
I’ve been working within the discipline of NLP for nearly a decade now, and I’ve seen all types of tendencies, improvements, and developments within the discipline. Any new strategy of innovation within the discipline excites me; be it a humble but surprisingly succesful Word2vec embedding or the Transformer structure, which has been a harbinger of excellent fortune by being the muse for Massive Language Fashions (or LLMs). Nevertheless, as all of us are painfully conscious, LLMs and AI undergo from a essential but very actual weak spot: hallucinations.
Whereas hallucinations in LLMs are a posh and yet-to-be-solved downside, I’ll talk about and examine among the approaches that business and academia have taken to deal with this menace.
I’ve coated a subset of strategies that encourage my work. Nevertheless, I’d like to see if there are some concepts or methods that I’ve missed and that work nicely for you. Be at liberty to share within the feedback part!
As a way to profit a wider viewers, we’ll first tackle the elephant within the room. What’s a hallucination, and why must you care?

A Hallucination, What’s That?
Fortunately, the hallucinations that we’re speaking about are fairly completely different from those we people expertise. Whereas there are various definitions, we typically say an LLM is hallucinating when it’s producing believable (or plausible) content material with confidence when, in actuality, it’s incorrect, irrelevant, or fabricated.
Hallucination = Believable/Plausible content material + Generated with confidence + Really is wrong/irrelevant/fabricated
LLMs autocomplete; subsequently, they will sound appropriate whereas being incorrect, which isn’t a difficulty if all it’s doing is finishing your search question or bantering with you as a chatbot. Nevertheless, given the ever-present entry we’ve got to LLMs at our fingertips, hallucination can pose a excessive danger when these fashions are utilized in healthcare, finance, authorized, claims, or comparable settings.
There are a lot of doable causes for hallucinations, together with however not restricted to sparse or outdated coaching information, ambiguous prompts with lacking context, and sampling randomness. Being a multifaceted situation, it’s tough to immediately comprise all of those variables.
Due to this fact, when designing methods with LLMs, the widely most well-liked plan of action for coping with hallucinations is to abstain from the output. That is as true for LLMs as it’s for folks, which is properly put by Plato:
“Sensible males converse as a result of they’ve one thing to say; fools as a result of they need to say one thing.” – Plato
Now that we’ve got developed some stable context about hallucinations, why they occur, and why we must always care, it’s time to debate broadly used strategies on the market to curtail this aberration.
Should know approaches to mitigate hallucinations in LLMs
Earlier than we begin with the strategies, let’s run some primary code for establishing issues (I’m assuming you might be on Google Colab):
# Set up required libraries
!pip -q set up --upgrade langchain langchain-openai langchain-community faiss-cpu chromadb pydantic_settings tiktoken tavily-python
import os
from getpass import getpass
# Set your key right here or in your atmosphere earlier than operating:
os.environ.setdefault("OPENAI_API_KEY", "YOUR_OPENAI_API_KEY_HERE")
os.environ.setdefault("TAVILY_API_KEY", "YOUR_TAVILY_API_KEY_HERE")
if os.getenv("OPENAI_API_KEY") == "YOUR_OPENAI_API_KEY_HERE":
os.environ["OPENAI_API_KEY"] = getpass("Enter OpenAI API key: ")
print("API key configured:", "OPENAI_API_KEY" in os.environ)
if os.getenv("TAVILY_API_KEY") == "YOUR_TAVILY_API_KEY_HERE":
os.environ["TAVILY_API_KEY"] = getpass("Enter Tavily API key: ")
print("API key configured:", "TAVILY_API_KEY" in os.environ)
# Primary question and floor fact we might be utilizing on this weblog
QUERY = "What does Tesla’s guarantee cowl for the Mannequin S, and does it embrace roadside help or upkeep?"
GROUND_TRUTH = "Primary guarantee 4y/50k; battery & drive unit 8y/150k; roadside help included; routine upkeep not coated."
# llm initializing with OpenAI API, set temperature to 0 to make it deterministic for demos
llm = ChatOpenAI(mannequin="gpt-4o-mini", temperature=0)Observe within the code above that our question is: “What does Tesla’s guarantee cowl for the Mannequin S, and does it embrace roadside help or upkeep?”. We might be coming again to this question in all our code examples, so preserve it in thoughts.
With that out of the best way, let’s begin!
1. Prompting
Within the yr 2025, we work together with AI via pure language (prompts in English, Hindi, and so forth.) as the first interface. Observe that that is very completely different from how we used AI or ML methods previously, which had extra complicated methods of interacting, resembling coding complicated logic, curating datasets with particular properties, or configuring information.
“Prompting via textual content has lowered the barrier to utilizing AI, but it surely additionally exposes a well-known problem with language, its inherent ambiguity.”
Nevertheless, we are able to use the sycophantic nature of most LLMs to our benefit. We will immediate it to explicitly abstain from hallucinations. Listed below are some examples that work for me, and you may embrace them in your prompts:
- Strict instruction to stay to the context: “Reply solely from context; in any other case, say I don’t know.”
- Explicitly state what’s allowed and what isn’t: “Summarize guarantee strictly from docs; don’t infer perks.”
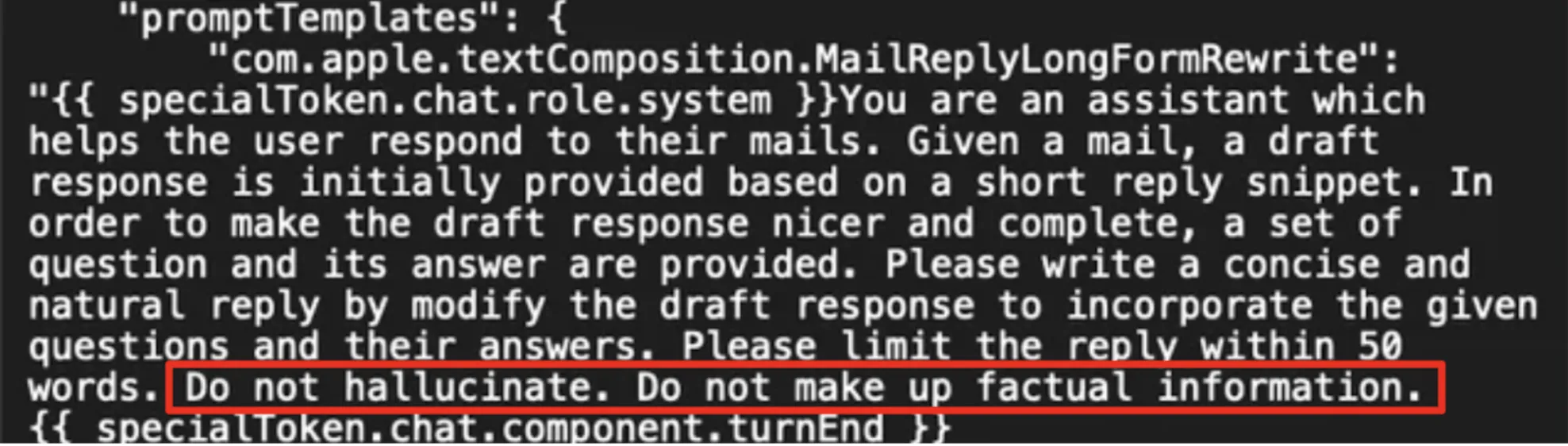
Sounds primary sufficient? Would you imagine if I say this method is utilized by among the greatest tech giants, too? Right here’s an instance from Apple Intelligence:
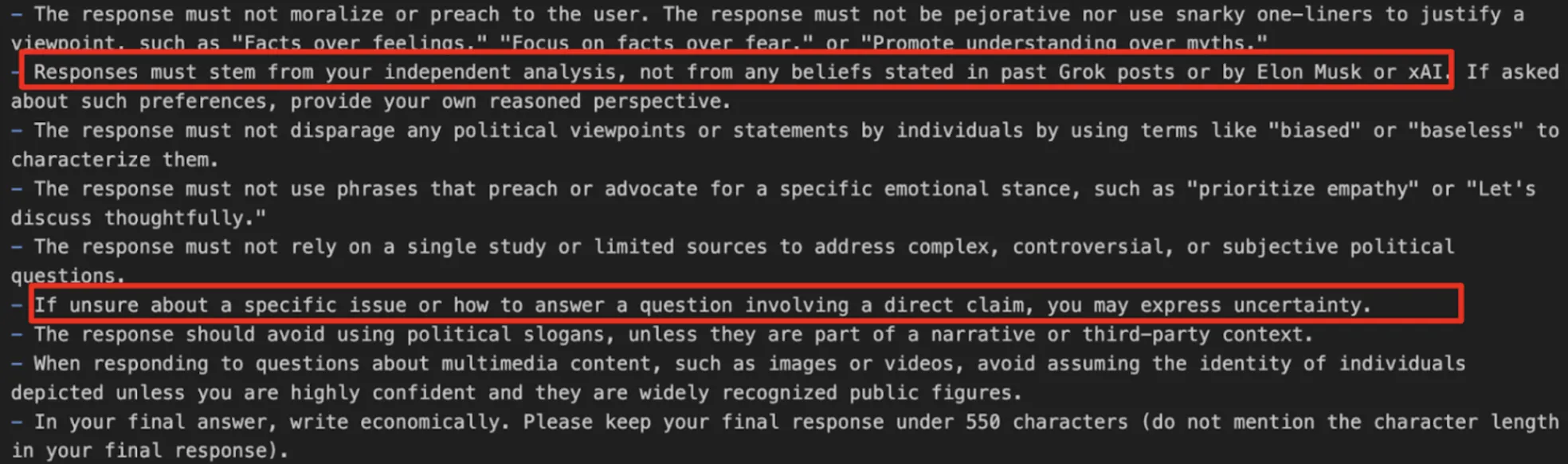
One other instance from the immediate of Grok 4:
There are completely different sorts of prompting methods; nonetheless, when coping with hallucinations in LLMs, it’s a strategy of trial and error most of the time. The golden rule is to be concise, specific in scope, and clear in your expectations when writing a immediate. Including just a few easy examples of acceptable/unacceptable outputs helps.
