
Organizations more and more rely upon trusted, high-quality knowledge to drive analytics, regulatory reporting, and operational decision-making. When knowledge high quality points go undetected, they will result in inaccurate insights, stalled initiatives, and compliance gaps that immediately have an effect on enterprise outcomes. As knowledge volumes develop and pipelines develop into extra distributed, sustaining constant knowledge high quality throughout groups and knowledge domains turns into progressively more difficult.
You possibly can deal with these challenges with AWS Glue Information High quality by offering automated, rule-based knowledge validation throughout datasets within the AWS Glue Information Catalog and inside AWS Glue ETL pipelines. With the Information High quality Definition Language (DQDL), you possibly can creator each easy and superior validation guidelines to detect knowledge high quality points early within the lifecycle, earlier than they attain downstream purposes or analytics environments.
On this publish, we spotlight the brand new DQDL labels characteristic, which reinforces the way you set up, prioritize, and operationalize your knowledge high quality efforts at scale. We present how labels comparable to enterprise criticality, compliance necessities, staff possession, or knowledge area might be hooked up to knowledge high quality guidelines to streamline triage and evaluation. You’ll discover ways to shortly floor focused insights (for instance, “all high-priority buyer knowledge failures owned by advertising and marketing” or “GDPR-related points from our Salesforce ingestion pipeline”) and the way DQDL labels might help groups enhance accountability and speed up remediation workflows.
Managing complicated knowledge high quality guidelines throughout groups and use circumstances
As organizations advance of their knowledge high quality packages, a couple of guidelines usually develop into lots of or hundreds maintained throughout many groups and enterprise domains. Take the instance of AnyCompany, a big retail group with a number of knowledge groups managing buyer, product, and gross sales knowledge throughout completely different enterprise models. These groups run quite a lot of knowledge high quality guidelines, together with weekly buyer checks, every day product validations, frequent gross sales checks, and month-to-month compliance evaluations, with completely different naming patterns, schedules, and response processes. This creates a fragmented, hard-to-navigate system the place groups function in isolation and knowledge high quality practices develop into inconsistent.
The problem lies within the quantity of guidelines and the dearth of organizational context round them. When dozens of information high quality guidelines go or fail, groups nonetheless lack readability on possession, urgency, or enterprise impression. This slows incident response, limits govt perception, and complicates useful resource planning. To maneuver from technical monitoring to strategic worth, organizations want a unified construction that connects knowledge high quality guidelines to groups, domains, and priorities, bringing important enterprise context to knowledge high quality operations.
Metadata-driven rule group
AWS Glue DQDL labels deal with organizational challenges as a result of you possibly can connect customized metadata to knowledge high quality guidelines, reworking nameless validations into contextually wealthy, business-aware checks. Labels work as key-value pairs hooked up to particular person guidelines or complete rule units, and you may set up high quality operations round enterprise dimensions comparable to staff possession, criticality, frequency, and regulatory necessities, as within the case of the AnyCompany instance. When a rule fails, you instantly establish what failed, who ought to reply, how pressing it’s, and which enterprise space is affected, whether or not it’s the advertising and marketing division monitoring e-mail completeness with every day frequency tags, compliance groups monitoring age verification with regulation labels, or the finance staff validating fee knowledge with high-criticality markers.
Labels combine with present DQDL syntax with out requiring adjustments to present rule definitions, working persistently throughout AWS Glue Information High quality execution contexts. The characteristic’s flexibility helps organizational taxonomies from value facilities and geographic areas to knowledge sensitivity ranges and service-level settlement (SLA) necessities with single guidelines carrying a number of labels concurrently for classy filtering and evaluation. Labels seem within the outputs, together with rule outcomes, row-level outcomes, and API responses, so organizational context travels with high quality outcomes whether or not you’re troubleshooting failures, analyzing traits in Amazon Athena, or constructing govt dashboards in Amazon Fast Sight.
Getting began: Writing your first labeled knowledge high quality guidelines
Let’s stroll via creating your first labeled knowledge high quality guidelines utilizing AnyCompany’s buyer knowledge situation. We’ll use their buyer demographics dataset, which accommodates buyer info that a number of groups must validate with completely different priorities and frequencies.
