
Job descriptions of Knowledge Engineering roles have modified drastically through the years. In 2026, these learn much less like information plumbing and extra like manufacturing engineering. You’re anticipated to ship pipelines that don’t break at 2 AM, scale cleanly, and keep compliant whereas they do it. So, no – “I do know Python and Spark” alone doesn’t minimize it anymore.
As a substitute, immediately’s stack is centred round cloud warehouses + ELT, dbt-led transformations, orchestration, information high quality assessments that truly fail pipelines, and boring-but-critical disciplines like schema evolution, information contracts, IAM, and governance. Add lakehouse desk codecs, streaming, and containerised deployments, and the talent bar goes very excessive, very quick.
So, should you’re beginning in 2026 (and even revisiting your plan to develop into an information engineer), this roadmap is for you. Right here, we cowl a month-by-month path to studying one of the best expertise which are required in immediately’s information engineering roles. If you happen to grasp these, you’ll develop into employable and never simply “tool-aware.” Let’s bounce proper in and discover all that’s obligatory in probably the most systematic means attainable.
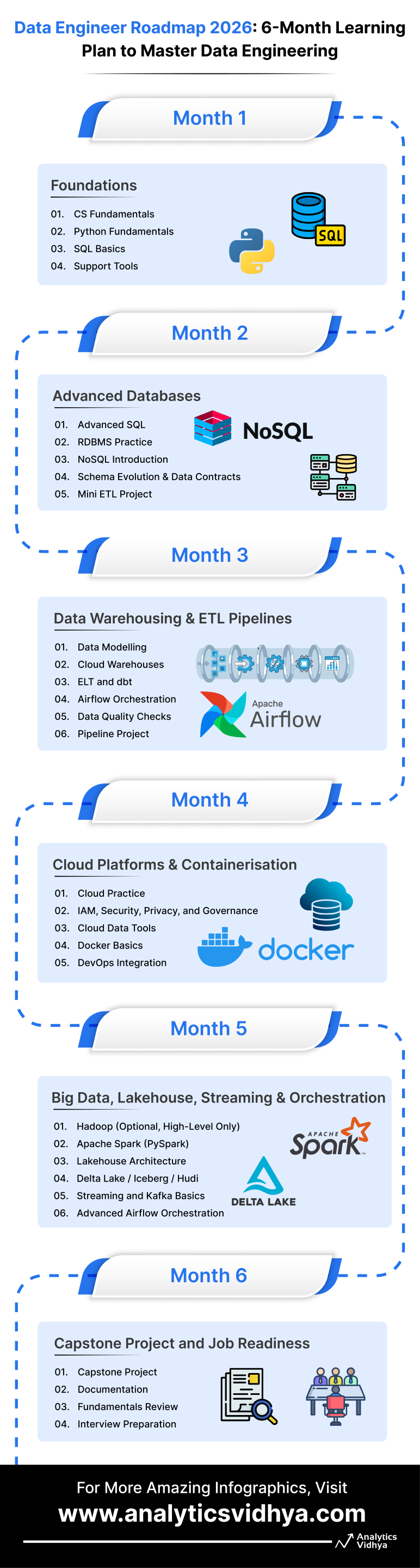
Month 1: Foundations
To Be taught: CS Fundamentals, Python, SQL, Linux, Git
Let’s be sincere. Month 1 shouldn’t be the “thrilling” month. There isn’t a Spark cluster, shiny dashboards, or Kafka streams. However should you skip this basis, all the things that follows on this roadmap to turning into an information engineer turns into more durable than it must be. So begin early, begin robust!
CS Fundamentals
Begin with laptop science fundamentals. Be taught core information constructions like arrays, linked lists, timber, and hash tables. Add fundamental algorithms like sorting and looking. Be taught time complexity so you possibly can decide whether or not your code will scale nicely. Additionally, be taught object-oriented programming (OOP) ideas, as a result of most actual pipelines are constructed as reusable modules and never single-use scripts.
Python Fundamentals
Subsequent, get strong with Python programming. Deal with clear syntax, features, management move, and writing readable code. Be taught fundamental OOP, however extra importantly, construct the behavior of documenting what you write. In 2026, your code shall be reviewed, maintained, and reused. So deal with it like a product, not a pocket book experiment.
SQL Fundamentals
Alongside Python, begin SQL fundamentals. Be taught SELECT, JOIN, GROUP BY, subqueries, and aggregations. SQL continues to be the language that runs the info world, and the quicker you get comfy with it, the simpler each later month turns into. Use one thing like PostgreSQL or MySQL, load a pattern dataset, and observe each day.