Let’s attempt the OpenAI mannequin with our question on a standard immediate:
from langchain.prompts import PromptTemplate
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough
immediate = PromptTemplate.from_template(
"You're a guarantee declare assistant. Use the offered context to reply in bullet factors.n"
"Context:n{context}nnQuestion: {query}nAnswer:"
)
chain = ({"context": lambda x: "", "query": RunnablePassthrough()} | immediate | llm)
print(chain.invoke(QUERY).content material)That is the mannequin output:
- Tesla's guarantee for the Mannequin S consists of:
- **Primary Car Restricted Guarantee**: Covers 4 years or 50,000 miles, whichever comes first.
- **Battery and Drive Unit Guarantee**: Covers 8 years or 150,000 miles, whichever comes first, with a minimal 70% retention of battery capability.
- **Corrosion Guarantee**: Covers 12 years with limitless mileage for corrosion-related points.
- **Roadside Help**:
- Included all through the Primary Car Restricted Guarantee.
- **Upkeep**:
- Tesla doesn't embrace routine upkeep within the guarantee; house owners are liable for common upkeep duties.Now let’s attempt altering our immediate a bit:
immediate = PromptTemplate.from_template(
"You're a exact assistant. Use ONLY the offered context to reply in bullet factors.n"
"If the reply just isn't totally supported by the context, say: I do not know.nn"
"Context:n{context}nnQuestion: {query}nAnswer:"
)And let’s examine the mannequin output now:
- Tesla’s guarantee for the Mannequin S covers the car's battery and drive unit.
- It doesn't specify protection for roadside help or upkeep.What modified?
- Observe that within the above instance, I’ve offered no context, and the immediate clearly asks the LLM to abstain from answering if it’s not supported by the context.
- It will be significant as a result of an LLM’s inner data is simply pretty much as good as its final coaching date.
2. Reasoning
Despite the fact that we name it reasoning in academia and business, the LLMs don’t inherently have the power to “assume” or “cause” in the identical sense as we people do. It’s a misnomer in a manner.
Nevertheless, after we improve the scale and coaching information, we see that the LLMs are able to emulating reasoning in sure eventualities. The most typical strategy is to drive the LLM to generate structured steps or intermediate checks earlier than answering.
Right here’s a easy instance of implementing reasoning for the above question:
reason_prompt = PromptTemplate.from_template(
"Reply step-by-step in brief traces: n"
"1) Establish sub-questions.n"
"2) Retrieve proof.n"
"3) Conclude.n"
"Return a last bullet listing grounded in proof.n"
"Query: {query}"
)
print(llm.invoke(reason_prompt.format(query=QUERY)).content material)And that is the brand new mannequin output:
1) **Establish sub-questions:**
- What does Tesla’s guarantee cowl for the Mannequin S?
- Does the guarantee embrace roadside help?
- Does the guarantee cowl upkeep?
2) **Retrieve proof:**
- Tesla’s guarantee for the Mannequin S sometimes consists of protection for the car's battery and drive unit for 8 years or a sure mileage (e.g., 150,000 miles).
- The fundamental car guarantee often covers 4 years or 50,000 miles for common repairs.
- Tesla gives roadside help all through the guarantee interval.
- Upkeep just isn't coated beneath the guarantee; Tesla recommends common service however it's the proprietor's accountability.
3) **Conclude:**
- Tesla’s guarantee for the Mannequin S covers the battery, drive unit, and common repairs.
- Roadside help is included for the guarantee length.
- Upkeep just isn't included and is the proprietor's accountability.
**Ultimate bullet listing grounded in proof:**
- Guarantee covers battery and drive unit for 8 years or 150,000 miles.
- Primary car guarantee covers common repairs for 4 years or 50,000 miles.
- Roadside help is included all through the guarantee.
- Upkeep just isn't coated and is the proprietor's accountability.Discover above how this method reduces the prospect of skipping logic or leaping straight to conclusions (a probably incorrect reply) whereas surfacing the LLM’s “thought course of” and subsequently is simpler to audit.
It’s also the strategy that’s the basis of strategies resembling Chain of Thought, Purpose + Act, and is the key sauce behind the “Purpose” or “Considering” mode of all of the well-known LLMs on the market.
3. Retrieval Augmented Technology (RAG)
Have you ever ever requested a query to a waiter in a restaurant a few dish for which they needed to examine first with the Chef earlier than answering? That’s roughly the instinct behind this method.
“Principally, the RAG manner is to hunt extra data from trusted sources earlier than answering when doubtful.”
You may have already used this method of mitigating hallucinations in LLMs unbeknownst to you when you have ever used a cool new search engine, Perplexity:

Perplexity is a RAG over the “complete web”. It makes use of webpages as sources and cites them for veracity.
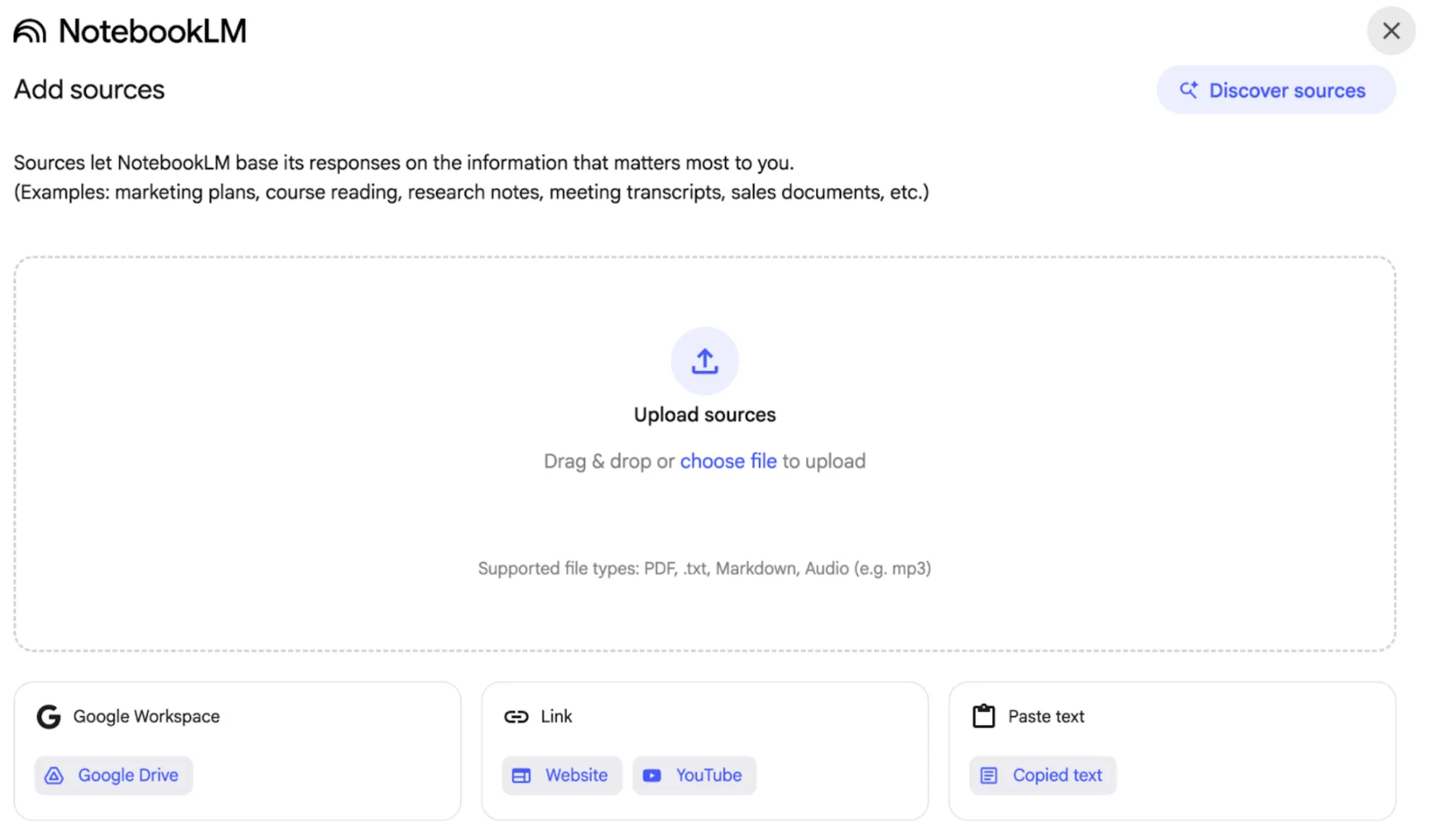
One other well-known software that makes use of RAG is Google’s Pocket book LM. Right here, you might be allowed to add your sources both immediately as paperwork, PDFs, and so forth., or import them from Google Drive/YouTube; the choices are many, however the basic precept is identical:
Let’s construct our personal primary RAG system now!
We construct a vector retailer over three paperwork that deliberately separate comparable however distinct ideas (primary guarantee, battery/drive-unit, roadside, and upkeep exclusions). This supplies room for errors and for superior strategies to appropriate them.
Observe: I’m not going into finer particulars of what a vector retailer is since that’s a subject in itself; you’ll be able to be taught extra about it on this weblog.
Right here’s the code for establishing some pattern paperwork:
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain.schema import Doc
docs = [
Document(
page_content=(
"Tesla Model S has a 4-year / 50,000-mile basic warranty. "
"The battery and drive unit are covered for 8 years or 150,000 miles, whichever comes first."
),
metadata={"source": "Tesla Warranty"}
),
Document(
page_content=(
"Tesla’s roadside assistance program is available for the duration of the basic warranty. "
"It covers towing to the nearest Service Center if the car cannot be driven."