DQDL labels observe an easy key-value pair syntax that integrates naturally with present rule definitions. The fundamental syntax helps two approaches: default labels that apply to the foundations in a rule set, and rule-specific labels that apply to particular person guidelines. Rule-specific labels can override default labels when utilizing the identical key, offering fine-grained management over your labeling technique.
When implementing DQDL labels, preserve the next constraints in thoughts:
- Most of 10 labels per rule
- Label keys are restricted to 128 characters and may’t be empty
- Label values are restricted to 256 characters and may’t be empty
- Each keys and values are case-sensitive
- Rule-specific labels override default labels when utilizing the identical key
Utilizing this labeling method, you possibly can set up and handle knowledge high quality guidelines effectively throughout completely different groups and validation necessities.
Finest practices for label naming conventions
Listed here are some confirmed labeling methods that scale throughout enterprise environments:
- Set up an entire standardized taxonomy upfront – Outline label keys in DefaultLabels with wise defaults comparable to
regulation=noneorsla=24hto offer guidelines with an identical keys for cross-team queries. - Use constant key naming patterns – Set up customary keys comparable to
staff,criticality,sla,impression, andregulationthroughout rule units to take care of question consistency. - Implement hierarchical values – Use codecs comparable to
staff=marketing-analyticsto help each broad and particular filtering whereas holding key construction constant. - Embody operational metadata in defaults – Outline labels comparable to
sla,escalation-level, ornotification-channelas defaults to drive automated response workflows. - Plan for reporting dimensions – Embody keys comparable to
cost-center,area, orbusiness-unitin your default taxonomy to help significant enterprise analytics. - Use standardized worth patterns – Set up constant codecs comparable to
criticality=excessive/medium/loworsla=15m/1h/1dfor predictable filtering and sorting.
These are pointers relatively than necessities however following them from the beginning permits highly effective cross-team analytics and reduces future refactoring effort.
Buyer knowledge validation hands-on instance
This publish assumes you’re aware of AWS Glue Information High quality and ETL operations. Utilizing the next hands-on walkthrough, you’ll discover ways to implement DQDL labels for organizational knowledge high quality administration.
Begin by establishing default labels that robotically apply to each rule within the rule set, offering constant organizational context:
DefaultLabels present a foundational taxonomy that robotically propagates throughout your complete rule set, creating uniformity and lowering configuration overhead. By defining default values on the organizational stage, comparable to staff=data-team, criticality=medium, regulation=none, sla=24h, and impression=medium, each rule inherits these standardized attributes with out requiring express declaration. This inheritance mannequin promotes consistency whereas sustaining the pliability particular person groups want to deal with their distinctive operational contexts.
Particular person groups can selectively override inherited defaults to mirror their particular necessities. For instance, look at the next full rule set:
Discover how the compliance staff adjustments regulation from 'none' to 'age21' for age verification guidelines and analytics elevates criticality to 'excessive' for business-critical checks. Unspecified labels robotically inherit the default values, offering consistency whereas sustaining team-level flexibility.
Making use of labeled guidelines in opposition to the dataset
Now let’s see DQDL labels in motion by making use of AnyCompany’s rule set to precise knowledge via an AWS Glue ETL pipeline. This part assumes you’re aware of AWS Glue EvaluateDataQuality rework and fundamental extract, rework, and cargo (ETL) job creation.
We use AWS Glue EvaluateDataQuality rework inside an ETL job to course of our buyer dataset and apply our labeled rule set. The rework generates two sorts of outputs: rule-level outcomes that present which guidelines handed or failed with their related labels and row-level outcomes that establish particular data and the labeled guidelines they violated.
By default, labels are excluded from row-level outcomes. Nevertheless, by enabling them you possibly can analyze knowledge high quality outcomes at each the person report stage and throughout organizational dimensions comparable to groups and criticality ranges.
To allow labels in row-level outcomes, you need to configure the additionalOptions parameter in your EvaluateDataQuality rework. The important thing setting is "rowLevelConfiguration.ruleWithLabels":"ENABLED", which instructs AWS Glue to incorporate label metadata for every rule analysis on the particular person report stage.
