
Most AI initiatives begin with one annoying chore: cleansing messy recordsdata. PDFs, Phrase docs, PPTs, pictures, audio, and spreadsheets all must be transformed into clear textual content earlier than they turn into helpful. Microsoft’s MarkItDown lastly fixes this downside. On this information, I’ll present you set up it, convert each main file sort to Markdown, run OCR on pictures, transcribe audio, extract content material from ZIPs, and construct cleaner pipelines to your LLM workflows with just a few traces of code.
Why MarkItDown Issues?
Earlier than we soar into the hands-on examples, it helps to grasp how MarkItDown truly converts totally different recordsdata into clear Markdown. The library doesn’t deal with each format the identical. As a substitute, it makes use of a wise two-step course of.
First, every file sort is parsed with the instrument greatest fitted to it. Phrase paperwork undergo mammoth, Excel sheets by way of pandas, and PowerPoint slides by way of python-pptx. All of them are transformed into structured HTML.
Second, that HTML is cleaned and reworked into Markdown utilizing BeautifulSoup. This ensures the ultimate output retains headings, lists, tables, and logical construction intact.
You’ll be able to add the picture right here to make the stream clear:
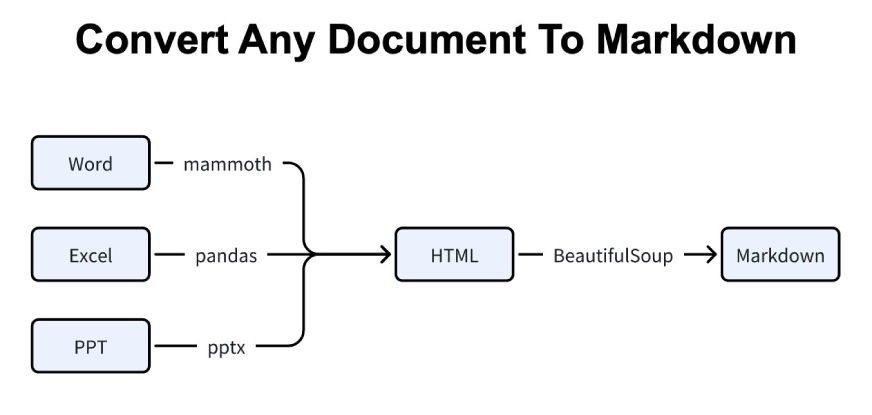
MarkItDown follows this pipeline each time you run a conversion, no matter how messy the unique doc is.
Learn extra about it in our earlier article on The way to Use MarkItDown MCP to Convert the Docs into Markdowns?
Set up and Setup of Microsoft’s MarkItDown
A Python atmosphere and pip are required to begin. Additionally, you will require an open AI API key in case you plan to course of pictures or audio.
In any terminal, the next command will set up the MarkItDown Python Library:
!pip set up markitdown[all] It’s higher to ascertain a digital atmosphere to forestall battle with different initiatives.
# Create a digital atmosphere
python -m venv venv
# Activate it (Home windows)
venvScriptsactivate
# Activate it (Mac/Linux)
supply venv/bin/activate After set up, import the library in Python to check it. You are actually able to convert recordsdata into Markdown
8 Issues To Do With Microsoft’s MarkItDown Library
MarkItDown helps most codecs. These are the examples of utilizing its utilization on frequent recordsdata.
Process 1: Changing MS Phrase Paperwork
Phrase paperwork generally embrace headers, daring textual content, and lists. MarkItDown preserves this formatting throughout conversion.
from markitdown import MarkItDown
md = MarkItDown()
res = md.convert("/content material/test-sample.docx")
print(res.text_content) Output:
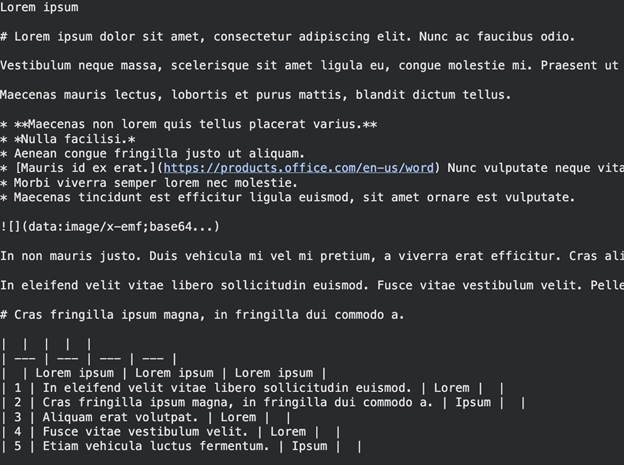
You can find the Markdown textual content. Headings are outlined by the letters # and lists by *. This type of construction assists the LLMs to grasp the construction of your paper.