Assist Instruments
Lastly, don’t ignore the “supporting instruments.” Be taught fundamental Linux/Unix shell instructions (bash) as a result of servers and pipelines dwell there. Arrange Git and begin pushing all the things to GitHub/GitLab from day one. Model management shouldn’t be elective in manufacturing groups.
Month 1 Aim
By the tip of Month 1, your objective is easy: it’s best to be capable of write clear Python, question information confidently with SQL, and work comfortably in a terminal with Git. That baseline will carry you thru the whole roadmap.
Month 2: Superior Databases
To Be taught: Superior SQL, RDBMS Apply, NoSQL, Schema Evolution & Knowledge Contracts, Mini ETL Challenge
Month 2 is the place you progress from “I can write queries” to “I can design and question databases correctly.” In most information engineering roles, SQL is without doubt one of the foremost filters. So this month within the roadmap to turning into an information engineer is about turning into genuinely robust at it, whereas additionally increasing into NoSQL and fashionable schema practices.
Superior SQL
Begin upgrading your SQL talent set. Apply advanced multi-table JOINs, window features (ROW_NUMBER, RANK, LEAD/LAG), and CTEs. Additionally be taught fundamental question tuning: how indexes work, the best way to learn question plans, and the best way to spot gradual queries. Environment friendly SQL at scale is without doubt one of the most repeated necessities in information engineering job interviews.
RDBMS Apply
Choose a relational database like PostgreSQL or MySQL and construct correct schemas. Attempt designing a easy analytics-friendly construction, corresponding to a star schema (reality and dimension tables), utilizing a sensible dataset like gross sales, transactions, or sensor logs. This provides you hands-on observe with information modelling.
NoSQL Introduction
Now add one NoSQL database to your toolkit. Select one thing like MongoDB (doc retailer) or DynamoDB (key-value). Be taught what makes NoSQL totally different: versatile schemas, horizontal scaling, and quicker writes in lots of real-time techniques. Additionally perceive the trade-off: you typically quit advanced joins and inflexible construction for velocity and suppleness.
Schema Evolution & Knowledge Contracts
It is a 2026 talent that issues much more than it did earlier. Learn to deal with schema modifications safely: including columns, renaming fields, sustaining backward/ahead compatibility, and utilizing versioning. Alongside that, perceive the concept of knowledge contracts, that are clear agreements between information producers and shoppers, so pipelines don’t break when information codecs change.
Mini ETL Challenge
Finish the month with a small however full ETL pipeline. Extract information from a CSV or public API, clear and rework it utilizing Python, then load it into your SQL database. Automate it with a easy script or scheduler. Don’t goal for complexity. The objective, as an alternative, is to construct confidence in transferring information end-to-end.
Month 2 Aim
By the tip of Month 2, it’s best to be capable of write robust SQL queries, design smart schemas, perceive when to make use of SQL vs NoSQL, and construct a small and dependable ETL pipeline.
Month 3: Knowledge Warehousing & ETL Pipelines
To Be taught: Knowledge Modelling, Cloud Warehouses, ELT with dbt, Airflow Orchestration, Knowledge High quality Checks, Pipeline Challenge
Month 3 on this roadmap is the place you begin working like a contemporary information engineer. You progress past databases and enter real-world analytics, constructing warehouse-based pipelines at scale. That is additionally the month the place you be taught two essential instruments that present up in every single place in 2026 information groups: dbt and Airflow.
Knowledge Modelling
Begin with information modelling for analytics. Be taught star and snowflake schemas, and perceive why reality tables and dimension tables make reporting quicker and easier. You don’t want to develop into a modelling skilled in a single month, however it’s best to perceive how good modelling reduces confusion for downstream groups.
Cloud Warehouses
Subsequent, get hands-on with a cloud information warehouse. Choose one: BigQuery, Snowflake, or Redshift. Learn to load information, run queries, and handle tables. These warehouses are constructed for OLAP workloads and are central to most fashionable analytics stacks.
ELT and dbt
Now shift from traditional ETL pondering to ELT. In 2026, most groups load uncooked information first and do transformations contained in the warehouse. That is the place dbt turns into essential. Learn to:
- create fashions (SQL transformations)
- handle dependencies between fashions
- write assessments (null checks, uniqueness, accepted values)
- doc your fashions so others can use them confidently
Airflow Orchestration
After getting ingestion and transformations, you want automation. Set up Airflow (native or Docker) and construct easy Directed Acyclic Graphs or DAGs. Find out how scheduling works, how retries work, and the best way to monitor pipeline runs. Airflow isn’t just a “scheduler.” It’s the management centre for manufacturing pipelines.
Knowledge High quality Checks
It is a non-negotiable 2026 talent. Add automated checks for:
- nulls and lacking values
- freshness (information arriving on time)
- ranges and invalid values
Use dbt assessments, and if you’d like deeper validation, strive Nice Expectations. The important thing level: when information is dangerous, the pipeline ought to fail early.