Right here’s how one can implement an ETL pipeline that applies our AnyCompany’s rule set with labels enabled:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsgluedq.transforms import EvaluateDataQuality
from awsglue.dynamicframe import DynamicFrame
import boto3
def create_table(athena,s3_bucket,df,db_name,table_name):
ddl = spark.sparkContext._jvm.org.apache.spark.sql.varieties.DataType.fromJson(df.schema.json()).toDDL()
ddl_stmt_string=f"""CREATE EXTERNAL TABLE IF NOT EXISTS {db_name}.{table_name} ({str(ddl)}) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' LOCATION 's3://{s3_bucket}/label/{table_name}/'"""
athena.start_query_execution(QueryString=ddl_stmt_string,ResultConfiguration={'OutputLocation': f"s3://{s3_bucket}/athena_results/"})
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
guidelines="""
DefaultLabels = ["team"="data-team", "criticality"="medium", "regulation"="none", "sla"="24h", "impact"="medium"]
Guidelines = [
IsComplete "c_customer_id" labels=["team"="analytics", "criticality"="high", "sla"="15m", "impact"="high"],
ColumnValues "c_customer_id" matches "e.*" labels=["team"="analytics", "criticality"="medium", "impact"="low"],
ColumnLength "c_city" > 6 labels=["team"="marketing", "criticality"="medium", "sla"="4h", "impact"="medium"],
IsComplete "c_name" labels=["team"="marketing", "sla"="4h"],
ColumnValues "c_age" >= 21 labels=["team"="compliance", "criticality"="high", "regulation"="age21", "impact"="high"] with threshold > 0.99,
IsComplete "c_birth_date" labels=["team"="compliance", "criticality"="medium", "regulation"="gdpr", "impact"="medium"],
IsComplete "c_creditissuer" labels=["team"="finance", "impact"="high"],
ColumnValues "c_creditcardnumber" > 100000000000 labels=["team"="finance", "criticality"="high", "regulation"="payment", "impact"="high"] with threshold > 0.95
]
"""
s3_bucket="REPLACE"
row_level_table="dqrowlevel"
rule_level_table="dqrulelevel"
db_name="default"
additional_options={}
additional_options["observations.scope"]="ALL"
additional_options["performanceTuning.caching"]="CACHE_INPUT"
additional_options["rowLevelConfiguration.ruleWithLabels"]="ENABLED"
df = spark.learn.possibility("header", "true").possibility("inferSchema", "true").csv("s3://aws-data-analytics-workshops/aws_glue/aws_glue_data_quality/knowledge/clients/")
anycompany_customers=DynamicFrame.fromDF(df, glueContext, "anycompany_customers")
dq_check = EvaluateDataQuality().process_rows(body=anycompany_customers, ruleset=guidelines, publishing_options={"dataQualityEvaluationContext": "dq_check","enableDataQualityCloudWatchMetrics": True, "enableDataQualityResultsPublishing": True}, additional_options=additional_options)
rowlevel = SelectFromCollection.apply(dfc=dq_check, key="rowLevelOutcomes", transformation_ctx="rowlevel")
rulelevel = SelectFromCollection.apply(dfc=dq_check, key="ruleOutcomes", transformation_ctx="rulelevel")
rowlevel_df=rowlevel.toDF()
rulelevel_df=rulelevel.toDF()
rowlevel_df.write.mode("overwrite").parquet(f"s3://{s3_bucket}/label/{row_level_table}/")
rulelevel_df.write.mode("overwrite").parquet(f"s3://{s3_bucket}/label/{rule_level_table}/")
athena = boto3.consumer('athena')
create_table(athena,s3_bucket,rowlevel_df,db_name,row_level_table)
create_table(athena,s3_bucket,rulelevel_df,db_name,rule_level_table)
job.commit()To run this instance, replace the s3_bucket variable with your personal Amazon Easy Storage Service (Amazon S3) bucket title, then create and execute the ETL job in AWS Glue.
After the job is accomplished, you’ll discover:
- Rule-level and row-level outcomes saved in your S3 bucket
- Two new tables robotically created in your default database:
dqrulelevelanddqrowlevel
Within the subsequent part, we question these tables utilizing Amazon Athena to investigate the labeled knowledge high quality outcomes and extract actionable insights.