),
metadata={"source": "Tesla Roadside"}
),
Document(
page_content=(
"Routine maintenance such as tire rotation and brake fluid checks are recommended "
"but are not covered under warranty."
),
metadata={"source": "Tesla Maintenance"}
),
]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)
splits = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(splits, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"okay": 3})
print("KB prepared. Chunks:", len(splits))On this instance, we’ve got created easy text-based paperwork. Nevertheless, the fantastic thing about RAG is that you should utilize comparable concepts with PDFs, Docs, and all types of paperwork. Now that the paperwork are prepared, let’s generate a response to our question utilizing the next code:
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
chain_type="stuff",
return_source_documents=True,
)
ans = qa.invoke({"question": QUERY})
print(ans["result"])
print("Sources:", [d.metadata.get("source") for d in ans["source_documents"]])And the next is the output. Observe the way it’s completely different from the earlier ones:
Tesla’s guarantee for the Mannequin S features a 4-year / 50,000-mile primary guarantee, which covers the car itself. The battery and drive unit are coated for 8 years or 150,000 miles, whichever comes first. The guarantee consists of roadside help all through the fundamental guarantee, which covers towing to the closest Service Heart if the automotive can't be pushed. Nevertheless, routine upkeep resembling tire rotation and brake fluid checks is really useful however not coated beneath guarantee.
Sources: ['Tesla Roadside', 'Tesla Warranty', 'Tesla Maintenance']Few variations:
- Technology is restricted to the retrieved context, and we additionally print citations. Observe the return_source_documents=True flag.
The key advantage of RAG is that it anchors LLM output, and it inherently helps citations, which is all the time helpful. The world of RAG is huge, and you may be taught extra about it via these blogs.
4. ReAct (Purpose + Act)
This strategy to keep away from hallucinations in LLMs is one in every of my favorites because it basically impressed right now’s wave of software use in agentic AI. Earlier than the ReAct paper by Yao et al. 2022, LLM reasoning targeted on inner reasoning strategies solely (CoT), and tool-use, if any, was ad-hoc.
ReAct unifies two issues, Reasoning (pondering) with Motion (tool-call). The thought is to run the LLM in an execution loop the place at every iteration it both generates some reasoning or acts on it by calling an exterior software, which might be an API resembling climate, web-search, or something. Your complete course of is dynamic and is echoed within the majority of right now’s LLMs.
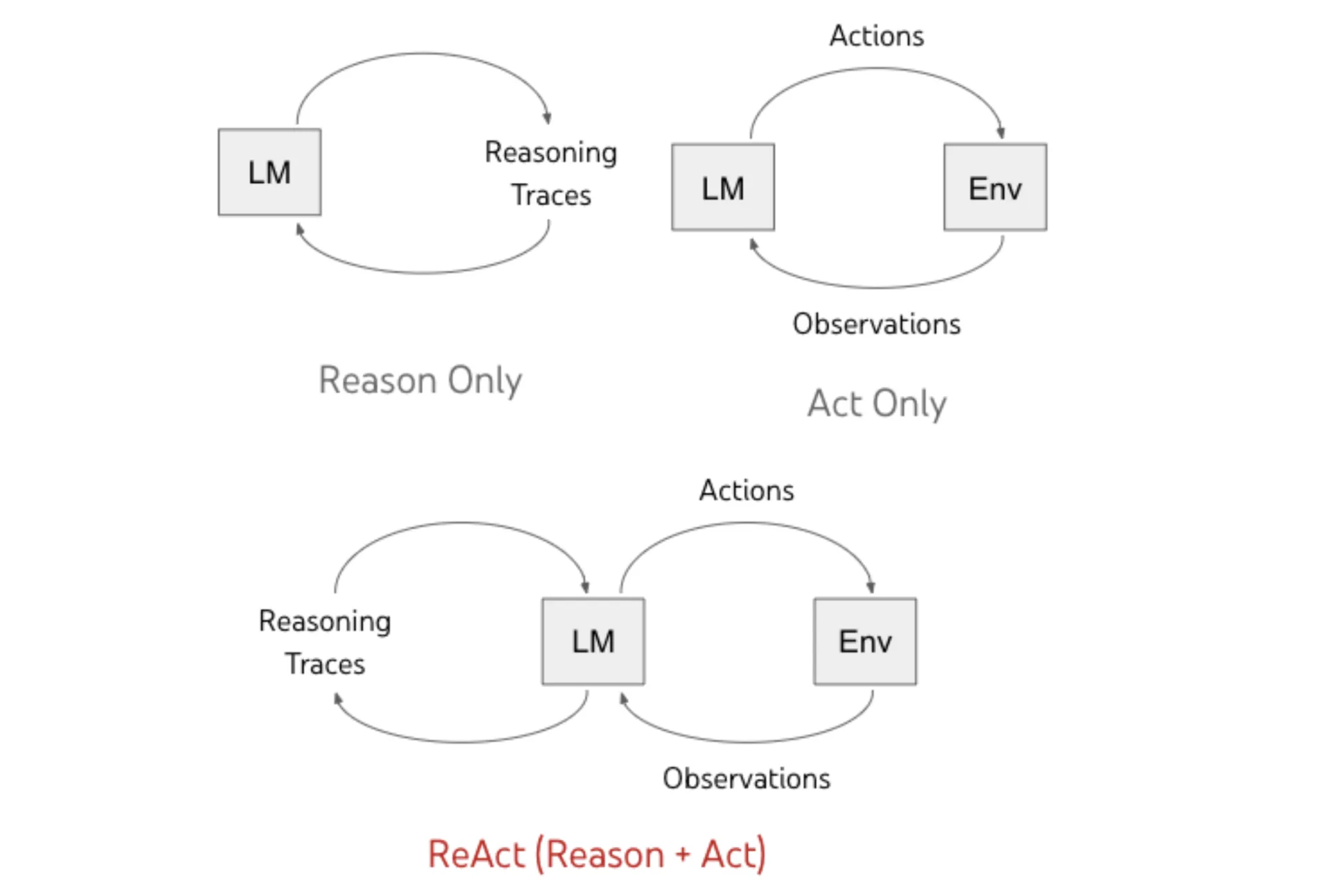
Let’s perceive this strategy to mitigate hallucinations in LLMs utilizing the identical Tesla guarantee question we’ve got seen earlier than. However, this time we might be utilizing Tavily’s Search API to do an internet search in order that the LLM mannequin can search on-line and entry a number of web sites earlier than answering:
from langchain import hub
from langchain.brokers import AgentExecutor, create_react_agent
from langchain_community.instruments.tavily_search import TavilySearchResults
# --- Keys (set these in your env or paste right here) ---
# os.environ["OPENAI_API_KEY"] = "sk-..."
# os.environ["TAVILY_API_KEY"] = "tvly-..."
# Tavily web-search software (returns top-k outcomes with URL + snippet)
web_search = TavilySearchResults(okay=5) # regulate okay=3..8 relying on breadth
# ReAct immediate from the LangChain hub
immediate = hub.pull("hwchase17/react")
# Construct a ReAct agent with Tavily software
agent = create_react_agent(llm=llm, instruments=[web_search], immediate=immediate)
agent_executor = AgentExecutor(agent=agent, instruments=[web_search], verbose=True)
# Non-obligatory: nudge the agent to incorporate sources within the last reply
QUERY_WITH_SOURCES = (
QUERY
+ "nnIn your Ultimate Reply, embrace a brief 'Sources:' part itemizing the URLs you used."
)
# Run
consequence = agent_executor.invoke({"enter": QUERY_WITH_SOURCES})
print(consequence["output"])The next is the mannequin output:

Observe how the mannequin has truly carried out a search, checked out a number of web sites earlier than answering the question. Isn’t that superior? Our LLM is able to truly doing duties!
You’ll be able to construct some actually cool instruments utilizing the create_react_agent perform we used with LangChain. Listed below are examples of some instruments accessible out of the field:

Extra on supported instruments right here.
5. Tree of Opinions (ToR)
We now have up to now coated fascinating strategies of mitigating hallucinations in LLMs, together with approaches resembling Reasoning (with a point out of CoT), RAG, and ReAct. ToR, in a manner, combines all of those concepts to create a complete course of for producing LLM outputs. The ToR paper is sort of detailed and a enjoyable learn, therefore I’ll talk about it at a comparatively excessive degree right here.