Pipeline Challenge
Finish Month 3 with an entire warehouse pipeline:
- fetch information each day from an API or recordsdata
- load uncooked information into your warehouse
- rework it with dbt into clear tables
- schedule all the things with Airflow
- add information assessments so failures are seen
This challenge turns into a powerful portfolio piece as a result of it resembles an actual office workflow.
Month 3 Aim
By the tip of Month 3, it’s best to be capable of load information right into a cloud warehouse, rework it utilizing dbt, automate the workflow with Airflow, and add information high quality checks that stop dangerous information from quietly getting into your system.
Month 4: Cloud Platforms & Containerisation
To Be taught: Cloud Apply, IAM Fundamentals, Safety & Governance, Cloud Knowledge Instruments, Docker, DevOps Integration
Month 4 within the information engineer roadmap is the place you cease pondering solely about pipelines and begin desirous about how these pipelines run in the true world. In 2026, information engineers are anticipated to know cloud environments, fundamental safety, and the best way to deploy and preserve workloads in constant environments, and month 4 on this roadmap prepares you for simply that.
Cloud Apply
Choose one cloud platform: AWS, GCP, or Azure. Be taught the core providers that information groups use:
- storage (S3 / GCS / Blob Storage)
- compute (EC2 / Compute Engine / VMs)
- managed databases (RDS / Cloud SQL)
- fundamental querying instruments (Athena, BigQuery, Synapse-style querying)
Additionally be taught fundamental cloud ideas like areas, networking fundamentals (high-level is okay), and value consciousness.
IAM, Safety, Privateness, and Governance
Now deal with entry management and security. Be taught IAM fundamentals: roles, insurance policies, least privilege, and repair accounts. Perceive how groups deal with secrets and techniques (API keys, credentials). Be taught what PII is and the way it’s protected utilizing masking and entry restrictions. Additionally get accustomed to governance concepts like:
- row/column-level safety
- information catalogues
- governance instruments (Lake Formation, Unity Catalog)
You don’t want to develop into a safety specialist, however you need to perceive what “safe by default” appears to be like like.
Cloud Knowledge Instruments
Discover one or two managed information providers in your chosen cloud. Examples:
- AWS Glue, EMR, Redshift
- GCP Dataflow, Dataproc, BigQuery
- Azure Knowledge Manufacturing facility, Synapse
Even when you don’t grasp them, perceive what they do and what they’re changing (self-managed Spark clusters, guide scripts, and so on.).
Docker Fundamentals
Now be taught Docker. The objective is easy: package deal your information workload so it runs the identical in every single place. Containerise one factor you’ve already constructed, corresponding to:
- your Python ETL job
- your Airflow setup
- a small dbt challenge runner
Learn to write a Dockerfile, construct a picture, and run containers domestically.
DevOps Integration
Lastly, join your work to a fundamental engineering workflow:
- use Docker Compose to run multi-service setups (Airflow + Postgres, and so on.)
- arrange a easy CI pipeline (GitHub Actions) that runs checks/assessments on every commit
That is how fashionable groups maintain pipelines secure.
Month 4 Aim
By the tip of Month 4, it’s best to be capable of use one cloud platform comfortably, perceive IAM and fundamental governance, run an information workflow in Docker, and apply easy CI practices to maintain your pipeline code dependable.
Month 5: Huge Knowledge, Lakehouse, Streaming, and Orchestration
To Be taught: Spark (PySpark), Lakehouse Structure, Desk Codecs (Delta/Iceberg/Hudi), Kafka, Superior Airflow
Month 5 on this roadmap to turning into an information engineer is about dealing with scale. Even if you’re not processing large datasets on day one, most groups nonetheless count on information engineers to know distributed processing, lakehouse storage, and streaming techniques. This month builds that layer.
Hadoop (Elective, Excessive-Stage Solely)
In 2026, you don’t want deep Hadoop experience. However it’s best to know what it’s and why it existed. Be taught what HDFS, YARN, and MapReduce have been constructed for, and what issues they solved on the time. Bear in mind, solely research these in your consciousness. Don’t attempt to grasp them, as a result of most fashionable stacks have moved towards Spark and lakehouse techniques.
Apache Spark (PySpark)
Spark continues to be the default selection for batch processing at scale. Find out how Spark works with DataFrames, what transformations and actions imply, and the way SparkSQL matches into actual pipelines. Spend time understanding the fundamentals of partitioning and shuffles, as a result of these two ideas clarify most efficiency points. Apply by processing a bigger dataset than what you usually use Pandas for, and evaluate the workflow.