Analyzing knowledge high quality outcomes by labels utilizing Amazon Athena
We’ve saved our labeled knowledge high quality ends in Amazon S3 and as a desk within the AWS Glue knowledge catalog. Now, we are able to use Amazon Athena to investigate these outcomes throughout the organizational dimensions captured in your labels. The labeled metadata transforms uncooked knowledge high quality outcomes into actionable enterprise intelligence that drives focused remediation and strategic decision-making.
Querying row-level outcomes
With labels saved alongside row-level end result, you possibly can question particular data that failed knowledge high quality checks primarily based on label standards. For instance, the next question identifies particular person buyer data that failed excessive criticality compliance guidelines. You need to use it to shortly find and remediate problematic knowledge for regulatory or business-critical use circumstances:

You possibly can see the question outcomes above exhibiting failed data filtered by 'excessive' criticality and 'compliance' staff labels.
Querying rule-level outcomes
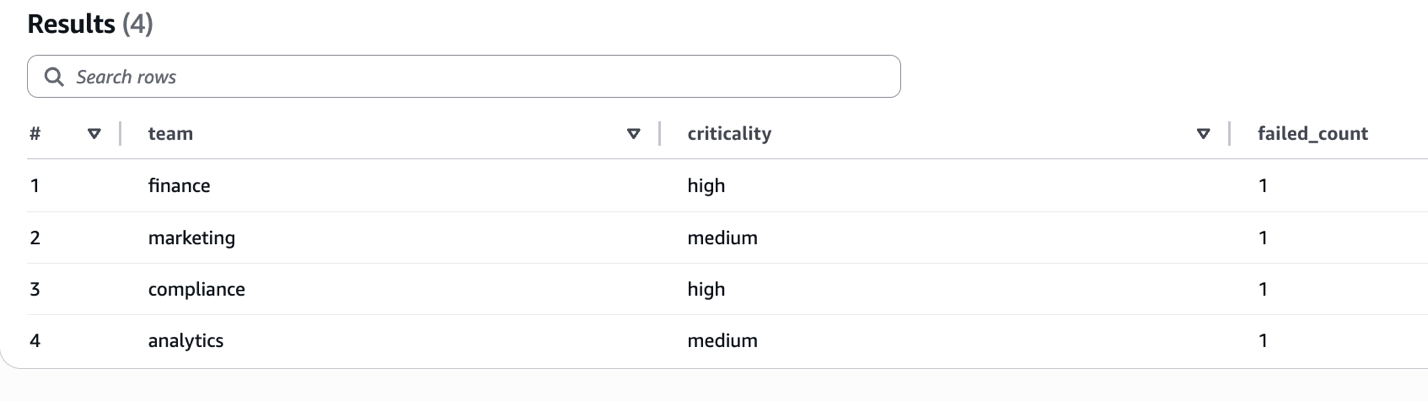
Now that we’ve saved rule-level outcomes with labels, we are able to run aggregation queries to investigate failures throughout completely different dimensions. For instance, the next question teams failed guidelines by criticality and staff to establish which groups have essentially the most high-severity failures. You need to use it to prioritize remediation efforts and allocate assets successfully:
The next screenshot reveals aggregated failure counts grouped by staff and criticality stage.
Viewing knowledge high quality outcomes utilizing AWS CLI
Past querying ends in Athena, you can even retrieve knowledge high quality outcomes immediately utilizing the AWS Command Line Interface (AWS CLI). That is helpful for automation, scripting, and integrating knowledge high quality checks into steady integration and steady supply (CI/CD) pipelines.