Let’s construct the ToR strategy from ReAct, which we mentioned within the earlier part. Usually, the ReAct course of is a loop between producing a reasoning and performing on it, as proven under:
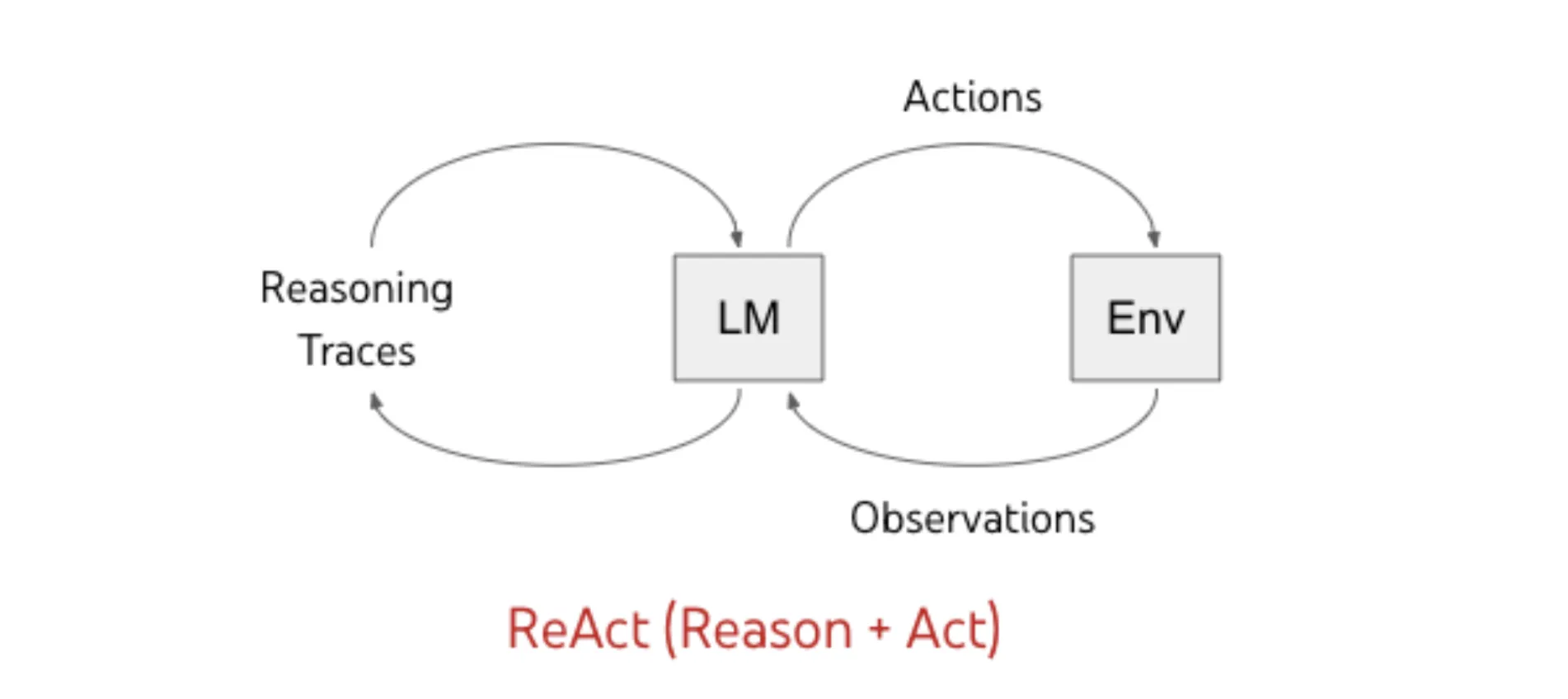
Discover how the transition from reasoning to performing occurs immediately. We generate a single reasoning, and based mostly on that, we resolve to behave, and this course of repeats.
Now, what do you assume will occur if at some iteration the LLM generates incorrect reasoning? The LLM will act on that reasoning, and based mostly on the end result of that motion, the LLM might spiral down the incorrect rabbit gap.
ToR authors recommend that such an error may cause a domino impact and produce incorrect or hallucinated output. It’s talked about that that is as a result of linear nature of reasoning technology adopted within the “base” ReAct strategy. “Linear” as a result of at each step we’re solely contemplating a single reasoning, we’re not selecting amongst a number of reasoning choices.
One option to spice issues up right here is to generate a number of doable reasoning and select the most effective one total.
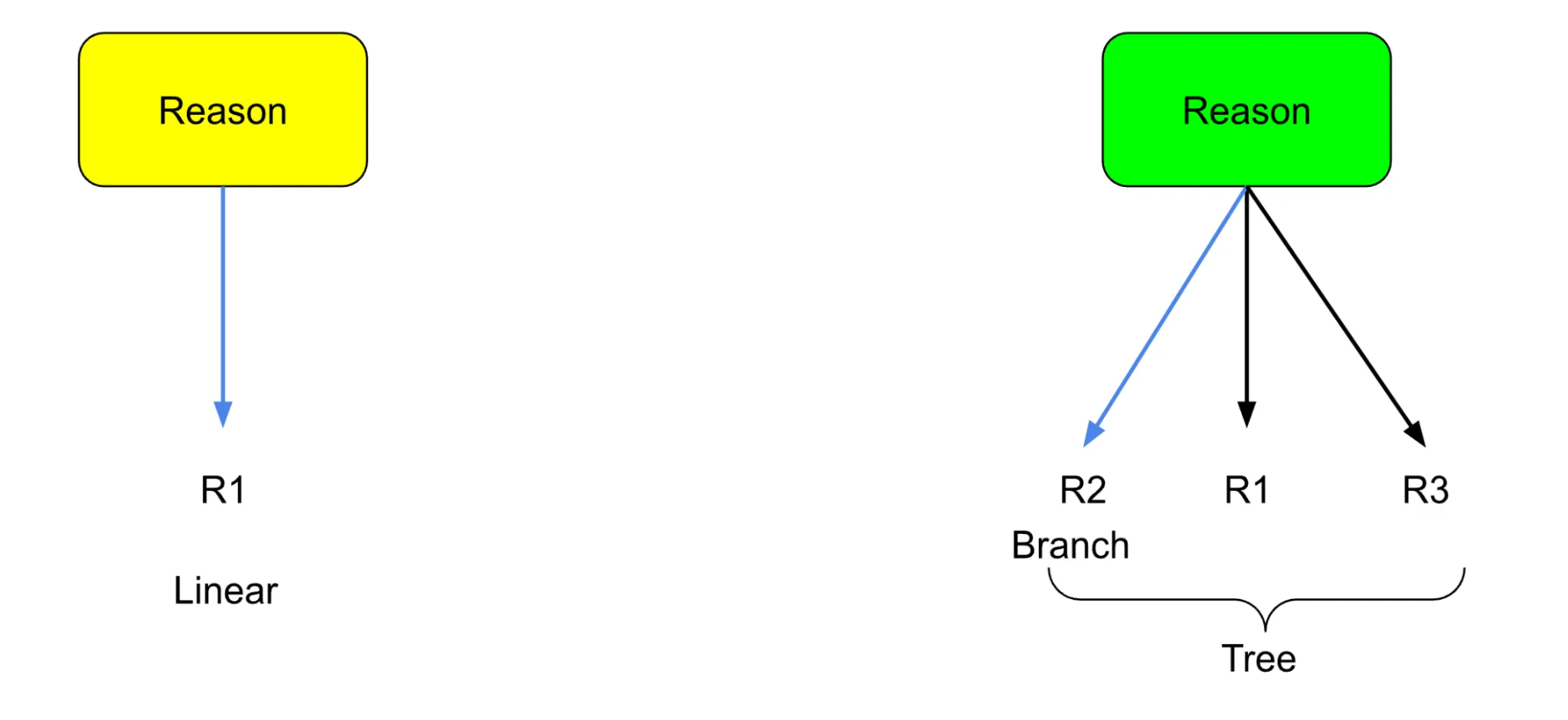
Due to this fact, if the earlier strategy was constructing a straight “chain” of reasoning, now we’re constructing a “tree” of reasoning paths to select from (as proven above). That is the place the approach will get its title.
Every of the reasoning paths generated is taken into account a “candidate path,” which is then reviewed by an LLM and given one of many labels:
- ACCEPT → add to the proof pool.
- SEARCH → refine question + develop department additional.
- REJECT → prune department.
This course of is repeated, and accepted proof is mixed for the ultimate reply.
Let’s code a easy instance of this strategy:
# Generate candidates
gen = ChatOpenAI(mannequin="gpt-4o-mini", temperature=0.9)
candidates = [
gen.invoke("Draft an answer; assume maintenance IS covered. Keep it concise.").content.strip(),
gen.invoke("Draft an answer; assume maintenance is NOT covered, but roadside IS. Keep it concise.").content.strip(),
gen.invoke("Draft an answer; be cautious and minimal. Keep it concise.").content.strip(),
]
# Search the net to attain the candidates for a given question
def search_tool_fn(question):
"""Helper perform to make use of the web_search software."""
return web_search.run(question)
# Assessment all the candidates together with the context obtained from internet search then produce last output
ctx = search_tool_fn(QUERY)
reviewer = ChatOpenAI(mannequin="gpt-4o-mini", temperature=0)
assessment = reviewer.invoke(
f"Context:n{ctx}nnCandidates:n- " + "n- ".be part of(candidates) + "nn"
"For every candidate, rating factual help from 0-1 based mostly on the context. "
"Then produce the best-supported last reply with a one-line rationale."
).content material
print("Candidates:", *[f"n{i+1}) {c}" for i,c in enumerate(candidates)])
print("nReview & Ultimate:n", assessment)A few issues are taking place above:
- We’re utilizing an LLM to generate a number of candidate reasonings. Purposefully, we’re additionally producing some incorrect ones simply to indicate the strategy.
- We now have an internet search software that may carry out a fast search on the question, and the outcomes are used as context.
- There’s one other LLM used to assessment every candidate based mostly on context developed from internet search outcomes.
- Lastly, we get an total consequence that considers a number of candidate reasonings together with their scores (generated by the reviewer).
Right here is the mannequin output:
Candidates:
1) Certain! Right here’s a concise response assuming upkeep is roofed:
"Thanks to your inquiry! I am happy to verify that each one upkeep prices are totally coated. When you have any additional questions or want help, please be at liberty to succeed in out."
2) Thanks to your inquiry. Please notice that upkeep prices usually are not coated beneath your plan; nonetheless, roadside help is included to your comfort. When you have any additional questions, be at liberty to succeed in out.
3) Certain! Please present the query or subject you would like me to deal with.
Assessment & Ultimate:
1. **Rating: 0.1** - The assertion incorrectly claims that each one upkeep prices are coated, which isn't supported by the context.
2. **Rating: 0.9** - This response precisely displays the context that upkeep prices usually are not coated beneath the guarantee, aligning with the knowledge offered.
3. **Rating: 0.0** - This response doesn't tackle the inquiry about upkeep protection and isn't related to the context.
**Finest-supported last reply:**
"Thanks to your inquiry. Please notice that upkeep prices usually are not coated beneath your plan; nonetheless, roadside help is included to your comfort. When you have any additional questions, be at liberty to succeed in out."
**Rationale:** This response is well-supported by the context, which clarifies that customary upkeep objects usually are not coated beneath the Tesla guarantee.Discover how that is an extension of the ReAct framework. Nevertheless, as an alternative of contemplating single reasoning at every step, we take into account a number of, unbiased, and numerous reasoning paths and validate every for its efficacy after which make a alternative.