Excel information is commonly required by information analysts. It’s a doc changing instrument that may convert spreadsheets into clear Markdown tables.
from markitdown import MarkItDown
md = MarkItDown()
outcome = md.convert("/content material/file_example_XLS_10.xls")
print(outcome.text_content) Output:
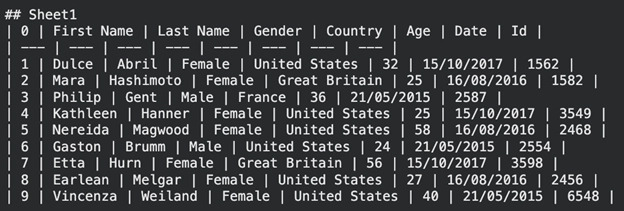
The data is offered within the type of a Markdown desk. This format will not be troublesome to interpret each by people and AI fashions.
Process 3: Flip PowerPoint Slides into Clear Markdown
Decks of slides possess helpful summaries. This textual content might be extracted to create information for use in LLM summarization duties.
from markitdown import MarkItDown
md = MarkItDown()
outcome = md.convert("/content material/file-sample.pptx")
print(outcome.text_content) Output:
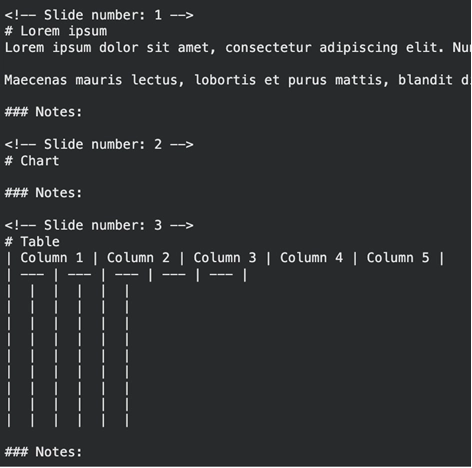
The instrument captures bullet factors and slide titles, separated by slide quantity. It disregards sophisticated format options that trigger textual content parsers to get misplaced.
Process 4: Parse PDFs into Structured Markdown
The PDF is infamously extraordinarily arduous to decode. MarkItDown makes this course of simpler.
from markitdown import MarkItDown
md = MarkItDown()
outcome = md.convert("/content material/1706.03762.pdf")
print(outcome.text_content) Output:
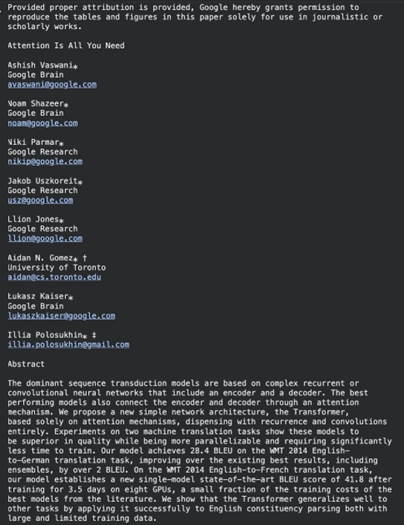
It extracts the textual content with the formatting, part sensible. The library may also mix with OCR instruments when utilizing the advanced PDFs of scanned paperwork.
Process 5: Generate Textual content From Photographs Utilizing OCR
MarkItDown Python Library is ready to describe pictures in case you relate it to a multimodal LLM. This entails an LLC consumer association.
from markitdown import MarkItDown
from openai import OpenAI
from google.colab import userdata
consumer = OpenAI(api_key=userdata.get('OPENAI_KEY'))
md = MarkItDown(llm_client=consumer, llm_model="gpt-4o-mini")
outcome = md.convert("/content material/Screenshot 2025-12-03 at 5.46.29 PM.png")
print(outcome.text_content) Output:

The mannequin will produce a descriptive caption or textual content that’s seen within the picture.
Process 6: Transcribe Audio Recordsdata Into Markdown
You might be even in a position to flip audio recordsdata into textual content. It has this function through speech transcription.
from markitdown import MarkItDown
from openai import OpenAI
md = MarkItDown(llm_client=consumer, llm_model="gpt-4o-mini")
outcome = md.convert("/content material/speech.mp3")
print(outcome.text_content) Output:

A textual content transcription of the audio file in Markdown format.