Lakehouse Structure
Now transfer to lakehouse structure. Many groups need the low-cost storage of an information lake, however with the reliability of a warehouse. Lakehouse techniques goal to supply that center floor. Be taught what modifications whenever you deal with information on object storage as a structured analytics system, particularly round reliability, versioning, and schema dealing with.
Delta Lake / Iceberg / Hudi
These desk codecs are an enormous a part of why lakehouse works in observe. Be taught what they add on high of uncooked recordsdata: higher metadata administration, ACID-style reliability, schema enforcement, and assist for schema evolution. You don’t want to grasp all three, however it’s best to perceive why they exist and what issues they remedy in manufacturing pipelines.
Streaming and Kafka Fundamentals
Streaming issues as a result of many organisations need information to reach constantly relatively than in each day batches. Begin with Kafka and learn the way matters, partitions, producers, and shoppers work collectively. Perceive how groups use streaming pipelines for occasion information, clickstreams, logs, and real-time monitoring. The objective is to know the structure clearly, to not develop into a Kafka operator.
Superior Airflow Orchestration
Lastly, stage up your orchestration expertise by writing extra production-style Airflow DAGs. You may attempt to:
- add retries and alerting
- run Spark jobs via Airflow operators
- arrange failure notifications
- schedule batch and near-real-time jobs
That is very near what manufacturing orchestration appears to be like like.
Month 5 Aim
By the tip of Month 5 as an information engineer, it’s best to be capable of run batch transformations in Spark, clarify how lakehouse techniques work, perceive why Delta/Iceberg/Hudi matter, and describe how Kafka-based streaming pipelines function. You also needs to be capable of orchestrate these workflows with Airflow in a dependable, production-minded means.
Month 6: Capstone Challenge and Job Readiness
To Be taught: Finish-to-Finish Pipeline Design, Documentation, Fundamentals Revision, Interview Preparation
Month 6 on this information engineer roadmap is the place all the things comes collectively. The objective is to construct one full challenge that proves you possibly can work like an actual information engineer. This single capstone will matter greater than ten small tutorials, as a result of it demonstrates full possession of a pipeline.
Capstone Challenge
Construct an end-to-end pipeline that covers the trendy 2026 stack. Right here’s what your Month 6 capstone ought to embrace. Maintain it easy, however be sure each half is current.
- Ingest information in batch (each day recordsdata/logs) or as a stream (API occasions)
- Land uncooked information in cloud storage corresponding to S3 or GCS
- Remodel the info utilizing Spark or Python
- Load cleaned outputs right into a cloud warehouse like Snowflake or BigQuery
- Orchestrate the workflow utilizing Airflow
- Run key elements in Docker so the challenge is reproducible
- Add information high quality checks for nulls, freshness, duplicates, and invalid values
Make certain your pipeline fails clearly when information breaks. This is without doubt one of the strongest indicators that your challenge is production-minded and never only a demo.
Documentation
Documentation shouldn’t be an additional activity. It’s a part of the challenge. Create a transparent README that explains what your pipeline does, why you made sure selections, and the way another person can run it. Add a easy structure diagram, an information dictionary, and clear code feedback. In actual groups, robust documentation typically separates good engineers from common ones.
Fundamentals Assessment
Now revisit the fundamentals. Assessment SQL joins, window features, schema design, and customary question patterns. Refresh Python fundamentals, particularly information manipulation and writing clear features. You must be capable of clarify key trade-offs corresponding to ETL vs ELT, OLTP vs OLAP, and SQL vs NoSQL with out hesitation.
Interview Preparation
Spend time practising interview-style questions. Clear up SQL puzzles, work on Python coding workout routines, and put together to debate your capstone intimately. Be prepared to clarify the way you deal with retries, failures, schema modifications, and information high quality points. In 2026 interviews, corporations care much less about whether or not you “used a instrument” and extra about whether or not you perceive the best way to construct dependable pipelines.
Month 6 Aim
By the tip of Month 6, it’s best to have an entire, well-documented information engineering challenge, robust fundamentals in SQL and Python, and clear solutions for frequent interview questions. As a result of now, you’ve utterly surpassed the training stage and are able to put your expertise to make use of in an actual job.
Conclusion
As I stated earlier than, in 2026, information engineering is not nearly figuring out instruments. It now revolves round constructing pipelines which are dependable, safe, and simple to function at scale. If you happen to comply with this six-month roadmap religiously and end it with a powerful capstone, there isn’t a means you gained’t be prepared as a modern-day information engineer.
Not simply on papers, you should have the abilities that fashionable groups really search for: strong SQL and Python, warehouse-first ELT, orchestration, information high quality, governance consciousness, and the power to ship end-to-end techniques. At that time of this roadmap, you should have already develop into an information engineer. All you’ll then want is a job to make it official.
Login to proceed studying and revel in expert-curated content material.

{kind=link}