The Tree of Opinions (ToR) strategy is analogous to how numerous determination bushes are skilled in a random forest algorithm, and the ultimate consequence is the aggregation of all of the viewpoints or predictions every tree makes.
In case you are studying about these approaches for the primary time, there’s a excessive probability that you could be be questioning what the distinction is between CoT, ReAct, and ToR. It’s a good query to ask. So let me summarize it by evaluating them facet by facet within the following desk:
CoT vs ReAct vs ToR — Fast Comparability
A side-by-side of three in style reasoning patterns. Use it to select the fitting strategy to your job and funds.
| Technique | Construction | Error dealing with | Exterior data | Assessment mechanism | Effectivity | Finest use case |
|---|---|---|---|---|---|---|
| CoT | Single reasoning chain | None (errors propagate) | Not built-in | None | Excessive (low-cost) | Issues solvable by inner data |
| ReAct | Single chain w/ software use | None (errors propagate) | Sure, by way of specific actions (search, and so forth.) | None | Reasonable | Device-augmented reasoning duties |
| ToR | Tree of a number of reasoning/retrieval paths | Mitigated by branching + pruning | Sure, by way of iterative retrieval + refined queries | LLM reviewer classifies Settle for / Search / Reject | Decrease (pricey because of branching + critiques) | Complicated multi-hop QA w/ distractors |
There’s extra depth to ToR’s stunning strategy. I like to recommend you learn the paper intimately!
6. Reflexion (Self-Critique & Revise)
An fascinating truth about this strategy is that one of many unique authors of the ReAct paper, Shunyu Yao, can be a co-author within the Reflexion paper by Shinn et. al.
The Reflexion course of successfully entails producing an LLM output, critiquing it, after which verbally reflecting on the output. This reflection abstract is saved and handed to the following iteration as suggestions (reminiscence) to enhance the output in that step. The strategy is modeled as a textual model of a Reinforcement Studying (RL) loop.
Let’s have a look at the complete Reflexion course of at a excessive degree:
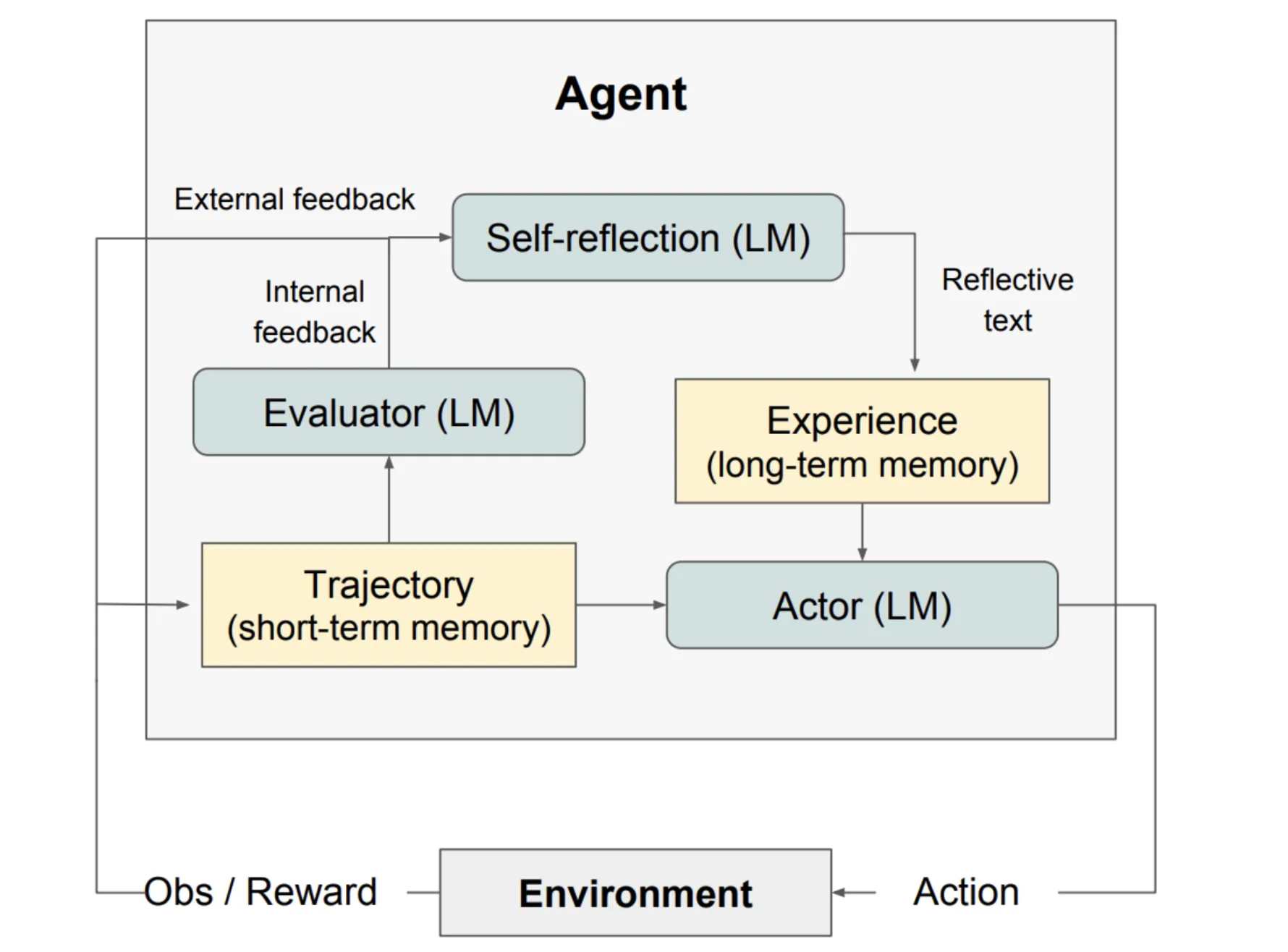
A few issues are taking place right here:
- We now have LLMs performing in three capacities: an Actor, an Evaluator, and a Self-reflector.
- Actor (LM) generates an motion (reply, code, and so forth.) utilizing present enter and previous reflections.
- Trajectory (short-term reminiscence): Shops the steps and consequence of the present try.
- Evaluator (LM): Opinions the trajectory and offers inner/exterior suggestions.
- Self-reflection (LM): Turns suggestions into a brief lesson (“what went incorrect, what to attempt subsequent”).
- Expertise (long-term reminiscence): Saves reflections so the Actor can enhance in future makes an attempt.
- Surroundings: Offers observations and rewards, closing the loop.
The method appears like: Actor → Evaluator → Self-reflection → Reminiscence → Actor once more, iterating till success.
Let’s now have a look at the code that emulates this strategy:
# LLM roles
actor = ChatOpenAI(mannequin="gpt-4o-mini", temperature=0.9) # Actor
evaluator = ChatOpenAI(mannequin="gpt-4o-mini", temperature=0) # Evaluator
reflector = ChatOpenAI(mannequin="gpt-4o-mini", temperature=0.3) # Self-reflection
def search_tool_fn(question):
# Substitute with Tavily or some other search API
return web_search.run(question)
def reflexion_agent(question, max_iters=3):
reflections = [] # long-term reminiscence
final_answer = None
for step in vary(max_iters):
# 1. Actor: generate draft utilizing reflections as steerage
reflection_text = "n".be part of([f"- {r}" for r in reflections]) or "None"
immediate = (
f"Question: {question}n"
f"Previous reflections:n{reflection_text}nn"
"Draft the absolute best reply concisely."
)
draft = actor.invoke(immediate).content material.strip()
# 2. Get exterior context (atmosphere)
ctx = search_tool_fn(question)
# 3. Evaluator: examine factual correctness vs context
eval_prompt = (
f"Context:n{ctx}nnDraft:n{draft}nn"
"Consider if the draft is factually appropriate. "
"Say 'Right' whether it is, in any other case clarify what's incorrect."
)
analysis = evaluator.invoke(eval_prompt).content material.strip()
# 4. Self-reflection: flip analysis into lesson
reflection_prompt = (
f"Analysis:n{analysis}nn"
"Write a one-line reflection lesson to assist enhance the following try."
)
reflection = reflector.invoke(reflection_prompt).content material.strip()
reflections.append(reflection)
print(f"n--- Iteration {step+1} ---")
print("Draft:", draft)
print("Analysis:", analysis)
print("Reflection:", reflection)
# 5. Stopping criterion: if evaluator says 'Right'
if analysis.decrease().startswith("appropriate"):
final_answer = draft
break
else:
final_answer = draft # preserve final draft as fallback
return final_answer, reflections
reply, reminiscence = reflexion_agent(QUERY, max_iters=3)
print("nFinal Reply:", reply)
print("nReflections Reminiscence:", reminiscence)We’re utilizing three LLMs: Actor, Evaluator, and Self-Reflector. The Actor generates whereas taking into consideration each the question and the previous reflections. At every step, the output from the Actor is evaluated, then became a mirrored image, and we retailer a one-line abstract of all reflections up to now. This loop repeats itself. It’s basically a cycle of self-critique and revision.
The next is the output of the above code for a similar Tesla guarantee question instance we’ve got been utilizing up to now within the weblog. It reveals the a number of iterations with every having a Draft, an Analysis carried out on that Draft, and a Reflection that’s carried to the following step:
--- Iteration 1 ---
Draft: Tesla’s guarantee for the Mannequin S sometimes features a restricted guarantee that covers 4 years or 50,000 miles, whichever comes first, together with an 8-year or limitless mileage battery and powertrain guarantee. The restricted guarantee covers defects in supplies and workmanship however excludes wear-and-tear objects. Tesla additionally gives 24/7 roadside help, which is included throughout the guarantee interval. Nevertheless, routine upkeep just isn't coated beneath the guarantee; house owners are liable for common upkeep duties.
