “agent” to check with a big language mannequin (LLM) utilizing instruments with some autonomy to iterate towards a purpose.
To generate mannequin invocation logs for this put up, we created a customized Lambda perform to ask Anthropic’s Claude 4.5 to listing information in a bucket utilizing a device. We used this as a believable future state of affairs the place a human would possibly must assessment an agent’s actions and logs to resolve if an agent’s device use was applicable.
The next diagram exhibits the elements concerned.
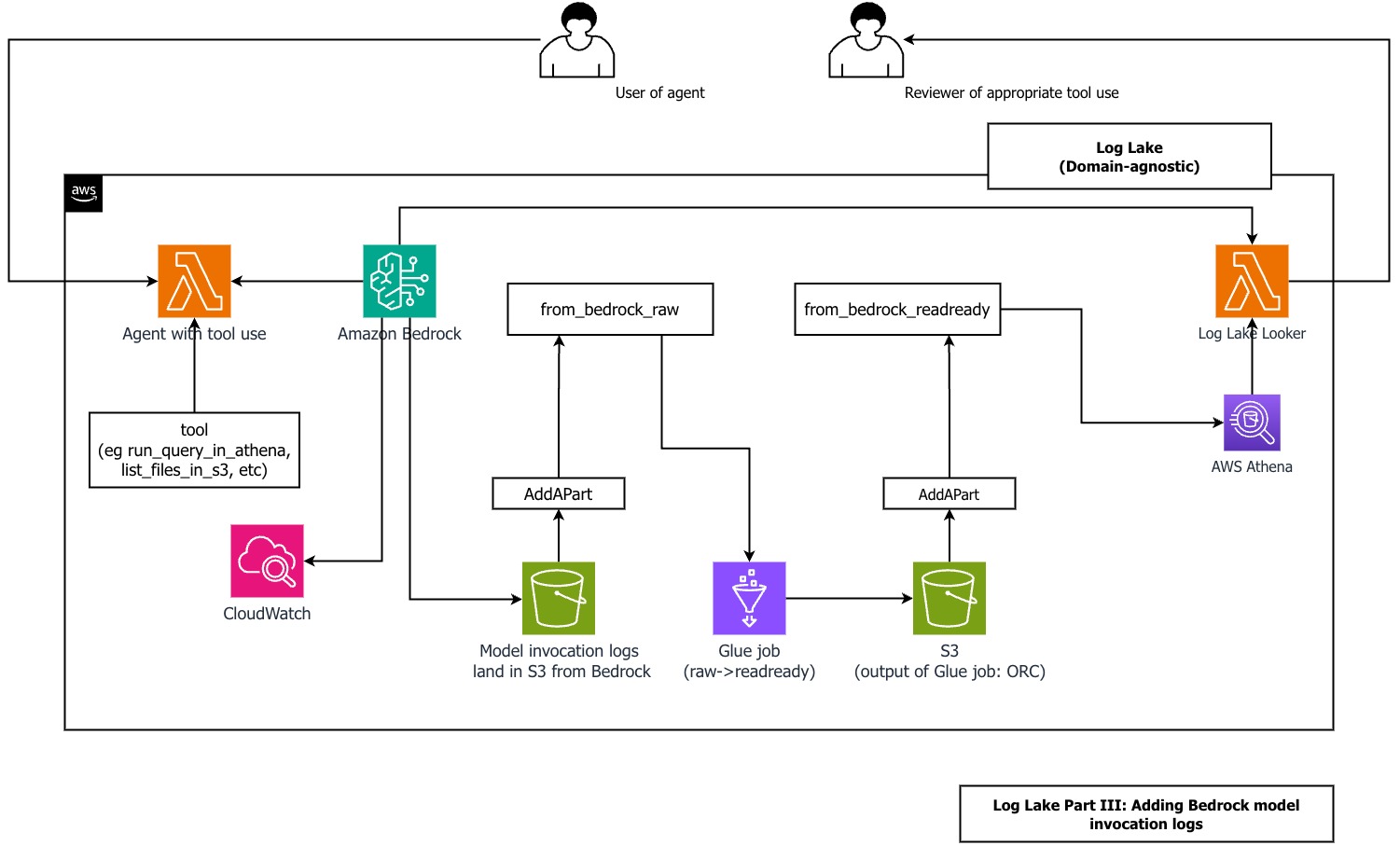
For logging inputs and outputs of LLMs operating on Bedrock, check with Monitor mannequin invocation utilizing CloudWatch Logs and Amazon S3. For simplicity, we prevented CloudWatch logs and arrange logging on to Amazon S3.
For logging API exercise for Amazon Bedrock, check with Monitor Amazon Bedrock API calls utilizing CloudTrail.
Now we have included examples of the CloudTrail and CloudWatch information from Amazon Bedrock mannequin invocation logs within the repository.
Earlier than you create the mannequin invocation logs, ensure you have created the from_cloudtrail_readready desk from the earlier steps.
Observe the steps within the GItHub repo so as to add Amazon Bedrock mannequin invocation logs to Log Lake. When finished, you must have the deskreplace_me_with_your_database.from_bedrock_readready.
You possibly can question this desk utilizing Athena and be part of it to from_cloudtrail_readready, utilizing SQL like the next instance from the repo:
Use an agent to assessment an agent
The predefined question we utilized in our demo is what we used after we knew the needle within the haystack (tool_use in enter messages), however this strategy wouldn’t work for brand spanking new, unknown patterns that require operating SQL queries in a number of steps to grasp complicated knowledge.
Our answer features a methodology for an agent in Amazon Bedrock to assessment an agent in Amazon Bedrock. On this put up’s repository, we embody a Log Lake Looker Lambda perform, which makes use of an LLM (Anthropic’s Claude) to speak to a database (the Log Lake AWS Glue database).