Process 7: Course of A number of Recordsdata Inside ZIP Archives
MarkItDown can deal with entire archives concurrently, ought to you have got a ZIP file of paperwork.
from markitdown import MarkItDown
md = MarkItDown()
outcome = md.convert("/content material/test-sample.zip")
print(outcome.text_content) Output:
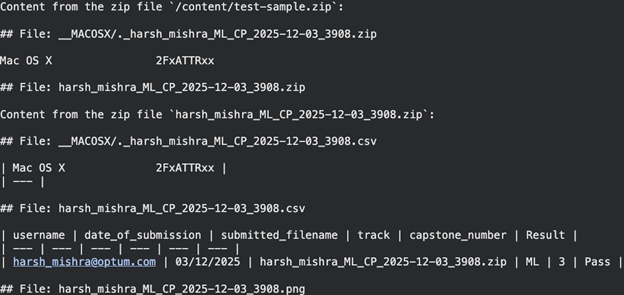
The applying unifies the contents of all supported recordsdata inside a ZIP right into a single Markdown output. It additionally extracts CSV file content material and converts it into Markdown.
Process 8: Dealing with HTML and Textual content-Based mostly Codecs
Internet pages and information recordsdata like CSVs are easy to transform recordsdata to Markdown.
from markitdown import MarkItDown
md = MarkItDown()
outcome = md.convert("/content material/sample1.html")
print(outcome.text_content) Output:
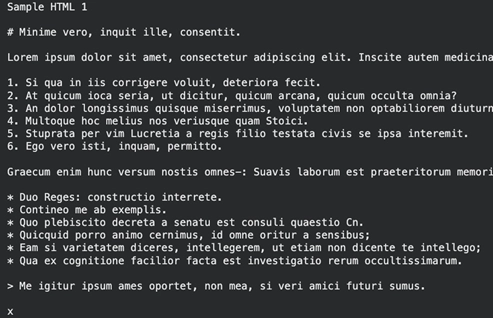
Course of A number of Recordsdata Inside ZIP Archives
Clear Markdown that preserves hyperlinks and headers from the HTML.
Superior Ideas and Troubleshooting
Preserve the next ideas in thoughts to get the most effective outcomes from this doc conversion instrument:
Choose 77 extra phrases to run Humanizer.
- Optimization of the Output: The -o flag can be utilized within the command line to avoid wasting to a file.
- Huge recordsdata: Giant recordsdata is perhaps time consuming to course of. Guarantee that adequate reminiscence capability is offered in your machine.
- API Errors: API key and web situation: in case of issues with picture/audio conversion, examine API key and web connection.
- Supported Codecs: Seize a failure: Assessment the GitHub points web page. The society is engaged and supportive.
Taking It Additional: Constructing an AI Pipeline
MarkItDown acts as a powerful basis for AI workflows. You’ll be able to combine it with instruments like LangChain to construct highly effective AI functions. Excessive-quality information issues when coaching LLMs. Microsoft’s open-source instruments assist you to keep clear enter information, which ends up in extra correct and dependable AI responses.
Conclusion
MarkItDown Python Library is a breakthrough in preparation of knowledge. It allows you to convert recordsdata to Markdown with the least quantity of effort. It processes easy texts to multimedia. Microsoft open-source instruments are additionally making the developer expertise higher. This can be a doc conversion instrument that must be in your toolkit in case you cope with LLMs. Strive the examples above. Be a part of the neighborhood on GitHub. Naturally prepared information to workflows of LLM within the briefest potential time.
Often Requested Questions
A. Sure. Microsoft maintains it as an open-source library, and you’ll set up it without spending a dime with pip.
A. It helps textual PDFs greatest however is able to working with scanned pictures offered you set it up with a LLM consumer to do OCR.
A. No. MarkItDown requires an API key just for picture and audio conversions. It converts text-based recordsdata domestically with none API key.
A. Putting in the library, too, does imply an accessible command-line instrument to insert fast file conversions.
A. It might assist PDF, Docx, PPTX, XLSX, pictures, audio, HTML, CSV,JSON, ZIP, and YouTube URLs.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Giant Language Fashions than precise people. Keen about GenAI, NLP, and making machines smarter (in order that they don’t exchange him simply but). When not optimizing fashions, he’s most likely optimizing his espresso consumption. 🚀☕
Login to proceed studying and revel in expert-curated content material.

{kind=link}