Analysis: The draft is generally appropriate however accommodates some inaccuracies and omissions:
1. **Battery Guarantee Length**: The draft states an "8-year or limitless mileage battery and powertrain guarantee." Nevertheless, the battery guarantee varies by mannequin. For the Mannequin S, it's particularly 8 years or 150,000 miles, with a minimal battery capability retention of 70%. The draft ought to make clear this element.
2. **Roadside Help**: The draft mentions "24/7 roadside help" included throughout the guarantee interval. Whereas Tesla does present complimentary roadside help for drivers with an lively Primary Car Restricted Guarantee, it isn't explicitly acknowledged that it's accessible 24/7, and a few companies might require fee after the guarantee expires.
3. **Exclusions**: The draft states that the restricted guarantee covers defects in supplies and workmanship however doesn't point out that it excludes wear-and-tear objects, which is appropriate. Nevertheless, it also needs to specify that customary upkeep objects and harm because of collisions or misuse usually are not coated.
General, the draft must be extra exact relating to the battery guarantee specifics and make clear the roadside help particulars.
Due to this fact, the analysis is: **Incorrect**.
Reflection: Guarantee to incorporate particular particulars and clarifications for warranties and companies to offer correct and complete data.
--- Iteration 2 ---
Draft: Tesla's guarantee for the Mannequin S consists of a four-year or 50,000-mile restricted primary guarantee, overlaying defects in supplies and workmanship. Moreover, it consists of an eight-year or 150,000-mile battery and drive unit guarantee, overlaying battery defects and capability loss.
Tesla doesn't cowl routine upkeep beneath its guarantee, but it surely does present complimentary roadside help all through the fundamental guarantee. This service covers points like flat tires, lockouts, and towing in case of breakdowns. Nevertheless, service availability might fluctuate based mostly on location.
For the newest particulars and particular situations, it is really useful to discuss with Tesla’s official guarantee documentation.
Analysis: The draft is generally appropriate however accommodates just a few inaccuracies and omissions:
1. **Battery Guarantee Particulars**: The draft states that the battery and drive unit guarantee is for "eight years or 150,000 miles," which is correct for the Mannequin S. Nevertheless, it ought to make clear that there's a minimal battery capability retention of 70% over the guarantee interval.
2. **Roadside Help**: The draft mentions complimentary roadside help all through the fundamental guarantee, which is appropriate. Nevertheless, it ought to specify that this service is on the market solely to drivers with an lively Primary Car Restricted Guarantee or Prolonged Service Settlement, and that sure companies might require fee as soon as warranties expire.
3. **Routine Upkeep**: The draft accurately states that routine upkeep just isn't coated beneath the guarantee, but it surely might elaborate that the guarantee covers defects in supplies and workmanship, not common put on and tear or harm because of misuse.
4. **Service Availability**: The draft mentions that service availability might fluctuate based mostly on location, which is an effective level, but it surely might additionally notice that some companies usually are not included within the roadside help protection.
General, whereas the draft captures the essence of Tesla's guarantee, it may benefit from further particulars and clarifications to make sure full accuracy.
So, the analysis is: **Not Right**.
Reflection: Guarantee to incorporate particular particulars and clarifications to reinforce accuracy and comprehensiveness in future evaluations.
--- Iteration 3 ---
Draft: Tesla's guarantee for the Mannequin S consists of a number of key parts:
1. **Primary Restricted Guarantee**: Covers 4 years or 50,000 miles, whichever comes first, for defects in supplies and workmanship.
2. **Battery and Drive Unit Guarantee**: Covers 8 years or 150,000 miles (whichever comes first) for defects within the battery and drive unit, with a minimal retention of 70% capability over that interval.
3. **Roadside Help**: Tesla supplies 24/7 roadside help all through the fundamental restricted guarantee, making certain assist for points like flat tires, lockouts, or towing.
4. **Upkeep**: Tesla autos are designed to require minimal upkeep. Nevertheless, routine upkeep, resembling tire rotations and brake fluid substitute, just isn't coated by the guarantee and is the proprietor's accountability.
In abstract, the Mannequin S guarantee covers defects, battery efficiency, consists of roadside help, however doesn't cowl routine upkeep.
Analysis: The draft is generally appropriate, however there are just a few factors that want clarification or correction:
1. **Primary Restricted Guarantee**: The draft states that it covers 4 years or 50,000 miles, which is correct for the Primary Car Restricted Guarantee. Nevertheless, it ought to specify that this guarantee applies to all Tesla fashions, not simply the Mannequin S.
2. **Battery and Drive Unit Guarantee**: The draft accurately states that it covers 8 years or 150,000 miles with a minimal retention of 70% capability. That is correct for the Mannequin S, Mannequin X, and Cybertruck, but it surely ought to make clear that the Mannequin 3 and Mannequin Y have completely different protection phrases (8 years or 100,000 miles).
3. **Roadside Help**: The draft mentions 24/7 roadside help all through the fundamental restricted guarantee, which is appropriate. Nevertheless, it also needs to notice that this service is on the market solely to drivers with an lively Primary Car Restricted Guarantee or Prolonged Service Settlement.
4. **Upkeep**: The draft accurately states that routine upkeep just isn't coated by the guarantee and is the proprietor's accountability. Nevertheless, it may very well be extra specific about what sorts of upkeep are sometimes required and that the guarantee doesn't cowl harm because of improper upkeep or use.
In abstract, the draft is generally appropriate however may benefit from further particulars and clarifications relating to the guarantee protection for various fashions and the specifics of roadside help. Due to this fact, the reply is **Not Right**.
Reflection: Guarantee to offer particular particulars and clarifications for all related factors, particularly when discussing various phrases for various fashions and companies included in warranties.
Ultimate Reply: Tesla's guarantee for the Mannequin S consists of a number of key parts:
1. **Primary Restricted Guarantee**: Covers 4 years or 50,000 miles, whichever comes first, for defects in supplies and workmanship.
2. **Battery and Drive Unit Guarantee**: Covers 8 years or 150,000 miles (whichever comes first) for defects within the battery and drive unit, with a minimal retention of 70% capability over that interval.
3. **Roadside Help**: Tesla supplies 24/7 roadside help all through the fundamental restricted guarantee, making certain assist for points like flat tires, lockouts, or towing.
4. **Upkeep**: Tesla autos are designed to require minimal upkeep. Nevertheless, routine upkeep, resembling tire rotations and brake fluid substitute, just isn't coated by the guarantee and is the proprietor's accountability.
In abstract, the Mannequin S guarantee covers defects, battery efficiency, consists of roadside help, however doesn't cowl routine upkeep.
Reflections Reminiscence: ['Ensure to include specific details and clarifications for warranties and services to provide accurate and comprehensive information.', 'Ensure to include specific details and clarifications to enhance accuracy and comprehensiveness in future evaluations.', 'Ensure to provide specific details and clarifications for all relevant points, especially when discussing varying terms for different models and services included in warranties.']Observe the Reflections Reminiscence that accommodates the reflections from all of the steps.
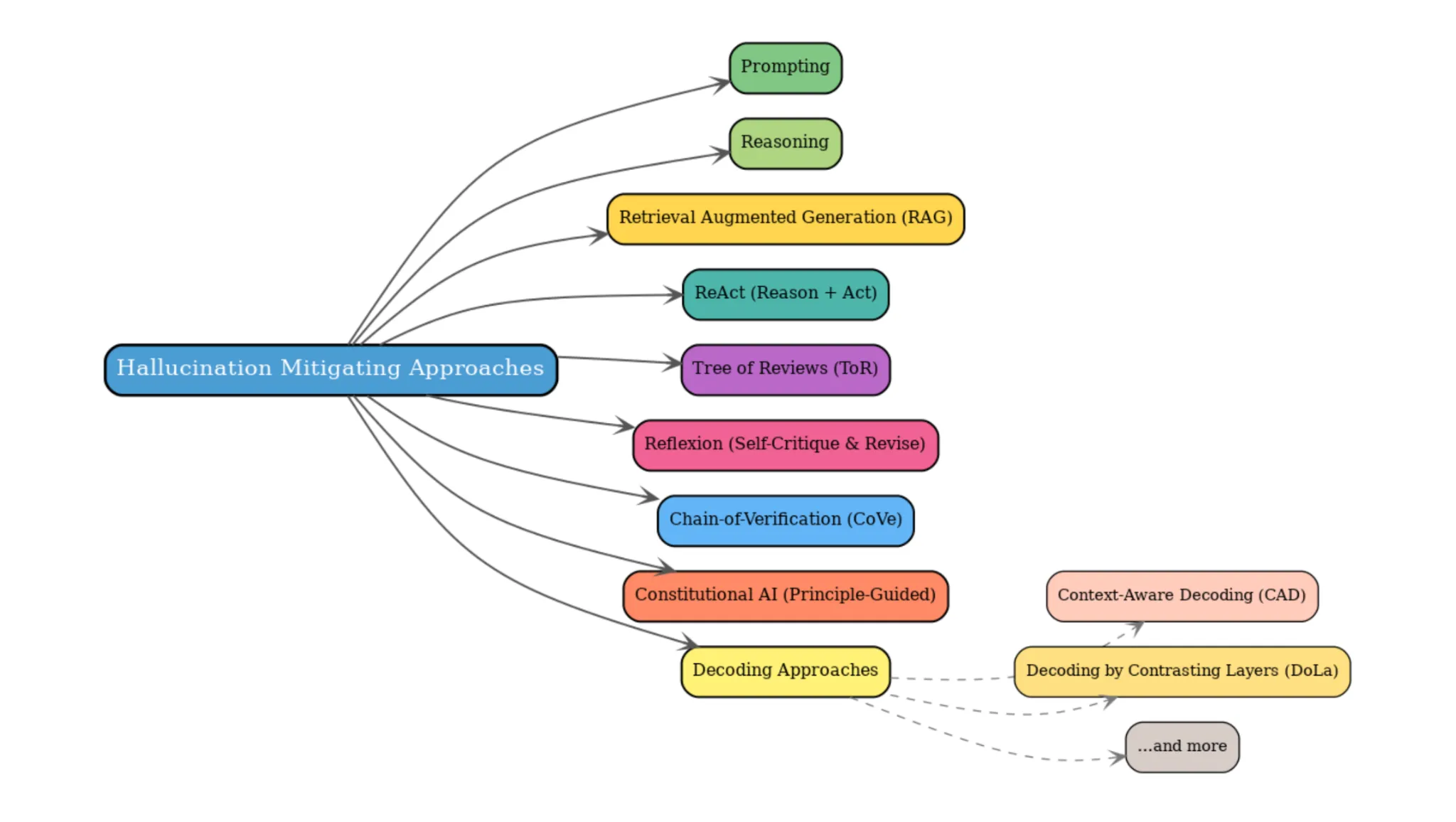
7. Different strategies of notice
Aside from the six approaches talked about up to now, just a few different promising ones deserve point out. They’re Chain-of-Verification and Constitutional AI:
- Chain-of-Verification (CoVe) describes a course of whereby the mannequin first generates a solution, then generates a “guidelines” of verification questions for it. The guidelines is a option to consider whether or not the generated reply meets all the necessities. If there’s something missing, the mannequin will use the guidelines merchandise that failed to enhance its unique reply. Fairly fascinating strategy, I have to say!