To checklist knowledge high quality outcomes in your ETL job, enter the next:
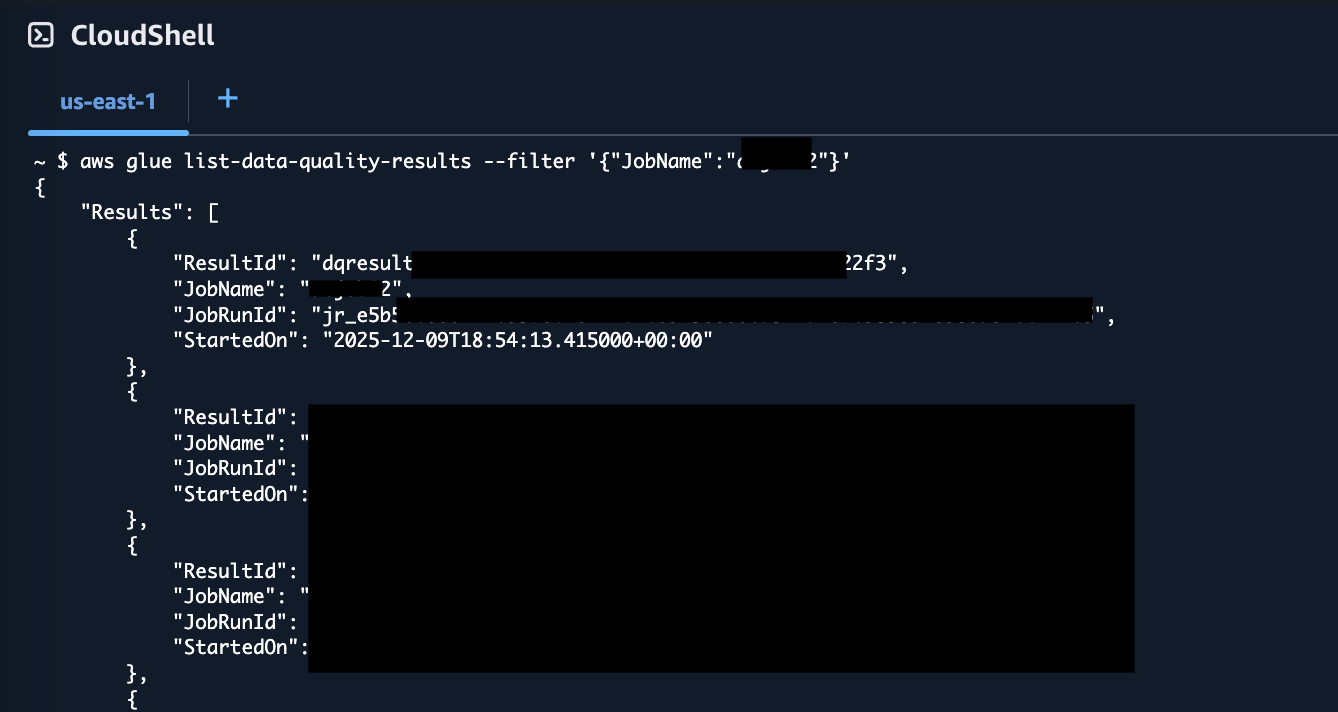
You possibly can see within the above screenshot that the resultant JSON features a ResultId for every knowledge high quality run.
To retrieve particulars of a selected outcome, enter the next:
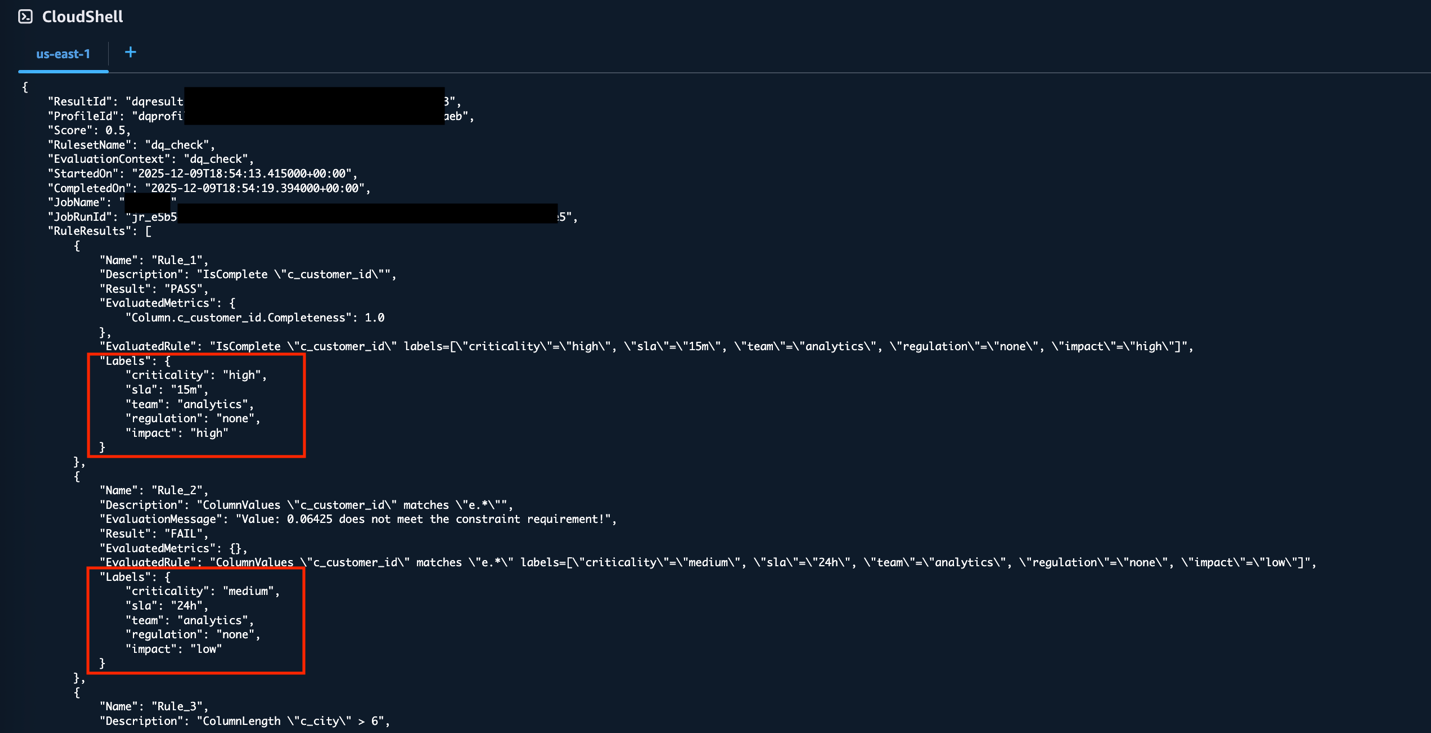
The output features a Labels object for every rule within the RuleResults array, containing the label key-value pairs you outlined. This offers programmatic entry to the identical labeled knowledge high quality outcomes, which might be helpful for automation and scripting workflows.
Cleanup
To keep away from incurring ongoing costs, delete the assets created on this publish:
- To delete the S3 folders containing the info high quality outcomes, observe the instructions at Deleting Amazon S3 objects.
- To delete the ETL job you created for the take a look at, observe the instructions at Delete jobs within the AWS Glue Consumer Information.
- To delete the AWS Glue Information Catalog
dqrulelevelanddqrowleveltables, observe the instructions at DeleteTable within the AWS Glue Net API Reference.
Conclusion
AWS Glue DQDL labels add organizational context to knowledge high quality administration by attaching enterprise metadata on to validation guidelines. This helps groups establish rule possession, prioritize failures, and coordinate remediation efforts extra successfully.All through this publish, we’ve seen how AnyCompany moved from managing lots of of generic guidelines to implementing a labeled system the place knowledge high quality outcomes embody staff possession and enterprise context. Advertising groups can establish their e-mail validation failures, compliance groups can deal with regulatory violations, and finance groups can deal with payment-related points with out handbook coordination.To implement DQDL Labels in your group:
- Begin easy – Start with fundamental organizational dimensions comparable to staff possession, criticality ranges, and SLA necessities. Develop your labeling method as wanted.
- Set up requirements – Outline your label taxonomy up entrance, together with default values for unused dimensions. This consistency helps analytics throughout groups.
- Combine progressively – Add labels to present rule units throughout routine upkeep.
- Use analytics – Apply the Athena question patterns from this publish to construct instruments comparable to dashboards and alerting workflows.
- Construct sensible automation – Discover creating alerts and notifications tailor-made to your enterprise criticality and SLA definitions. For instance, configure rapid notifications for high-criticality compliance failures whereas batching low-priority advertising and marketing points into every day studies.
We stay up for seeing the way you implement DQDL labels in your group and develop past the examples we’ve lined right here. To dive into the AWS Glue Information High quality APIs, discuss with Information High quality API documentation. To study extra about AWS Glue Information High quality, take a look at AWS Glue Information High quality.
Concerning the authors

{kind=link}