This sample shouldn’t be new. It has been described in 2024 within the paper DB-GPT: Empowering Database Interactions with Non-public Massive Language Fashions as “a paradigm shift in database interactions, providing a extra pure, environment friendly, and safe method to have interaction with knowledge repositories.” That is an extension of an older thought from 1998: an interface to knowledge was described within the Distributed Computing Manifesto as “the consumer is now not depending on the underlying knowledge construction and even the place the info is positioned.”
Utilizing an agent to question Log Lake has a number of advantages:
- An engineered agent can ship constant, dependable, high-quality solutions throughout hectic conditions, resembling a time-sensitive incident response or high-visibility investigation
- Customers don’t have to put in writing their very own queries and may scale back their cognitive load (“What was that lengthy column title?”)
- It may well scale back onboarding and coaching time (the agent implements the coaching and specialised information of the info constructions)
You possibly can ask Log Lake Looker an open-ended query and get a solution with out writing a question. Log Lake Looker performs the next actions for you:
- Create a legitimate SQL question from a pure language consumer immediate. Log Lake Looker is optimized for the
from_bedrock_readreadydesk utilizing a system immediate, just like the Anthropic SQL sorcerer instance. - Run the question in Athena utilizing a customized device.
- Assessment device outcomes (rows) and replies with a easy abstract.
When utilizing enter and output that may be verbose, like question outcomes, you would possibly must handle tokens in your context window. For instance, if the sum of enter and output tokens exceeds the mannequin’s context window, newer Claude fashions return a validation error, resembling the next error we noticed throughout testing: - Compact context by eradicating device outcomes. This improves time to reply efficiency, high quality of reply, and reduces proliferation of doubtless delicate knowledge to mannequin invocation logs.
- Both run a follow-up question or counsel subsequent steps for the human consumer.
Log Lake Looker seems at small samples from from_bedrock_readready utilizing a couple of strive. This implies the mannequin displays on its output and may create a follow-up question based mostly on question outcomes. To study extra about this, we advocate studying about reflection and iterative refinement. Now we have seen helpful responses from brokers utilizing iterative approaches, particularly when context is managed (for instance, a selected system immediate utilizing one desk solely or a restrict on conversational turns) and power outcomes are compacted.
We’ve seen the agent reply easy questions like “are you able to question my desk and inform me what you discover?” in lower than 60 seconds greater than 50% of the time, with out optimizing for any particular query. The next are snippets of CloudWatch logs to indicate you what’s attainable, utilizing Anthropic’s Claude Sonnet 4.5:
Safety
Log Lake Looker ought to be reviewed by a human for applicable device use, as a result of it has the identical dangers as the opposite brokers utilizing instruments or a human with elevated privileges. Looker can assessment its personal device use, however human assessment continues to be wanted.
There are safety implications of permitting an agent to assessment mannequin invocation logs: these logs can include system prompts, delicate knowledge in responses, and consumer enter in requests. Additionally, permitting an agent to generate SQL statements based mostly on consumer enter has extra dangers particular to entry to structured knowledge, resembling immediate injection, improper content material, and proliferation of delicate knowledge.
We advocate a protection in depth (a couple of layer) strategy for device use by a mannequin. Log Lake Looker makes use of a number of layers of defensive measures:
- The appliance code requires the SQL assertion to start with
chooseprevious to sending to Athena. As a result of the question is from an assistant response to a consumer enter (request), this pertains to sanitizing and validating consumer inputs and mannequin responses. - The AWS Identification and Entry Administration (IAM) position utilized by the perform has
glue:Get*actions solely (no mutation, resembling create, replace, delete tables, partitions, or databases), for least-privilege permissions. - It’s solely used interactively as a part of ad-hoc human-in-the-loop assessment (not in bulk or systemic).
- System prompting to steer habits, like this instance from the repo:
- The bucket storing mannequin invocation logs is safe and follows least privilege practices. Logs can include proliferation of delicate knowledge, resembling device outcomes, consumer inputs, mannequin outputs, and system prompts. If a system immediate accommodates delicate data (resembling metadata or question data not in any other case out there) and is saved to logs in an unsecure bucket, this can lead to a system immediate leak.
- Stripping device outcomes to scale back proliferation, utilizing code to truncate content material:
- You need to use Amazon Bedrock Guardrails (with out invoking the mannequin in software code) utilizing the ApplyGuardrail API.
Clear up
To keep away from incurring future prices, delete the stacks. The repository has shell scripts you should utilize to delete information in buckets, which is required earlier than deleting buckets.
Conclusion
On this put up, we confirmed you how one can deploy Log Lake in a brand new AWS account to create two tables, from_cloudtrail_readready and from_cloudwatch_readready. These tables can reply the query “What did an worker do in Session Supervisor?” throughout massive knowledge volumes in seconds utilizing Athena.
Moreover, we confirmed how one can add an information supply to an current Log Lake: Amazon Bedrock mannequin invocation logs within the type of from_bedrock_readready. This exhibits how Log Lake could be prolonged to reply questions resembling “What instruments did an agent use?” and “Was there inappropriate use, and why?”
Lastly, we confirmed how one can create and use Log Lake Looker, an agent utilizing Lambda and Amazon Bedrock. Looker can question Log Lake for brand spanking new unknown patterns as a part of human-in-the-loop assessment, with out writing SQL or remembering column names. You can also make Log Lake your approach. We encourage you to look via the repository and use it as inspiration in your personal Log Lake. In case you have questions or feedback, please tell us!
In regards to the authors

{kind=link}