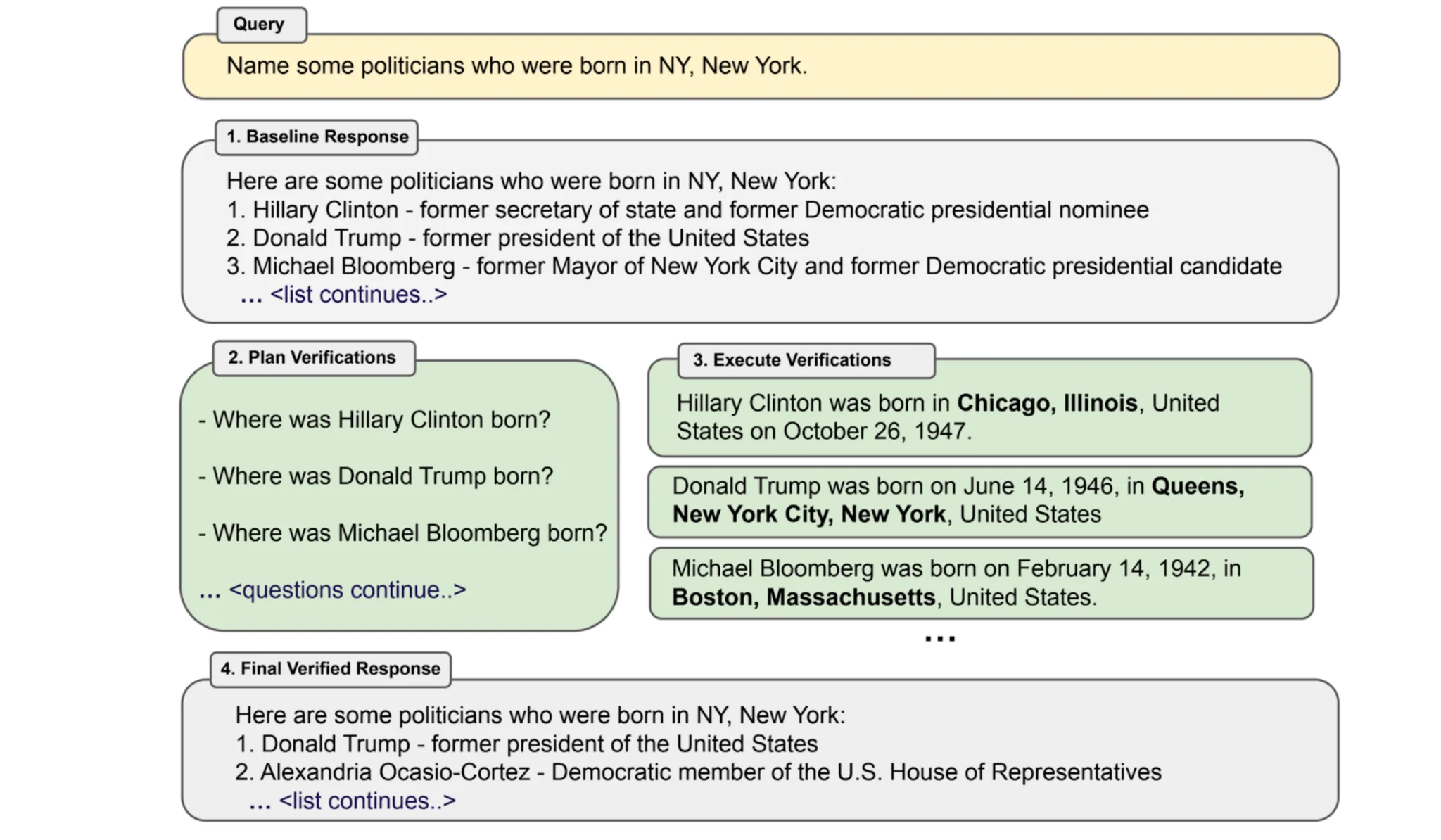
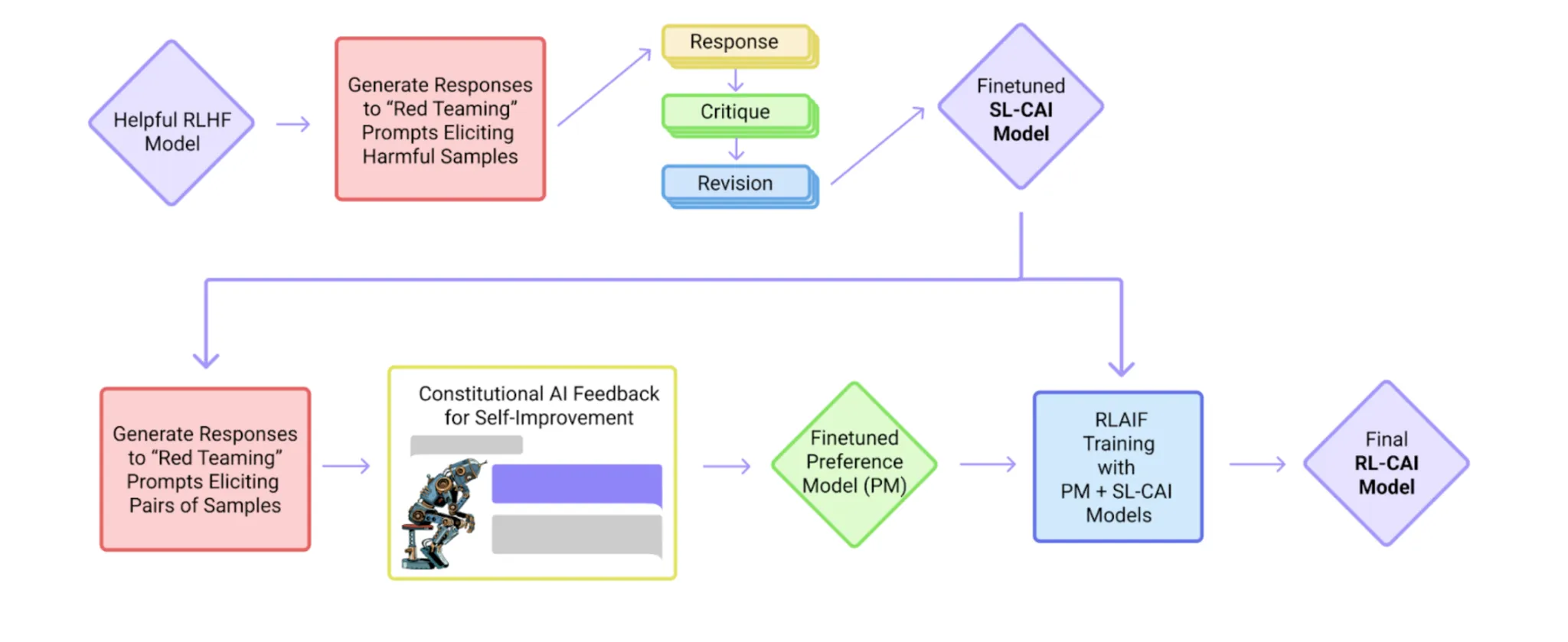
- Constitutional AI (Precept-Guided) describes a course of the place a mannequin critiques and revises its personal solutions utilizing a set of moral guidelines or guiding ideas (i.e. “structure”) to make them safer. The critiques and evaluations generated within the course of can be utilized to coach a reward mannequin and fine-tune the general assistant to turn into extra useful, much less dangerous, and hallucinate much less by using strategies like Reinforcement Studying with AI Suggestions (RLAIF).
Observe that the benefit right here is that we, as builders, solely want to offer high-level guiding ideas because the structure, and thru repeated revisions, the mannequin generates its personal fine-tuning dataset, which may be very useful in bettering the alignment of the ultimate system. Fairly magical!
Decoding approaches for tackling hallucinations
Congratulations when you have made it this far within the weblog! You might be actually keen about tackling hallucinations in LLMs. Technique to go! 😀
The entire approaches we mentioned up to now are associated to bettering the mannequin’s potential to cause via numerous techniques. Nevertheless, there’s a new wave of approaches that regulate the mannequin’s decoding course of to curtail hallucinations. We won’t be going into an excessive amount of element about these strategies as a result of it’s a subject for a weblog in itself. Let’s have a look at a few of these approaches on this part.
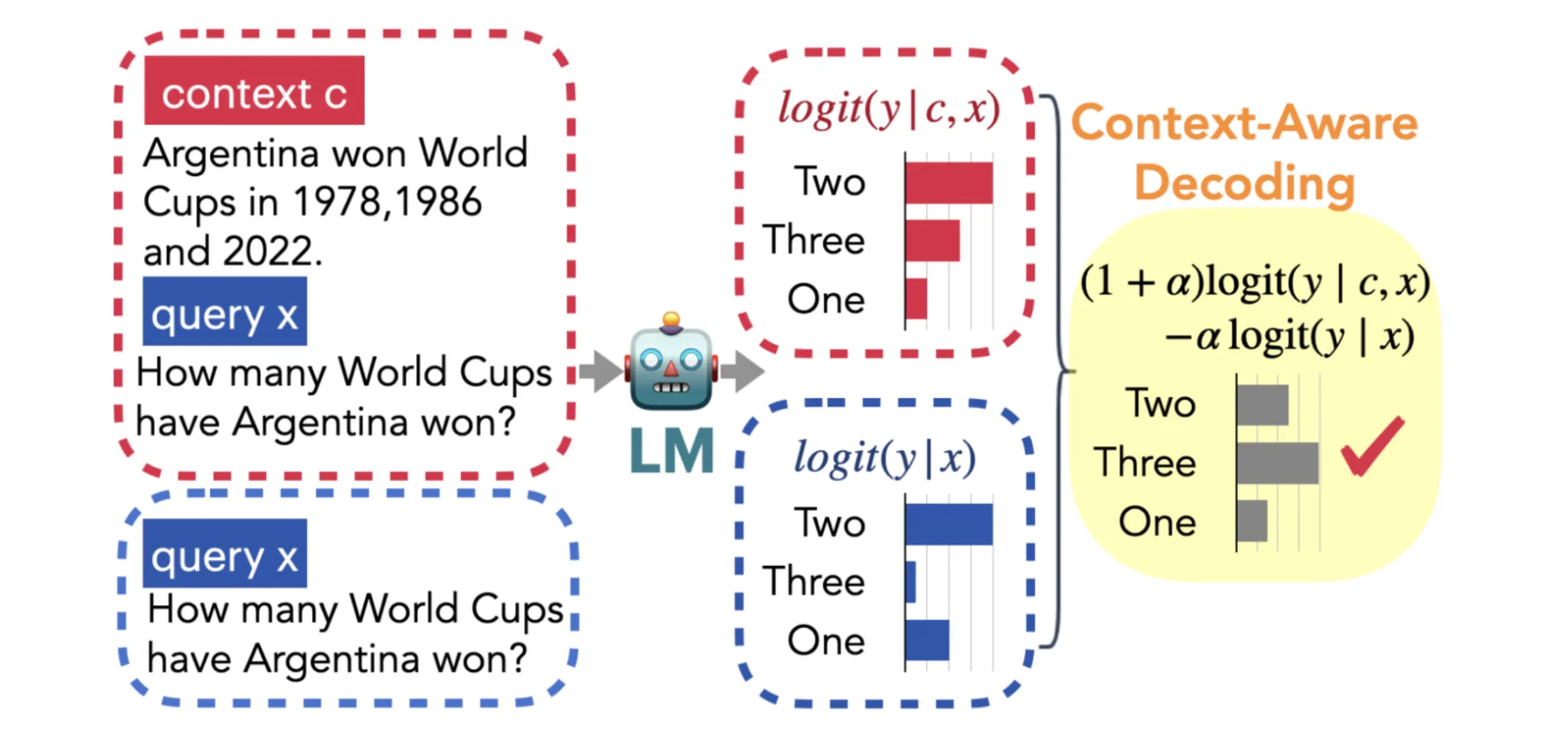
- Context-Conscious Decoding (CAD) is an fascinating methodology the place the identical LLM generates token-level logits twice: as soon as with the related context and as soon as with out it. The 2 units of logits are then mixed, assigning the next weight to the context-informed logits to emphasise context over the mannequin’s prior data. This guides the mannequin to provide outputs that higher mirror the brand new data, lowering hallucinations and bettering factual accuracy.
This methodology of evaluating or contrasting context and no-context outputs is what provides the strategy its title.
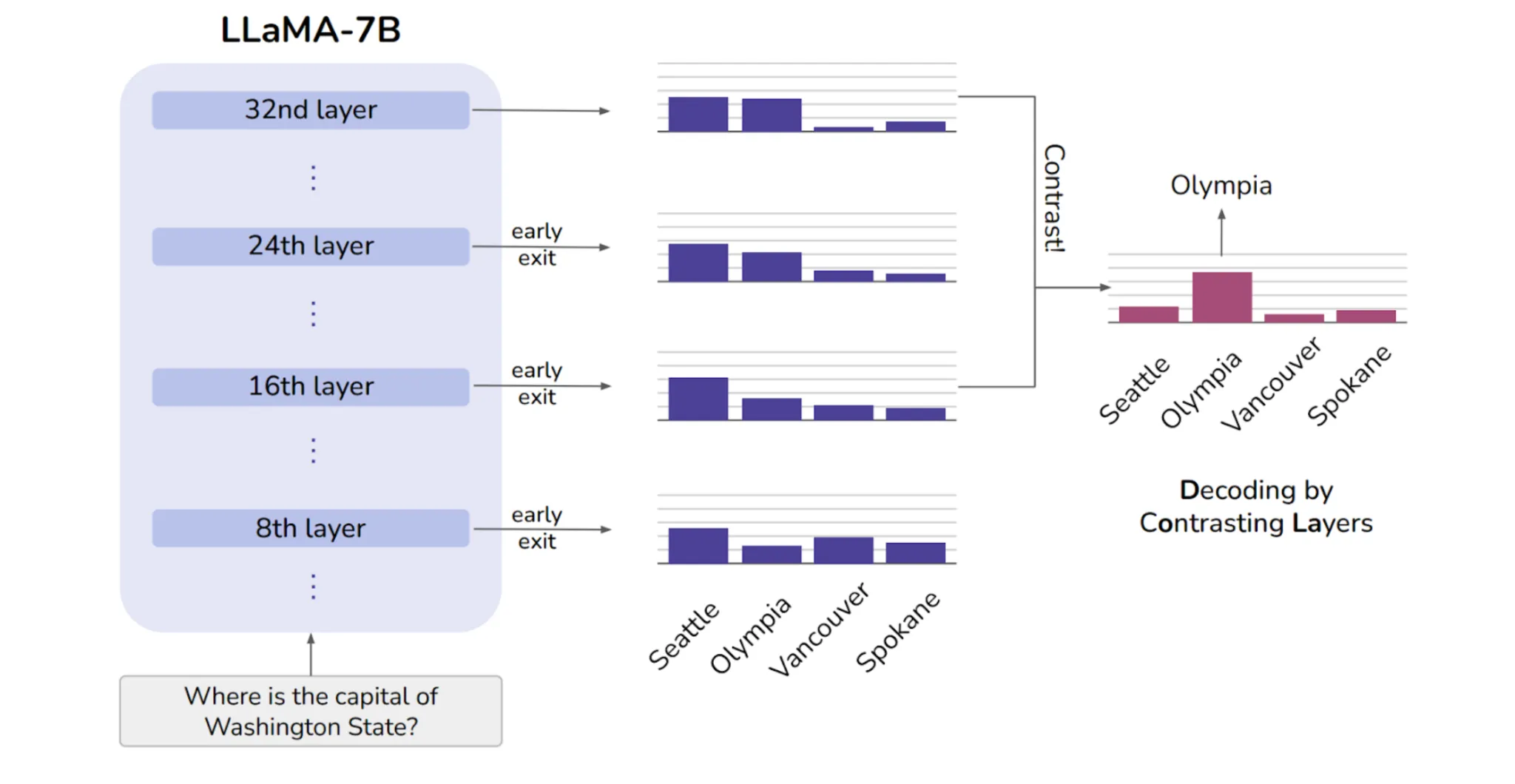
- Decoding by Contrasting Layers (DoLa) describes an strategy of contrasting logits from early and later transformer layers. The authors level out that decrease layers often seize primary, stylistic, and syntactic patterns, whereas larger or ‘mature’ layers maintain extra refined, factual, and semantic data. Utilizing this perception, their easy plug-and-play strategy improves truthfulness and cuts down hallucinations throughout benchmarks, all with out additional coaching or retrieval.
This paper is one in every of many in a brand new space of analysis for LLMs, which is called the mechanistic interpretability of LLMs.
Key Takeaways
That was a quite complete weblog publish. Nevertheless, I wished to cowl among the newest and coolest strategies round hallucinations in LLMs that assist me in my day-to-day work, and I’m glad I used to be in a position to take action.
Listed below are the important thing takeaways from the weblog:
- There’s “no single silver bullet” when coping with hallucinations in LLMs. Your finest wager is to compose strategies as per the necessity.
- It’s higher to start out with a easy strategy, resembling primary prompting or reasoning types like CoT. Then, steadily attempt to layer different approaches resembling RAG or ReAct/CoV/Reflexion for robustness. Strive one strategy totally earlier than going forward with one other.
- These approaches are useful in lowering hallucinations with out touching the mannequin. Nevertheless, nothing beats the age-old strategies of constantly evaluating your mannequin for hallucinations and updating its data base to maintain the contexts contemporary.
- Every time doubtful, your mannequin ought to abstain from responding if the stakes are excessive. It relies upon upon your actual downside assertion and enterprise use case.
- Immediate the mannequin in such a manner that it’s inspired to speak uncertainty clearly.
Sanad is a Senior AI Scientist at Analytics Vidhya, turning cutting-edge AI analysis into real-world Agentic AI merchandise. With an MS in Synthetic Intelligence from the College of Edinburgh, he’s labored at high analysis labs tackling multilingual NLP and NLP for low-resource Indian languages. Keen about all issues AI, he loves bridging the hole between deep analysis and sensible, impactful merchandise.
Login to proceed studying and luxuriate in expert-curated content material.

{kind=link}